Pandas对每个分组应用apply函数的实现
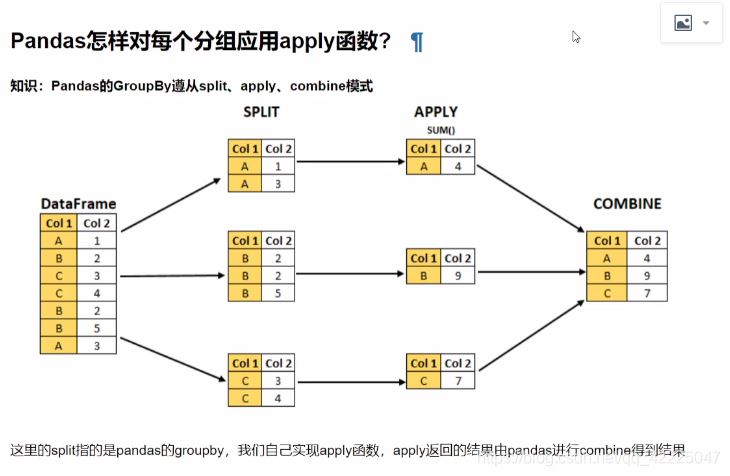
Pandas的apply函数概念(图解)

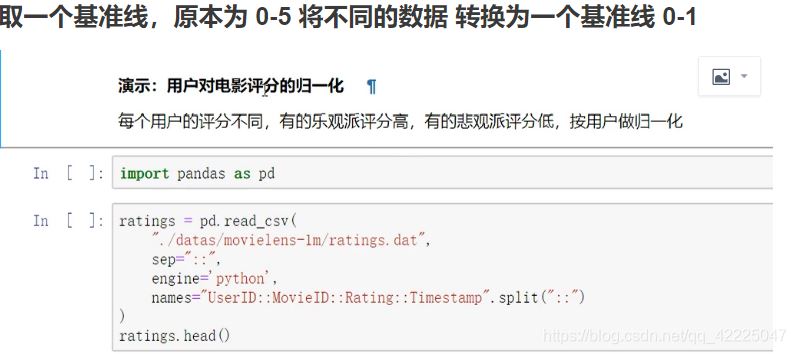
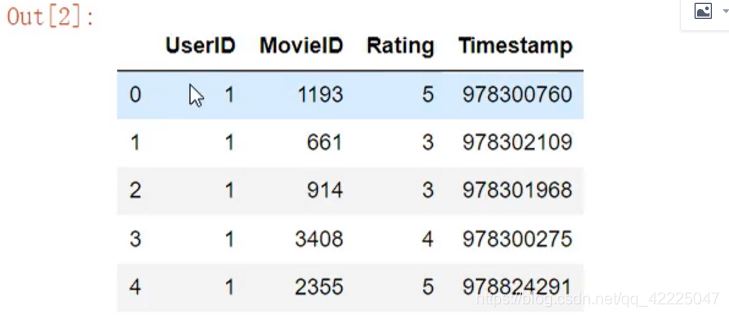
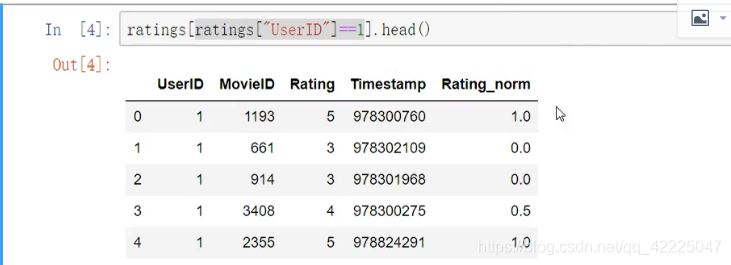
实例1:怎样对数值按分组的归一化


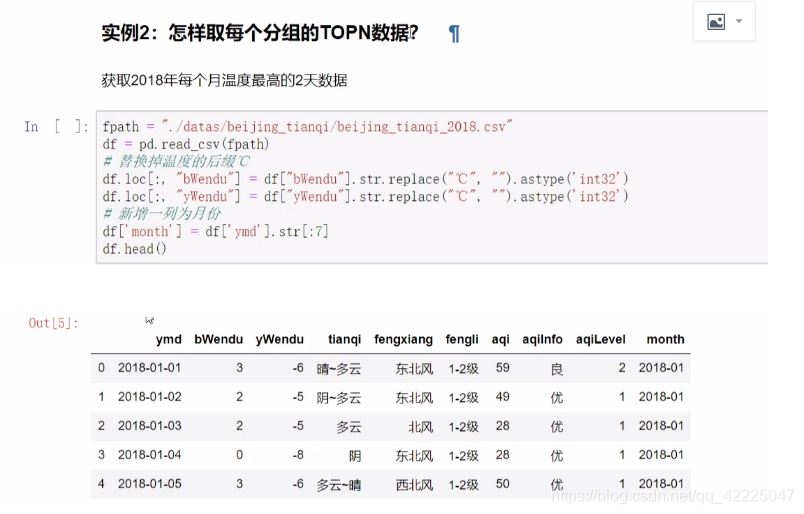
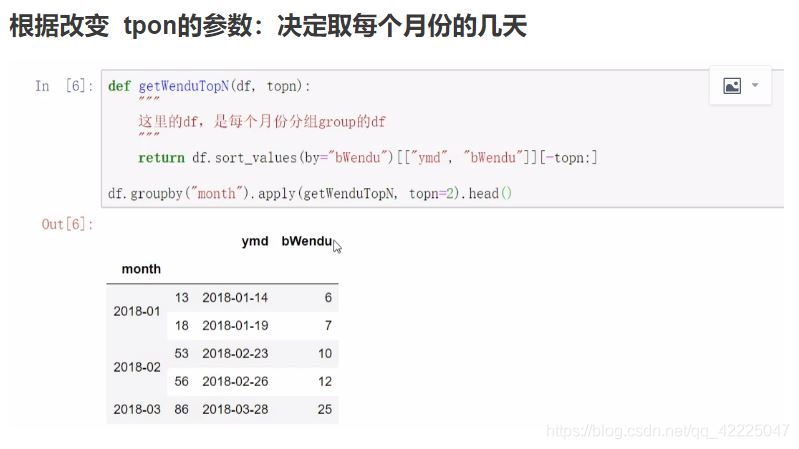
实例2:怎样取每个分组的TOPN数据

到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas 应用apply函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas apply多线程实现代码
一.多线程化选择 并行化一个代码有两大选择:multithread 和 multiprocess. Multithread,多线程,同一个进程(process)可以开启多个线程执行计算.每个线程代表了一个 CPU 核心,这么多线程可以访问同样的内存地址(所谓共享内存),实现了线程之间的通讯,算是最简单的并行模型. Multiprocess,多进程,则相当于同时开启多个 Python 解释器,每个解释器有自己独有的数据,自然不会有数据冲突. 二.并行化思想 并行化的基本思路是把 dataframe
-
pandas使用函数批量处理数据(map、apply、applymap)
前言 在我们对DataFrame对象进行处理时候,下意识的会想到对DataFrame进行遍历,然后将处理后的值再填入DataFrame中,这样做比较繁琐,且处理大量数据时耗时较长.Pandas内置了一个可以对DataFrame批量进行函数处理的工具:map.apply和applymap. 提示:为方便快捷地解决问题,本文仅介绍函数的主要用法,并非全面介绍 一.pandas.Series.map()是什么? 把Series中的值进行逐一映射,带入进函数.字典或Series中得出的另一个值. Ser
-
Pandas的Apply函数具体使用
Pandas最好用的函数 Pandas是Python语言中非常好用的一种数据结构包,包含了许多有用的数据操作方法.而且很多算法相关的库函数的输入数据结构都要求是pandas数据,或者有该数据的接口. 仔细看pandas的API说明文档,就会发现有好多有用的函数,比如非常常用的文件的读写函数就包括如下函数: Format Type Data Description Reader Writer text CSV read_csv to_csv text JSON read_json to_json
