spring batch使用reader读数据的内存容量问题详解
概述
本篇博客是记录使用spring batch做数据迁移时时遇到的一个关键问题:数据迁移量大时如何保证内存。当我们在使用spring batch时,我们必须配置三个东西: reader,processor,和writer。其中,reader用于从数据库中读数据,当数据量较小时,reader的逻辑不会对内存带来太多压力,但是当我们要去读的数据量非常大的时候,我们就不得不考虑内存等方面的问题,因为若数据量非常大,内存,执行时间等等都会受到影响。关于spring batch的基础知识和介绍请参考这篇博客:批处理框架spring batch介绍及使用。
问题是什么
在上面的内容当中我们已经提到了,我们面临的问题是数据迁移量大时的内存问题。但是这样的描述非常笼统,因此博主决定将这一部分单独拎出来说。
在学习了spring batch的知识之后我们应该很清楚的一点是,每一个spring batch的step都包含如下的部分:

即读数据,处理数据,写数据。这三个步骤里面最可能会导致内存变大问题的无疑是读数据环节。读数据作为spring batch的数据输入,是整个spring batch job的开头逻辑。
若我们的数据量不大,如只有几十万条,那我们无疑不会面临内存问题,即便一次将所有数据加载到内存当中,占的内存也不会非常多,且spring batch数据迁移的速度非常之快,几十万条的数据往往是几十秒的时间就可以迁移完成。但是当数据量变大之后,问题就不一样了。当我们的数据量达到数百万或上千万时,若一次性将所有数据全部读到内存当中,则会占据远远超出正常范围的非常大的内存。该问题示意图如下所示:

我们写的任何程序都会有一个运行内存,假设这个内存的总容量现在只有4g,而我们数据库里需要操作的数据有8g,那么无疑,一次性的将数据读出来就会出错。这便是需要考虑得问题。
Spring提供的reader实现
spring提供了非常丰富的Reader实现,其中比较常用的从数据库读数据的有JdbcCursorItemReader,JdbcPagingItemReader等。
JdbcCursorItemReader
使用JdbcCursorItemReader的示例代码如下:
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}
JdbcCursorItemReader的好处在于使用简单,但是我们从它的sql就能发现,JdbcCursorItemReader会一次把所有的数据全部拿回来,当数据量过大而服务器内存不够时,就会遇到下面无法分配内存的问题:

