oracle自动巡检脚本生成html报告的方法
一、 前言
1、由于每月月底都需要对一些oracle数据库环境进行一些简单的巡检,而通过运行一条条语句,并依依去截图保存到word文档中效率低下,所以这里我就将手工巡检过程编写成shell脚本来提高巡检效率,同时也免去了截图照片图片不清晰的问题。
2、脚本简单容易二次编辑,本文仅提供简单巡检的事项,如数据表空间是否自动扩展、是否开启归档等,大家根据实际需要编辑修改,增加符合自己公司需求的巡检报告。
3、项目已经上传到我的github上
项目地址:orawatch.git
二、注意事项与报告部分截图
一定注意阅读git上的README.md说明,避免 system 用户被锁定。
三、README.md
1、需要使用oracle用户执行
2、使用说明
1)、多实例下运行此脚本:
声明实例名;执行时跟上此实例对应的 system 密码
$ export ORACLE_SID=orcl $ chmod +x orawatch.sh $ ./orawatch.sh system/yourpassword
或者是将此实例对应的 system 密码填写到脚本中,随后执行
$ vi orawatch.sh sqlstr="system/system" $ chmod +x orawatch.sh $ ./orawatch.sh
2)、请注意一定要将对应实例名的对应system密码填写至脚本如下位置,或是执行时跟上对应实例的system密码,否则将造成 system 用户因密码错误而被锁定
system用户解锁语句:
SQL> alter user system account unlock; alter user system identified by yourpassword;
3、执行完巡检之后,将在脚本所在的路径下生成html巡检结果报告,如下
192.168.35.244os_oracle_summary.html
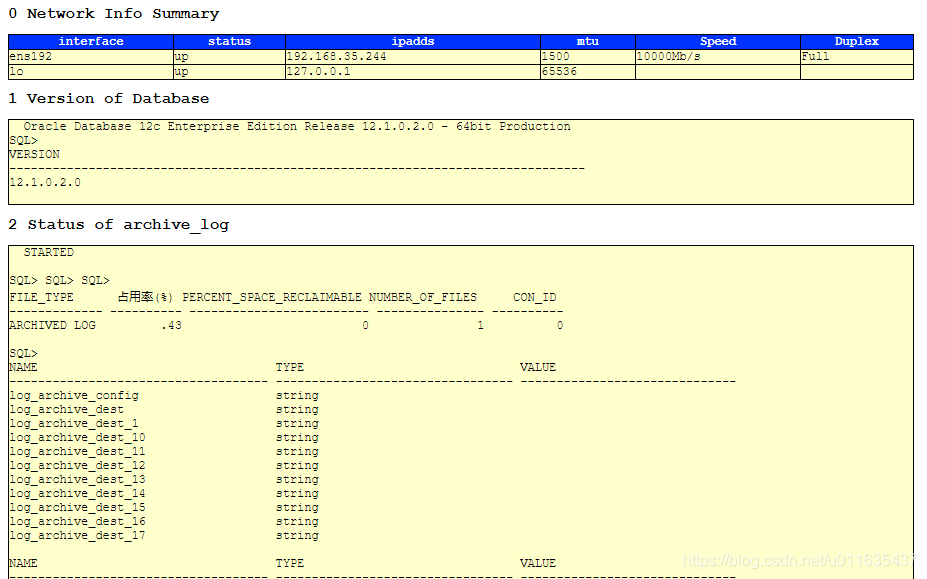
4、巡检项信息如下(其他统计项可根据实际需要自行添加)
0)、巡检ip信息
1)、数据库版本
2)、是否开启归档,及归档磁盘占用率与路径信息
3)、数据库memory/sga/pga信息
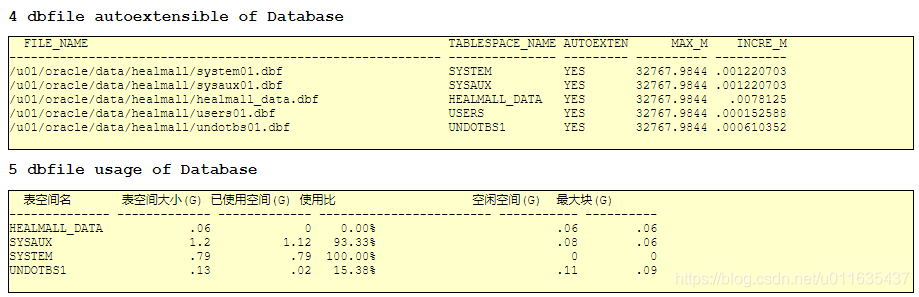
4)、数据表空间是否自动扩展
5)、数据库当前分配的数据表空间使用率信息
四、脚本内容
#!/bin/bash
# script_name: orawatch.sh
# Author: Danrtsey.Shun
# Email:mydefiniteaim@126.com
# usage:
# chmod +x orawatch.sh
# export ORACLE_SID=orcl
# ./orawatch.sh system/yourpassword
ipaddress=`ip a|grep "global"|awk '{print $2}' |awk -F/ '{print $1}'`
file_output=${ipaddress}'os_oracle_summary.html'
td_str=''
th_str=''
sqlstr=$1
test $1
if [ $? = 1 ]; then
echo
echo "Info...You did not enter a value for sqlstr."
echo "Info...Using default value = system/system"
sqlstr="system/system"
fi
export NLS_LANG='american_america.AL32UTF8'
#yum -y install bc sysstat net-tools
create_html_css(){
echo -e "<html>
<head>
<style type="text/css">
body {font:12px Courier New,Helvetica,sansserif; color:black; background:White;}
table,tr,td {font:12px Courier New,Helvetica,sansserif; color:Black; background:#FFFFCC; padding:0px 0px 0px 0px; margin:0px 0px 0px 0px;}
th {font:bold 12px Courier New,Helvetica,sansserif; color:White; background:#0033FF; padding:0px 0px 0px 0px;}
h1 {font:bold 12pt Courier New,Helvetica,sansserif; color:Black; padding:0px 0px 0px 0px;}
</style>
</head>
<body>"
}
create_html_head(){
echo -e "<h1>$1</h1>"
}
create_table_head1(){
echo -e "<table width="68%" border="1" bordercolor="#000000" cellspacing="0px" style="border-collapse:collapse">"
}
create_table_head2(){
echo -e "<table width="100%" border="1" bordercolor="#000000" cellspacing="0px" style="border-collapse:collapse">"