-
pandas apply 函数 实现多进程的示例讲解
前言: 在进行数据处理的时候,我们经常会用到 pandas .但是 pandas 本身好像并没有提供多进程的机制.本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行.其中,我们主要借助 joblib库,这个库为python 提供了一个非常简洁方便的多进程实现方法. 所以,本文将按照下面的安排展开,前面可能比较啰嗦,若只是想知道怎么用可直接看第三部分: - 首先简单介绍 pandas 中的分组聚合操作 groupby. - 然后简单介绍 joblib 的使用方法. - 最后,
-
pandas使用apply多列生成一列数据的实例
如下所示: import pandas as pd def my_min(a, b): return min(abs(a),abs(b)) s = pd.Series([10.0247,10.0470, 10.0647,10.0761,15.0800,10.0761,10.0647,10.0470,10.0247,10.0,9.9753,9.9530,9.9353,9.9239,18.92,9.9239,9.9353,9.9530,9.9753,10.0]) df = pd.DataFrame(
-
pandas 使用apply同时处理两列数据的方法
多的不说,看了代码就懂了! df = pd.DataFrame ({'a' : np.random.randn(6), 'b' : ['foo', 'bar'] * 3, 'c' : np.random.randn(6)}) def my_test(a, b): return a + b df['Value'] = df.apply(lambda row: my_test(row['a'], row['c']), axis=1) print df 以上这篇pandas 使用apply同时处理两列
-

Pandas对每个分组应用apply函数的实现
Pandas的apply函数概念(图解) 实例1:怎样对数值按分组的归一化 实例2:怎样取每个分组的TOPN数据 到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas 应用apply函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
详谈pandas中agg函数和apply函数的区别
在利用python进行数据分析 这本书中其实没有明确表明这两个函数的却别,而是说apply更一般化. 其实在这本书的第九章'数组及运算和转换'点到了两者的一点点区别:agg是用来聚合运算的,所谓的聚合当然是合成的成分比较大些,这一节开头就点到了:聚合只不过是分组运算的其中一种而已.它是数据转换的一个特例,也就是说,它接受能够将一维数组简化为标量值的函数. 当然这两个函数都是作用在groupby对象上的,也就是分完组的对象上的,分完组之后针对某一组,如果值是一维数组,在利用完特定的函数之后,能做到
