详解Python如何实现批量为PDF添加水印
目录
- 准备环境
- 获得经销商名字对应的列表
- 生成水印PDF
- 合并水印与目标PDF
- 总结
我们有时候需要把一些机密文件发给多个客户,为了避免客户泄露文件,会在机密文件中添加水印。每个客户收到的文件内容相同,但是水印都不相同。这样一来,如果资料泄露了,通过水印就知道是从谁手上泄露的。
今天,一个做市场的朋友找我咨询PDF加水印的问题,如下图所示:
他有一个Excel文件,文件里面有10000个经销商的名字,他要把价目表PDF发给这些经销商,每个经销商收到的PDF文件上面的水印都是这个经销商自己的名字。
这个需求手动操作肯定要累死人。但是如果用Python来做,就非常简单。代码不超过30行。
准备环境
要完成这个需求,需要安装两个模块,分别叫做reportlab和pikepdf。使用Pip安装就可以了:
python3 -m pip install reportlab pikepdf
然后,需要找到一个.ttf或者.ttc格式的中文字体。你可以直接从网上下载中文字体文件。也可以使用系统自带的中文字体。这里以寻找macOS系统默认的宋体为例。
macOS系统字体在/System/Library/Fonts,宋体对应的.ttc文件地址是/System/Library/Fonts/Supplemental/Songti.ttc。对于系统默认的字体,我们只需要知道它的对应的文件名叫做Songti.ttc就可以了。如果是从网上下载的第三方字体,需要使用绝对路径或者相对于项目代码的相对路径。
获得经销商名字对应的列表
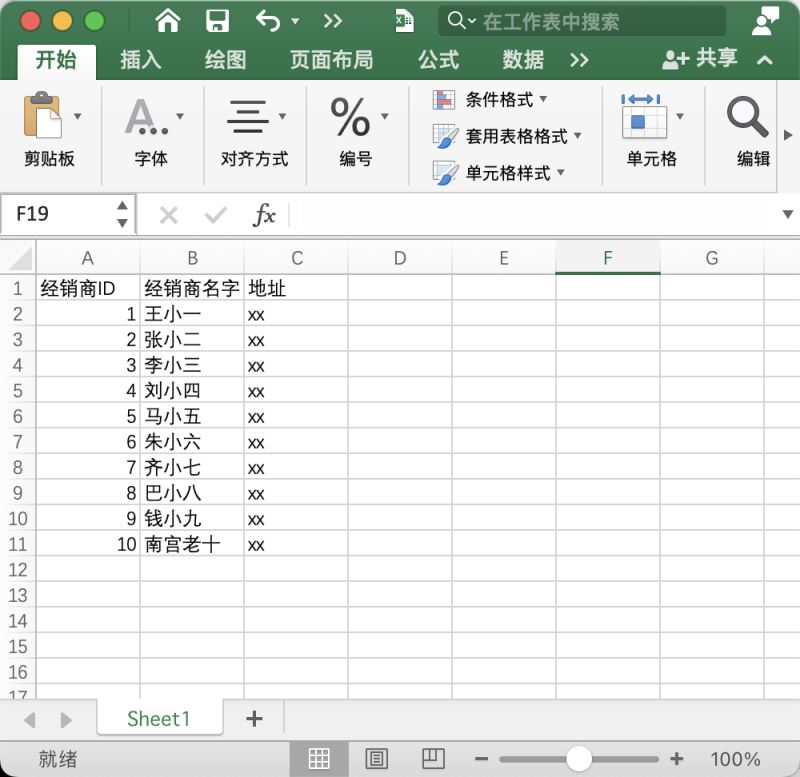
由于这位朋友不会使用pandas,那么我们就尽量使用Python原生的方法来获得经销商名字列表。假设经销商信息对应的Excel如下图所示:
我们首先把这个Excel文件导出成csv文件:
然后,我们用Python读取这个csv文件,获得经销商名字列表:
import csv
with open('经销商信息.csv') as f:
reader = csv.DictReader(f)
name_list = [x['经销商名字'] for x in reader]
print(name_list)
运行效果如下图所示:

生成水印PDF