}
create_td(){
td_str=`echo $1 | awk 'BEGIN{FS="|"}''{i=1; while(i<=NF) {print "<td>"$i"</td>";i++}}'`
}
create_th(){
th_str=`echo $1|awk 'BEGIN{FS="|"}''{i=1; while(i<=NF) {print "<th>"$i"</th>";i++}}'`
}
create_tr1(){
create_td "$1"
echo -e "<tr>
$td_str
</tr>" >> $file_output
}
create_tr2(){
create_th "$1"
echo -e "<tr>
$th_str
</tr>" >> $file_output
}
create_tr3(){
echo -e "<tr><td>
<pre style=\"font-family:Courier New; word-wrap: break-word; white-space: pre-wrap; white-space: -moz-pre-wrap\" >
`cat $1`
</pre></td></tr>" >> $file_output
}
create_table_end(){
echo -e "</table>"
}
create_html_end(){
echo -e "</body></html>"
}
NAME_VAL_LEN=12
name_val () {
printf "%+*s | %s\n" "${NAME_VAL_LEN}" "$1" "$2"
}
get_netinfo(){
echo "interface | status | ipadds | mtu | Speed | Duplex" >>/tmp/tmpnet_h1_`date +%y%m%d`.txt
for ipstr in `ifconfig -a|grep ": flags"|awk '{print $1}'|sed 's/.$//'`
do
ipadds=`ifconfig ${ipstr}|grep -w inet|awk '{print $2}'`
mtu=`ifconfig ${ipstr}|grep mtu|awk '{print $NF}'`
speed=`ethtool ${ipstr}|grep Speed|awk -F: '{print $2}'`
duplex=`ethtool ${ipstr}|grep Duplex|awk -F: '{print $2}'`
echo "${ipstr}" "up" "${ipadds}" "${mtu}" "${speed}" "${duplex}"\
|awk '{print $1,"|", $2,"|", $3,"|", $4,"|", $5,"|", $6}' >>/tmp/tmpnet1_`date +%y%m%d`.txt
done
}
ora_base_info(){
echo "######################## 1.数据库版本"
echo "select ' ' as \"--1.Database Version\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_base_`date +%y%m%d`.txt
echo "Select version FROM Product_component_version Where SUBSTR(PRODUCT,1,6)='Oracle';" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_base_`date +%y%m%d`.txt
}
ora_archive_info(){
echo "######################## 2.归档状态"
echo "select ' ' as \"--2.DB Archive Mode\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_archive_`date +%y%m%d`.txt
echo "select archiver from v\$instance;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_archive_`date +%y%m%d`.txt
sed -i '33!d' /tmp/tmpora_archive_`date +%y%m%d`.txt
archive_string=`cat /tmp/tmpora_archive_\`date +%y%m%d\`.txt`
if [ $archive_string = STARTED ];then
echo "set linesize 333;
col FILE_TYPE for a13;
select FILE_TYPE,PERCENT_SPACE_USED as \"占用率(%)\",PERCENT_SPACE_RECLAIMABLE,NUMBER_OF_FILES,CON_ID from v\$flash_recovery_area_usage where FILE_TYPE = 'ARCHIVED LOG';
show parameter log_archive;
col NAME for a40;
col 已使用空间 for a13;