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
解析pandas apply() 函数用法(推荐)
目录 Series.apply() apply 函数接收带有参数的函数 DataFrame.apply() apply() 计算日期相减示例 参考 理解 pandas 的函数,要对函数式编程有一定的概念和理解.函数式编程,包括函数式编程思维,当然是一个很复杂的话题,但对今天介绍的 apply() 函数,只需要理解:函数作为一个对象,能作为参数传递给其它函数,也能作为函数的返回值. 函数作为对象能带来代码风格的巨大改变.举一个例子,有一个类型为 list 的变量,包含 从 1 到 10 的数据,需
-
Pandas中Apply函数加速百倍的技巧分享
目录 前言 实验对比 01 Apply(Baseline) 02 Swift加速 03 向量化 04 类别转化+向量化 05 转化为values处理 实验汇总 前言 虽然目前dask,cudf等包的出现,使得我们的数据处理大大得到了加速,但是并不是每个人都有比较好的gpu,非常多的朋友仍然还在使用pandas工具包,但有时候真的很无奈,pandas的许多问题我们都需要使用apply函数来进行处理,而apply函数是非常慢的,本文我们就介绍如何加速apply函数600倍的技巧. 实验对比 01 A
-
Pandas中map(),applymap(),apply()函数的使用方法
目录 指定pandas对象作为NumPy函数的参数 元素的应用 行/列的应用 pandas.DataFrame,pandas.Series方法 Pandas对象方法的函数应用 适用于Series的每个元素:map(),apply() 应用于DataFrame的每个元素:applymap() 应用于DataFrame的每行和每列:apply() 应用于DataFrame的特定行/列元素 将函数应用于pandas对象(pandas.DataFrame,pandas.Series)时,根据所应用的函数
-
浅谈Pandas中map, applymap and apply的区别
1.apply() 当想让方程作用在一维的向量上时,可以使用apply来完成,如下所示 In [116]: frame = DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon']) In [117]: frame Out[117]: b d e Utah -0.029638 1.081563 1.280300 Ohio 0.647747 0.831136 -1.