一般来说,我们不能直接把一段文字作为水印添加到另一个PDF文件中。我们只有先把这段文字生成图片或者生成水印PDF文件,然后把这个图片或者水印PDF作为『图层』覆盖到目标PDF上面。
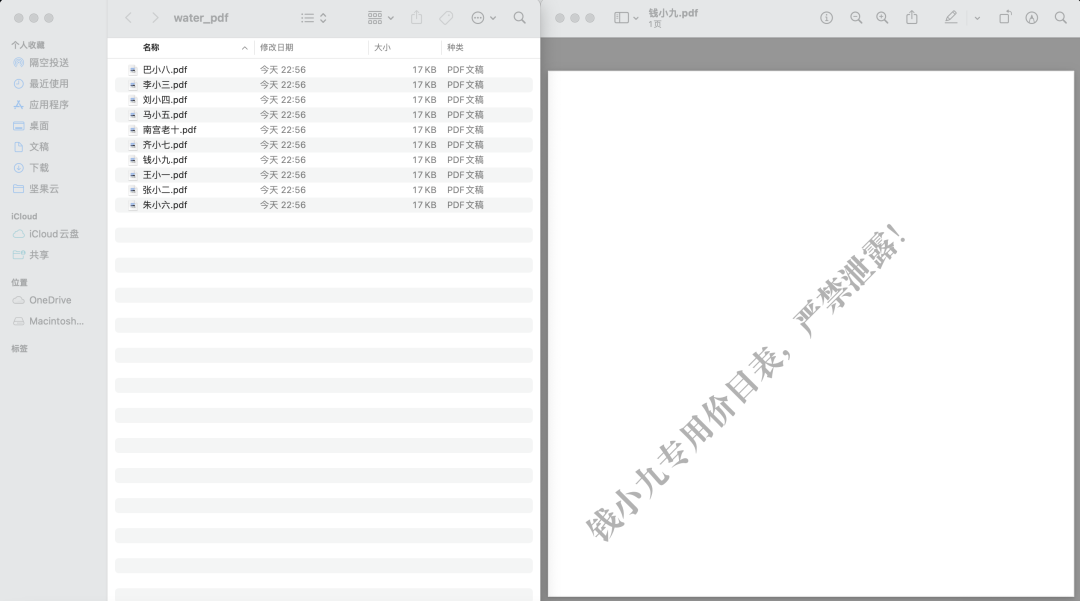
因此,现在需要给每一个经销商生成对应的水印PDF文件。这个PDF中只含有水印文字。效果如下图所示:
对应的代码create_watermark.py如下:
import csv
from pathlib import Path
from reportlab.lib import units
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
with open('经销商信息.csv') as f:
reader = csv.DictReader(f)
name_list = [x['经销商名字'] for x in reader]
pdfmetrics.registerFont(TTFont('Songti', 'Songti.ttc')) # 加载中文字体
water_mark_folder = Path('water_pdf') # 用一个文件夹存放所有的水印PDF
water_mark_folder.mkdir(exist_ok=True)
for name in name_list:
path = str(water_mark_folder / Path(f'{name}.pdf'))
c = canvas.Canvas(path, pagesize=(200 * units.mm, 200 * units.mm)) # 生成画布,长宽都是200毫米
c.translate(0.1 * 200 * units.mm, 0.1 * 200 * units.mm)
c.rotate(45) # 把水印文字旋转45°
c.setFont('Songti', 35) # 字体大小
c.setStrokeColorRGB(0, 0, 0) # 设置字体颜色
c.setFillColorRGB(0, 0, 0) # 设置填充颜色
c.setFillAlpha(0.3) # 设置透明度,越小越透明
c.drawString(0, 0, f'{name}专用价目表,严禁泄露!')