select NAME,SPACE_LIMIT/1024/1024 as \"最大空间(M)\",SPACE_USED/1024/1024 as \"已使用空间(M)\",SPACE_RECLAIMABLE,NUMBER_OF_FILES,CON_ID from v\$recovery_file_dest;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_archive_`date +%y%m%d`.txt
for i in `seq 2`; do sed -i '$d' /tmp/tmpora_archive_`date +%y%m%d`.txt ; done
fi
}
ora_mem_info(){
echo "######################## 3.1 内存参数memory"
echo "select ' ' as \"--3.1.DB memory\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_mem_`date +%y%m%d`.txt
echo "set line 2500;
show parameter memory;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_mem_`date +%y%m%d`.txt
}
ora_sga_info(){
echo "######################## 3.2 内存参数sga"
echo "select ' ' as \"--3.2.DB sga\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_sga_`date +%y%m%d`.txt
echo "set line 2500;
show parameter sga;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_sga_`date +%y%m%d`.txt
}
ora_pga_info(){
echo "######################## 3.3 内存参数pga"
echo "select ' ' as \"--3.3.DB pga\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_pga_`date +%y%m%d`.txt
echo "set line 2500;
show parameter pga;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_pga_`date +%y%m%d`.txt
}
ora_dbfile_info(){
echo "######################## 4.表空间是否自动扩展"
echo "select ' ' as \"--4.DB dbfile\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_dbfile_`date +%y%m%d`.txt
echo "set lines 2500;
col TABLESPACE_NAME for a15;
col FILE_NAME for a60;
select FILE_NAME, TABLESPACE_NAME, AUTOEXTENSIBLE, maxbytes/1024/1024 as max_m,increment_by/1024/1024 as incre_m from dba_data_files;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_dbfile_`date +%y%m%d`.txt
}
ora_dbfile_useage_info(){
echo "######################## 5.表空间使用率"
echo "select ' ' as \"--5.DB dbfile useage\" from dual;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_dbfile_useage_`date +%y%m%d`.txt
echo "set line 2500;
col 表空间名 for a14;
SELECT UPPER(F.TABLESPACE_NAME) \"表空间名\",D.TOT_GROOTTE_MB \"表空间大小(G)\",D.TOT_GROOTTE_MB - F.TOTAL_BYTES \"已使用空间(G)\",TO_CHAR(ROUND((D.TOT_GROOTTE_MB - F.TOTAL_BYTES) / D.TOT_GROOTTE_MB * 100,2),'990.99') || '%' \"使用比\",F.TOTAL_BYTES \"空闲空间(G)\",F.MAX_BYTES \"最大块(G)\" FROM (SELECT TABLESPACE_NAME,ROUND(SUM(BYTES) / (1024 * 1024*1024), 2) TOTAL_BYTES,ROUND(MAX(BYTES) / (1024 * 1024*1024), 2) MAX_BYTES FROM SYS.DBA_FREE_SPACE where tablespace_name<> 'USERS' GROUP BY TABLESPACE_NAME) F,(SELECT DD.TABLESPACE_NAME,ROUND(SUM(DD.BYTES) / (1024 * 1024*1024), 2) TOT_GROOTTE_MB FROM SYS.DBA_DATA_FILES DD where dd.tablespace_name<> 'USERS' GROUP BY DD.TABLESPACE_NAME) D WHERE D.TABLESPACE_NAME = F.TABLESPACE_NAME ORDER BY 1;" >ora_sql.sql
