浅谈pandas筛选出表中满足另一个表所有条件的数据方法
今天记录一下pandas筛选出一个表中满足另一个表中所有条件的数据。例如:
list1 结构:名字,ID,颜色,数量,类型。
list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']]
list2结构:名字,类型,颜色。
list2 = [['a','03',255],['a','06',481]]
如何在list1中找出所有与list2中匹配的元素?要得到下面的结果:list = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03']]。
首先将两个list转化为dataframe.
list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] df1=pd.DataFrame(list1,columns=["名字","ID","颜色","数量","类型"]) list2 = [['a','03',255],['a','06',481]] df2=pd.DataFrame(list2,columns=["名字","类型","颜色"])
数据结构如下:

然后利用pandas.merge函数将其进行内连接。
这个函数的语法是:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)。这函数连接方式和sql的连接类似,由参数how来控制。
最后的代码如下:
import pandas as pd list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] df1=pd.DataFrame(list1,columns=["名字","ID","颜色","数量","类型"]) list2 = [['a','03',255],['a','06',481]] df2=pd.DataFrame(list2,columns=["名字","类型","颜色"]) df=pd.merge(df1,df2,how='inner',on=["名字","类型","颜色"],right_index=True) df.sort_index(inplace=True) print(df)
返回结果按照左表的顺序输出:
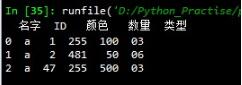
以上这篇浅谈pandas筛选出表中满足另一个表所有条件的数据方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python实现的根据文件名查找数据文件功能示例
本文实例讲述了Python实现的根据文件名查找数据文件功能.分享给大家供大家参考,具体如下: #-*- coding: UTF-8 -*- import os import shutil AllFiles=[] NameFiles=[] def findFie(filePath): pathDir = os.listdir(filePath) for allDir in pathDir: # print(allDir) AllFiles.append(allDir) #pass #filepat
-
pandas按若干个列的组合条件筛选数据的方法
还是用图说话 A文件: 比如,我想筛选出"设计井别"."投产井别"."目前井别"三列数据都为11的数据,结果如下: 当然,这里的筛选条件可以根据用户需要自由调整,代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.c
-
pandas实现将dataframe满足某一条件的值选出
在读取数据的时候发现,想把数据中第六列含问号的数据挑出来 import pandas as pd data = pd.read_table('breast-cancer-wisconsin.data.txt',header=None,encoding='gb2312',sep=',') data = data.drop(0, axis=1) data = data[data[6] != '?'] 以上这篇pandas实现将dataframe满足某一条件的值选出就是小编分享给大家的全部内容了,希望
-
python 实现查找文件并输出满足某一条件的数据项方法
python 实现文件查找和某些项输出 本文是基于给定一文件(students.txt),查找其中GPA分数最高的 输出,同时输出其对应的姓名和学分 一. 思路 首先需要打开文件,读取文件的每一行,将姓名,学分,GPA值分别存到三个对应的列表中,对于GPA列表进行遍历,获取其中值最大的一项,但是需要保存最大值对应的索引,方便输出对应的姓名和学分项 二. 代码 版本1 # -*- coding: utf-8 -*- """ Created on Thu Feb 1 12:24:
-
用Python实现筛选文件脚本的方法
在做项目时遇到需要标记数据集里面的若干图片数据,作为程序员,为避免手动一张一张的筛选,所以写了这个Python脚本实现. Python脚本如下: # from PIL import Image import csv import os import shutil filename = 'img.txt' def readImageName(): with open(filename) as f: lines = f.readlines() imgnames = [] for line in li
-
浅谈pandas筛选出表中满足另一个表所有条件的数据方法
今天记录一下pandas筛选出一个表中满足另一个表中所有条件的数据.例如: list1 结构:名字,ID,颜色,数量,类型. list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] list2结构:名字,类型,颜色. list2 = [['a','03',255],['a','06',481]] 如何在list1中找出所有与list2中匹配的元素?要得到下面的结果:lis
-
浅谈如何在bat文件中调用另一个bat文件
目录 情景一:两个bat文件在同一个目录下 情景二:两个bat文件不在同一个目录下 情景三:开启一个新的cmd窗口来运行另一个bat文件 情景一:两个bat文件在同一个目录下 有时候我们需要在一个bat文件中调用另一个bat文件,比如我们想在a.bat中调用b.bat,如下. a.bat @echo off echo I am a.bat- echo now run the b.bat call b.bat echo over b.bat @echo off echo I am b.bat- 在
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
浅谈pandas中DataFrame关于显示值省略的解决方法
python的pandas库是一个非常好的工具,里面的DataFrame更是常用且好用,最近是越用越觉得设计的漂亮,pandas的很多细节设计的都非常好,有待使用过程中发掘. 好了,发完感慨,说一下最近DataFrame遇到的一个细节: 在使用DataFrame中有时候会遇到表格中的value显示不完全,像下面这样: In: import pandas as pd longString = u'''真正的科学家应当是个幻想家:谁不是幻想家,谁就只能把自己称为实践家.人生的磨难是很多的, 所以我们
-
浅谈Pandas中map, applymap and apply的区别
1.apply() 当想让方程作用在一维的向量上时,可以使用apply来完成,如下所示 In [116]: frame = DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon']) In [117]: frame Out[117]: b d e Utah -0.029638 1.081563 1.280300 Ohio 0.647747 0.831136 -1.