c.save()
代码的具体作用,已经写到注释中了。运行以后会在当前项目根目录生成water_pdf文件夹,里面就是生成的水印PDF。
合并水印与目标PDF
最后一步,把每一个经销商的水印PDF与目标PDF进行合并。水印PDF作为一个图层覆盖到目标PDF上面。
使用pikepdf完成这个工作非常简单,编写一个combine.py文件,代码如下:
import glob
from pathlib import Path
from pikepdf import Pdf, Page, Rectangle
water_pdf_list = glob.glob('water_pdf/*.pdf')
result = Path('result')
result.mkdir(exist_ok=True)
col = 2 # 每页多少列水印
row = 3 # 每页多少行水印
for path in water_pdf_list:
target = Pdf.open('./PythonisinstanceGolang.pdf') # 必须每次重新打开PDF,因为添加水印是inplace的操作
file = Path(path)
name = file.stem
water_mark_pdf = Pdf.open(path)
water_mark = water_mark_pdf.pages[0]
for page in target.pages:
for x in range(col): # 每一行显示多少列水印
for y in range(row): # 每一页显示多少行PDF
page.add_overlay(water_mark,
Rectangle(page.trimbox[2] * x / col,
page.trimbox[3] * y / row,
page.trimbox[2] * (x + 1) / col,
page.trimbox[3] * (y + 1) / row))
result_name = Path('result', f'{name}_添加水印.pdf')
target.save(str(result_name))
运行以后,会在项目根目录生成一个result文件夹,里面就是添加了水印的PDF文件了,如下图所示:
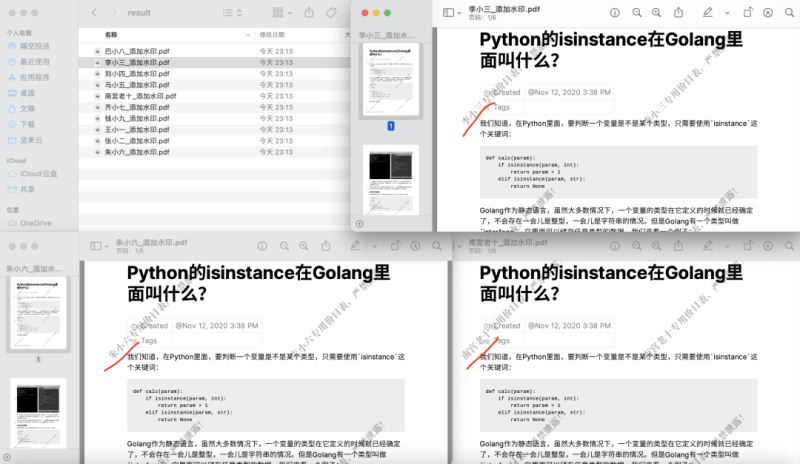
这里有必要对代码中的一些地方进行解释。带上行号的代码如下图所示:
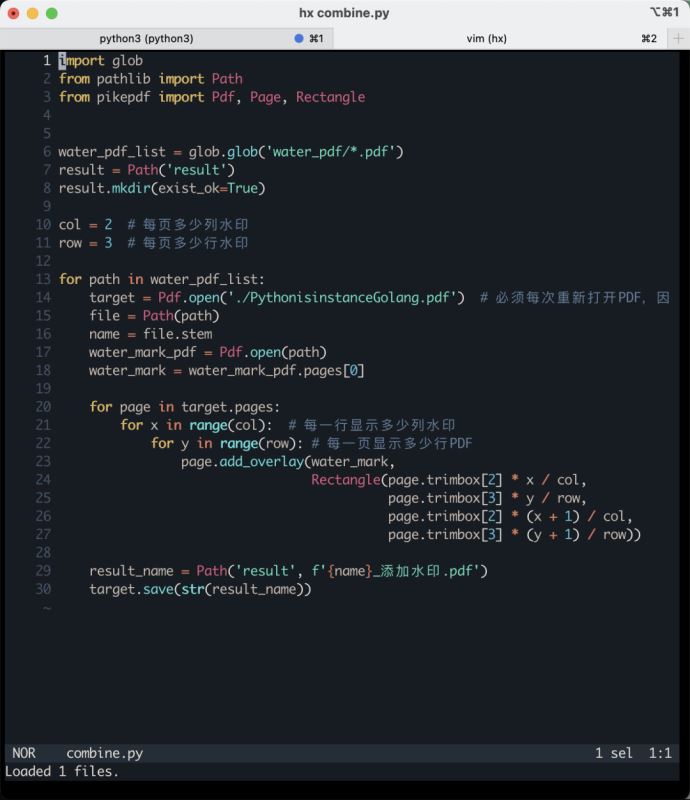
代码第21行和22行,有两个for循环,他们的作用是给一个页面上添加多个水印。请大家注意下图我画圈的地方:

每一页都有6个水印,分成3行2列。其中的3行对应了变量row的值。2列对应了变量col的值。大家也可以根据自己的需要修改这两个数字。甚至每一页的水印随机变换位置,防止被去水印的程序移除。