sqlplus $sqlstr <ora_sql.sql>>/tmp/tmpora_dbfile_useage_`date +%y%m%d`.txt
}
create_html(){
rm -rf $file_output
touch $file_output
create_html_css >> $file_output
create_html_head "0 Network Info Summary" >> $file_output
create_table_head1 >> $file_output
get_netinfo
while read line
do
create_tr2 "$line"
done < /tmp/tmpnet_h1_`date +%y%m%d`.txt
while read line
do
create_tr1 "$line"
done < /tmp/tmpnet1_`date +%y%m%d`.txt
create_table_end >> $file_output
create_html_head "1 Version of Database" >> $file_output
create_table_head1 >> $file_output
ora_base_info
sed -i '27,33!d' /tmp/tmpora_base_`date +%y%m%d`.txt
sed -i '2,3d' /tmp/tmpora_base_`date +%y%m%d`.txt
create_tr3 "/tmp/tmpora_base_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_head "2 Status of archive_log" >> $file_output
create_table_head1 >> $file_output
ora_archive_info
sed -i '2,11d' /tmp/tmpora_archive_`date +%y%m%d`.txt
create_tr3 "/tmp/tmpora_archive_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_head "3.1 memory Config of Database" >> $file_output
create_table_head1 >> $file_output
ora_mem_info
sed -i '1,30d' /tmp/tmpora_mem_`date +%y%m%d`.txt
for i in `seq 2`; do sed -i '$d' /tmp/tmpora_mem_`date +%y%m%d`.txt ; done
create_tr3 "/tmp/tmpora_mem_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_head "3.2 sga Config of Database" >> $file_output
create_table_head1 >> $file_output
ora_sga_info
sed -i '1,30d' /tmp/tmpora_sga_`date +%y%m%d`.txt
for i in `seq 2`; do sed -i '$d' /tmp/tmpora_sga_`date +%y%m%d`.txt ; done
create_tr3 "/tmp/tmpora_sga_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_head "3.3 pga Config of Database" >> $file_output
create_table_head1 >> $file_output
ora_pga_info
sed -i '1,30d' /tmp/tmpora_pga_`date +%y%m%d`.txt
for i in `seq 2`; do sed -i '$d' /tmp/tmpora_pga_`date +%y%m%d`.txt ; done
create_tr3 "/tmp/tmpora_pga_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_head "4 dbfile autoextensible of Database" >> $file_output
create_table_head1 >> $file_output
ora_dbfile_info
sed -i '1,30d' /tmp/tmpora_dbfile_`date +%y%m%d`.txt
for i in `seq 2`; do sed -i '$d' /tmp/tmpora_dbfile_`date +%y%m%d`.txt ; done
create_tr3 "/tmp/tmpora_dbfile_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_head "5 dbfile usage of Database" >> $file_output