-
浅谈Pandas Series 和 Numpy array中的相同点
相同点: 可以利用中括号获取元素 s[0] 可以的得到单个元素 或 一个元素切片 s[3,7] 可以遍历 for x in s 可以调用同样的函数获取最大最小值 s.mean() s.max() 可以用向量运算 <1 + s> 和Numpy一样, Pandas Series 也是用C语言, 因此它比Python列表的运算更快 以上这篇浅谈Pandas Series 和 Numpy array中的相同点就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
浅谈pandas中shift和diff函数关系
通过?pandas.DataFrame.shift命令查看帮助文档 Signature: pandas.DataFrame.shift(self, periods=1, freq=None, axis=0) Docstring: Shift index by desired number of periods with an optional time freq 该函数主要的功能就是使数据框中的数据移动,若freq=None时,根据axis的设置,行索引数据保持不变,列索引数据可以在行上上下移动
-
浅谈pandas用groupby后对层级索引levels的处理方法
层及索引levels,刚开始学习pandas的时候没有太多的操作关于groupby,仅仅是简单的count.sum.size等等,没有更深入的利用groupby后的数据进行处理.近来数据处理的时候有遇到这类问题花了一点时间,所以这里记录以及复习一下:(以下皆是个人实践后的理解) 我使用一个实例来讲解下面的问题:一张数据表中有三列(动物物种.物种品种.品种价格),选出每个物种从大到小品种的前两种,最后只需要品种和价格这两列. 以上这张表是我们后面需要处理的数据表 (物种 品种 价格) levels
-
浅谈pandas dataframe对除数是零的处理
如下例 data2['营业成本率'] = data2['营业成本本年累计']/data2['营业收入本年累计']*100 但有营业收入本年累计为0的情况, 则营业成本率为inf,即无穷大,而需要在表中体现为零,用如下方法填充: data2['营业成本率'] = data2['营业成本本年累计']/data2['营业收入本年累计']*100 data2['营业成本率'].replace([np.inf, -np.inf, "", np.nan], 0, inplace=True) 当然,
-
浅谈C++ 类的实例中 内存分配详解
一个类,有成员变量:静态与非静态之分:而成员函数有三种:静态的.非静态的.虚的. 那么这些个东西在内存中到底是如何分配的呢? 以一个例子来说明: #include"iostream.h" class CObject { public: static int a; CObject(); ~CObject(); void Fun(); private: int m_count; int m_index; }; VoidCObject::Fun(){ cout<<"Fu
随机推荐
- PHP Web木马扫描器代码分享
- jquery如何判断某元素是否具备指定的样式
- servlet简介_动力节点Java学院整理
- java明文密码三重加密方法
- dedecms5.5 最新版ckeditor编辑器整合教程
- python复制与引用用法分析
- mysql 5.7更改数据库的数据存储位置的解决方法
- bootstrap模态框消失问题的解决方法
- 使用JQuery库提供的扩展功能实现自定义方法
- JQuery中根据属性或属性值获得元素(6种情况获取方法)
- Android开发之利用jsoup解析HTML页面的方法
- php验证码的制作思路和实现方法
- php中JSON的使用方法
- python使用正则表达式替换匹配成功的组并输出替换的次数
- C#中的多线程超时处理实践方案
- Windows10下mysql 8.0.12解压版安装配置方法图文教程
- python实现大文件分割与合并
- Python在Matplotlib图中显示中文字体的操作方法
- Django之使用celery和NGINX生成静态页面实现性能优化
- python+pygame简单画板实现代码实例