page.trimbox[2]是PDF页面的宽度,page.trimbox[3]是PDF页面的高度。
总结
大家注意在这篇文章中,我把任务分成了3个部分,分别是:
- Excel转CSV,让Python方便读取
- Python读取CSV生成水印PDF
- 水印PDF与目标PDF文件合并
这三个部分的代码是可以合并在一个.py文件里面的,但是我没有这样做,是考虑到问这个问题的同学不是程序员,Python水平只是入门,如果合并在一起,代码量多了以后,出问题都不知道错在哪里。
在计算机领域,所有问题都可以通过把问题拆分成多个部分分别单独运行或者增加若干个中间层来解决。今天用的方法就是把问题拆分的方法。对于初学者来说,每一步都是相对独立的,都能立刻看到效果。第二步只需要依赖第一步的结果,第三步只需要依赖第二步的结果,这样每一步的输入输出非常清楚,可以显著降低问题的复杂度。如果报错了,也更容易知道是哪个地方有问题。
到此这篇关于详解Python如何实现批量为PDF添加水印的文章就介绍到这了,更多相关Python PDF添加水印内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现为pdf添加水印功能
目录 创建需要的水印模板 wps创建 输出pdf 水印pdf 实现步骤 安装依赖 代码 问题 使用pypdf2出现编码问题 解决方法 感悟 创建需要的水印模板 wps创建 输出pdf 水印pdf 实现步骤 安装依赖 pip install PyPDF2 代码 import os from PyPDF2 import PdfFileReader as pr from PyPDF2 import PdfFileWriter as pw def write_watermark(watermark_pd
-
2行Python代码实现给pdf文件添加水印
目录 1. 引言 2.指定水印内容输出到pdf文件 2.1 模块安装 2.2 思路 2.3 代码示例 3.水印内容批量输出到pdf文件 3.1 模块安装 3.2 思路 3.3 代码示例 4.总结 1. 引言 小屌丝:鱼哥,新年快乐! 小鱼:无事不登三宝殿,有啥事,你直说吧… 小屌丝:别说的这么直接,这大过年的… 小鱼:别整没用的,就你那点小心思,我还能不知道. 小屌丝:… 小屌丝:鄙视就鄙视,只要能帮我解决问题,我然你鄙视三连! 小鱼:…还可以这样,那你说吧,啥事? 小屌丝:就是…就是… 小鱼:
-
Python去除PDF水印的实现示例