create_table_head1 >> $file_output
ora_dbfile_useage_info
sed -i '1,30d' /tmp/tmpora_dbfile_useage_`date +%y%m%d`.txt
for i in `seq 2`; do sed -i '$d' /tmp/tmpora_dbfile_useage_`date +%y%m%d`.txt ; done
create_tr3 "/tmp/tmpora_dbfile_useage_`date +%y%m%d`.txt"
create_table_end >> $file_output
create_html_end >> $file_output
sed -i 's/BORDER=1/width="68%" border="1" bordercolor="#000000" cellspacing="0px" style="border-collapse:collapse"/g' $file_output
rm -rf /tmp/tmp*_`date +%y%m%d`.txt
rm -rf ora_sql.sql
}
PLATFORM=`uname`
if [ ${PLATFORM} = "HP-UX" ] ; then
echo "This script does not support HP-UX platform for the time being"
exit 1
elif [ ${PLATFORM} = "SunOS" ] ; then
echo "This script does not support SunOS platform for the time being"
exit 1
elif [ ${PLATFORM} = "AIX" ] ; then
echo "This script does not support AIX platform for the time being"
exit 1
elif [ ${PLATFORM} = "Linux" ] ; then
create_html
fi
到此这篇关于oracle自动巡检脚本生成html报告的文章就介绍到这了,更多相关oracle自动巡检脚本内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Oracle数据库自动备份脚本分享(超实用)
前言 众所周知数据是应用的核心部分,程序坏了换台机器重新发布就可以,但数据一旦丢失,造成的损失将不可挽回,程序发布到生产后,数据的备份便显得尤为重要,由于不一定所有的服务均有资金完成高级的备份如RAC和DG,在我们只有一台数据库服务器的,暂时采取最简单的备份策略,export出dmp进行保存. 一.备份脚本 1.初始化变量,记录开始日志 #变量 sysname=填写自己的系统名称 syspath=/home/oracle/databak/$sysname v_date=$(date '+%Y%m
-
Oracle数据库执行脚本常用命令小结
1. 执行一个SQL脚本文件 复制代码 代码如下: sqlplus user/pass@servicename<file_name.sql 或 复制代码 代码如下: SQL>start file_names 或 复制代码 代码如下: SQL>@ file_name 我们可以将多条sql语句保存在一个文本文件中,这样当要执行这个文件中的所有的sql语句时,用上面的任一命令即可,这类似于dos中的批处理. @与@@的区别是什么? @等于start命令,用来运行一个sql脚本文件. @命令调用
-
Linux下通过脚本自动备份Oracle数据库并删除指定天数前的备份
说明: Oracle数据库服务器 操作系统:CentOS IP:192.168.0.198 端口:1521 SID:orcl Oracle数据库版本:Oracle11gR2 具体操作: 1.root用户登录服务器 mkdir -p /backup/oracledata #新建Oracle数据库备份目录 chown -R oracle:oinstall /backup/oracledata -R #设置目录权限为oinstall用户组的oracle用户(用户oracle与用户组oinstall是在
-
Linux中Oracle服务启动和停止脚本与开机自启动
在CentOS 6.3下安装完Oracle 10g R2,重开机之后,你会发现Oracle没有自行启动,这是正常的,因为在Linux下安装Oracle的确不会自行启动,必须要自行设定相关参数,首先先介绍一般而言如何启动oracle. 一.在Linux下启动Oracle 登录到CentOS,切换到oracle用户权限 # su – oracle 接着输入: $ sqlplus "/as sysdba" 原本的画面会变为 SQL> 接着请输入 SQL> startup 就可以正
-
Oracle自动备份脚本
废话不多说了,直接给大家贴代码了,具体代码如下所示: #!/bin/sh #****************************************************************** # File: oraclebak.sh # Creation Date: 2014/1/22 17:57:32 # Last Modified: 2014/1/22 17:57:34 # 脚本功能:oracle备份脚本 # 执行方法:1.第一次执行需要root用户执行,脚本会以询问的方式