今天介绍下用 Python 去除 PDF (图片)的水印.思路很简单,代码也很简洁. 首先来考虑 Python 如何去除图片的水印,然后再将思路复用到 PDF 上面. 这张图片是前几天整理<数据结构和算法>PDF里的一个截图,带着公众号的水印. 从上图可以明显看到,为了不影响阅读正文,水印颜色一般比较浅.因此,我们可以利用颜色差这个特征来去掉水印.即:用 Python 读取图片的颜色,并将浅颜色部分变白. Python 标准库 PIL 可以获取图片的颜色,Python2 是系统自带的,Pyth
-
Python实现为PDF去除水印的示例代码
目录 前言 原理 特色 成果 安装依赖 代码 想法 前言 为什么做出这个? 就是有时候从网上下载的资料中的pdf有水印,看着不舒服. 比如说我从网上下载的试卷,然后去打印店打印,打印之后水印看着很不舒服,而去水印wps要会员,而我是一个程序员,为什么不做一个呢,何乐而不为. 虽然最后是做出来的,但是还是有限制. 原理 把pdf转化为图片,然后将图片去水印. 图片去水印,是又条件限制的,必须水印的颜色和pdf中文字的颜色的rgb相差很大,然后把水印的颜色改变成背景颜色. 特色 网上很多和我类似的原
-
Python实现批量向PDF文件添加中文水印
目录 前言 实现步骤 完整代码 前言 可以通过设置批量PDF文件所在的路径及需要添加的水印名称可以实现批量添加PDF水印的效果. 实现思路是这样的,通过在批量PDF文件路径下面生成一个带有水印的PDF模板.最后,将批量文件的每个PDF页面和水印模板进行合并完成批量添加水印的效果. 需要注意的是批量PDF文件必须和PDF模板水印文件的大小尺寸保持一致,这个可以在代码里面调节一下就成了. 实现步骤 首先将需要添加水印的PDF文件准备好放在一个文件夹下面. 在代码中设置好PDF批量文件的路径及水印名称
-
Python实现给PDF添加水印的方法
前言 利用 PyPDF2 处理 PDF 文件,相关文档:https://pythonhosted.org/PyPDF2/ 本文针对 仅有 PDF 文件,而无相关 PDF 编辑器的情况下,给 PDF 添加水印. 一.前期准备 安装 PyPDF2 ,命令提示框输入: pip install PyPDF2 新建 watermark.pdf 文件 实际的水印,可以在此文件里修改水印文字的字体和位置. 实现步骤: 新建 watermark.word ,[设计] → \to → [水印][自定义水印] →
-
详解Python如何实现批量为PDF添加水印
目录 准备环境 获得经销商名字对应的列表 生成水印PDF 合并水印与目标PDF 总结 我们有时候需要把一些机密文件发给多个客户,为了避免客户泄露文件,会在机密文件中添加水印.每个客户收到的文件内容相同,但是水印都不相同.这样一来,如果资料泄露了,通过水印就知道是从谁手上泄露的. 今天,一个做市场的朋友找我咨询PDF加水印的问题,如下图所示: 他有一个Excel文件,文件里面有10000个经销商的名字,他要把价目表PDF发给这些经销商,每个经销商收到的PDF文件上面的水印都是这个经销商自己的名字.
-
详解Python如何批量采集京东商品数据流程
目录 准备工作 驱动安装 模块使用与介绍 流程解析 完整代码 效果展示 准备工作 驱动安装 实现案例之前,我们要先安装一个谷歌驱动,因为我们是使用selenium 操控谷歌驱动,然后操控浏览器实现自动操作的,模拟人的行为去操作浏览器. 以谷歌浏览器为例,打开浏览器看下我们自己的版本,然后下载跟自己浏览器版本一样或者最相近的版本,下载后解压一下,把解压好的插件放到我们的python环境里面,或者和代码放到一起也可以. 模块使用与介绍 selenium pip install selenium ,直
-
详解Python如何批量检查图像是否可用
数据集中的图像,一般不可用在以下3个方面: 1.图像过小 2.无法打开 3.“Premature end of JPEG file” 这些图像可能会导致模型的学习异常,因此,使用多进程检查数据集中的每张图像,是很有必要的. 具体逻辑如下: 遍历文件夹,多进程处理每一张图像 判断图像是否可读,是否支持resize尺寸,边长是否满足 判断JPG图像是否Premature end 删除错误图像 脚本如下: #!/usr/bin/env python # -- coding: utf-8 -- "&qu
-
详解python实现多张多格式图片转PDF并打包成exe
目录 转PDF初始代码 转PDF最终代码 GUI界面设计代码 打包成可执行文件 完整代码 附录 转PDF初始代码 从文件夹中读取图片数据,然后将他们保存为PDF格式. 不长,大概10行代码. from PIL import Image from os import * def PictureToPDF(picture_path, name): pictures = [] picture_file = listdir(picture_path) for file in picture_file:
-
详解Python自动化之文件自动化处理
一.生成随机的测验试卷文件 假如你是一位地理老师, 班上有 35 名学生, 你希望进行美国各州首府的一个小测验.不妙的是,班里有几个坏蛋, 你无法确信学生不会作弊.你希望随机调整问题的次序, 这样每份试卷都是独一无二的, 这让任何人都不能从其他人那里抄袭答案.当然,手工完成这件事又费时又无聊. 下面是程序所做的事: • 创建 35 份不同的测验试卷. • 为每份试卷创建 50 个多重选择题,次序随机. • 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机. • 将测验试卷写到 35
-
详解Python+opencv裁剪/截取图片的几种方式
前言 在计算机视觉任务中,如图像分类,图像数据集必不可少.自己采集的图片往往存在很多噪声或无用信息会影响模型训练.因此,需要对图片进行裁剪处理,以防止图片边缘无用信息对模型造成影响.本文介绍几种图片裁剪的方式,供大家参考. 一.手动单张裁剪/截取 selectROI:选择感兴趣区域,边界框框选x,y,w,h selectROI(windowName, img, showCrosshair=None, fromCenter=None): . 参数windowName:选择的区域被显示在的窗口的名字
-
详解Python中的进程和线程
进程是什么? 进程就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成.我们编写的程序用来描述进程要完成哪些功能以及如何完成:数据集则是程序在执行过程中所需要使用的资源:进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志. 线程是什么? 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID.程序计数器.寄存器集合和堆栈共同组成.线程的引入减小了程序并发
-
详解Python如何利用Pandas与NumPy进行数据清洗
目录 准备工作 DataFrame 列的删除 DataFrame 索引更改 DataFrame 数据字段整理 str 方法与 NumPy 结合清理列 apply 函数清理整个数据集 DataFrame 跳过行 DataFrame 重命名列 许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式. 因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值.不一致的格式.格式错误的记录还是无意义的异常
-
详解Python中enumerate函数的使用
Python 的 enumerate() 函数就像是一个神秘的黑箱,你无法简单地用一句话来概括这个函数的作用与用法. enumerate() 函数属于非常有用的高级用法,而对于这一点,很多初学者甚至中级学者都没有意识到.这个函数的基本应用就是用来遍历一个集合对象,它在遍历的同时还可以得到当前元素的索引位置. 我们看一个例子: names = ["Alice","Bob","Carl"] for index,value in enumerate(n
-
一文详解Python灰色预测模型实现示例
目录 前言 一.模型理论 特点 二.模型场景 1.预测种类 2.适用条件 三.建模流程 1.级比校验 3.系数求解 4.残差检验与级比偏差检验 四.Python实例实现 总结 前言 博主参与过大大小小十次数学建模比赛,也获得了不少建模奖项.对于一些小批量样本数据去做预测或者是评估其规律性的话,比较适合的模型一般都是选择灰色预测模型.该模型解释性强而且易于理解,建模手段也比较简单.在一些不确定是否存在相关标量或者是存在位置特征的时候,用灰色预测模型尤为明显,牵扯太多变量时候可以以量曾量减的方式显现