-
oracle自动巡检脚本生成html报告的方法
一. 前言 1.由于每月月底都需要对一些oracle数据库环境进行一些简单的巡检,而通过运行一条条语句,并依依去截图保存到word文档中效率低下,所以这里我就将手工巡检过程编写成shell脚本来提高巡检效率,同时也免去了截图照片图片不清晰的问题. 2.脚本简单容易二次编辑,本文仅提供简单巡检的事项,如数据表空间是否自动扩展.是否开启归档等,大家根据实际需要编辑修改,增加符合自己公司需求的巡检报告. 3.项目已经上传到我的github上 项目地址:orawatch.git 二.注意事项与报告部分截
-
利用Python半自动化生成Nessus报告的方法
0x01 前言 Nessus是一个功能强大而又易于使用的远程安全扫描器,Nessus对个人用户是免费的,只需要在官方网站上填邮箱,立马就能收到注册号了,对应商业用户是收费的.当然,个人用户是有16个IP限制,通过企业邮箱可以体验免费7天的Nessus专业版,IP无限制. Nessus激活码获取地址:https://www.tenable.com/products/nessus/activation-code 0x02 Nessus使用 登录后通过New Scan创建扫描任务,扫描完成后,我们即可
-
oracle使用sql脚本生成csv文件案例学习
脚本内容如下: 复制代码 代码如下: set linesize 3000; set heading off; set feedback off; set term off; set pagesize 0; set trimspool on; spool a.csv; select c1_name||','||c2_name from dual; select c1||','||c2 from tbtest spool off;
-
使用PHPUnit进行单元测试并生成代码覆盖率报告的方法
安装PHPUnit 使用 Composer 安装 PHPUnit #查看composer的全局bin目录 将其加入系统 path 路径 方便后续直接运行安装的命令 composer global config bin-dir --absolute #全局安装 phpunit composer global require --dev phpunit/phpunit #查看版本 phpunit --version 使用Composer构建你的项目 我们将新建一个unit项目用于演示单元测试的基本工
-
oracle自动生成uuid的实现方法
目录 oracle自动生成uuid方法 1.创建一个表 2.生成uuid的语句 3.添加几条数据,查询就可以看到效果 oracle获取UUID乱码 oracle自动生成uuid方法 1.创建一个表 create table t_user(id varchar2(200),name varchar2(200)); 2.生成uuid的语句 alter table t_user modify id default sys_guid(); update t_user set id = sys_guid(
-
Oracle自动备份及自动备份步骤
数据是应用的核心部分,程序坏了换台机器重新发布就可以,但数据一旦丢失,造成的损失将不可挽回,程序发布到生产后,数据的备份便显得尤为重要,由于不一定所有的服务均有资金完成高级的备份如RAC和DG,在我们只有一台数据库服务器的,暂时采取最简单的备份策略,export出dmp进行保存. 一.备份脚本 1.初始化变量,记录开始日志 #变量 sysname=填写自己的系统名称 syspath=/home/oracle/databak/$sysname v_date=$(date '+%Y%m%d%H%M%
-
Oracle约束管理脚本
正在看的ORACLE教程是:Oracle约束管理脚本.作为一个Oracle数据库管理员,会碰到这样的数据库管理需求,停止或者打开当前用户(模式)下所有表的约束条件和触发器.这在数据库的合并以及对数据库系统的代码表中某些代码的修改时需要做的工作之一. 我们来看这样一种实际数据库工作业务需求,这在目前的许多应用中是非常实际的.某地区银行数据,目前采用市级数据集中,随着计算机网络技术的不断提高以及对服务水平的要求,提出了省级乃至国家级的数据集中.除了应用需要修改以外,对于数据库管理员来讲,最重要的工作
-
mysql巡检脚本(必看篇)
如下所示: #!/usr/bin/env python3.5 import psutil import mysql.connector import argparse import json import datetime def get_cpu_info(verbose): cpu_info={} if verbose >0: print("[cpu] start collect cpu info ...") data=psutil.cpu_times_percent(3) c
-
python脚本生成caffe train_list.txt的方法
首先给出代码: import os path = "/home/data//" path_exp = os.path.expanduser(path) classes = [int(p) for p in os.listdir(path_exp)] classes.sort() # nrof_classes一个数据集下有多少个文件夹,就是说有多少个人,多少个类别 nrof_classes = len(classes) count=0 files = open("train_l