报错信息为:Resource exhaustion event:The JVM was unable to allocate memory from the heap. 意思就是需要分配内存的数据太多,但是无法找到足够的内存了。
反映在内存里,堆内存会呈现出如下的情况:
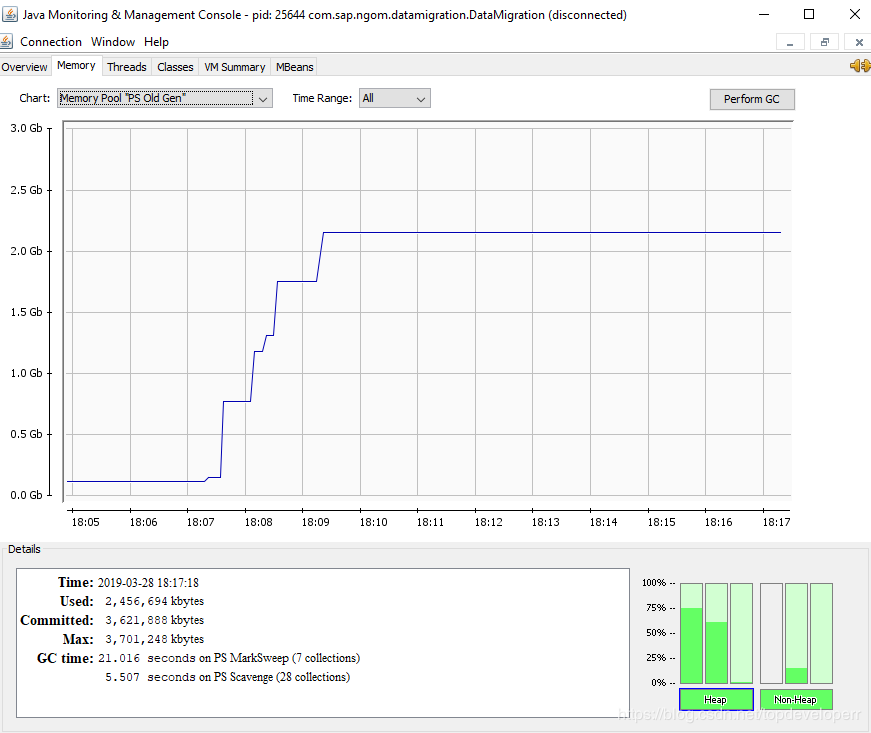
随着每一次数据读入,堆内存都会增大,原因就在于JdbcCursorItemReader一次性读回了所有的数据,返回之后就会存在一个对象里面,而这个对象的尺寸过大,因此直接进入了老年代。在数据迁移完成之前,这些数据都不会被回收。如下图所示:
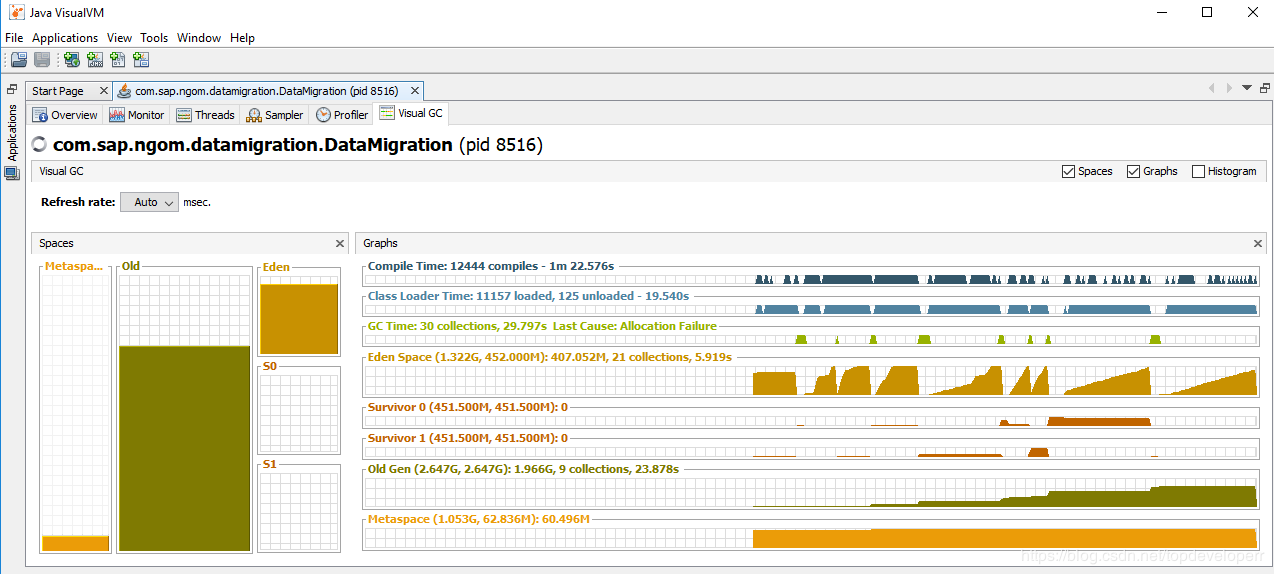
毫无疑问,当我们的数据量大时不应该使用这种类型的reader来读取数据。
JdbcPagingItemReader
JdbcPagingItemReader的作用和它的名字一样,它可以分页读取数据,但是使用起来相比于JdbcCursorItemReader更加复杂,示例代码如下:
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}
可以看到我们能够设置page的大小,JdbcPagingItemReader将根据这个页的大小,每次读取这么多的数据,因此这些数据返回保存的对象,就只会是小对象,因此他们不会直接在老年代里分配,而是先分配在年轻代,随着年轻代不断变大,minor gc也不断进行,回收掉已经处理完的数据,老年代的内存使用量不会有任何增大,类似下图:


老年代内存不会有任何变化,年轻带会随着服务器数据迁移进行而增大同时被回收。
在使用JdbcPagingItemReader时,有一个必须注意的地方就是排序关键字是必须指定的,原因在于排序是分页实现原理的技术基础。sortKey和我们指定的其他字句一起构建出SQL语句出来。在sortKey上必须使用unique key constraint约束,因为只有这样才能得以确保执行之间不会丢失任何数据。这也可以说是JdbcCursorItemReader相对便利的一点优势。
总结
数据量小时选择的方案差别不会很大,当数据量大时,为了有好的内存表现则使用分页的reader是必要的。但同时,因为要实现分页,也会带来一些不可避免的限制。
到此这篇关于spring batch使用reader读数据的内存容量问题详解的文章就介绍到这了,更多相关spring batch使用reader读数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
DataReader不能使用using的详细示例
本文介绍了DataReader不能使用using的详细示例,分享给大家,具有如下: public static MySqlDataReader ExecuteMySqlReader(string sqlStr) { MySqlConnection conn = new MySqlConnection(MyConString); MySqlCommand cmd = new MySqlCommand(sqlStr, conn); try { conn.Open(); //执行CloseConnec
-

java中ImageReader和BufferedImage获取图片尺寸实例
ImageReader 对象通常由特定格式的服务提供者接口 (SPI) 类实例化.服务提供者类(例如 ImageReaderSpi 的实例)向 IIORegistry 注册,后者使用前者进行格式识别和表示可用格式 reader 和 writer. BufferedImage子类描述具有可访问图像数据缓冲区的Image.BufferedImage由图像数据的ColorModel和Raster组成.Raster的SampleModel中band的数量和类型必须与ColorModel所要求的数量和类型
-
基于自定义BufferedReader中的read和readLine方法
实例如下所示: package day0208; import java.io.FileReader; import java.io.IOException; /* * 自定义读取缓冲区,实现BufferedReader功能 * 分析: * 缓冲区就是封装了一个数组,并对外提供了更多的方法对数组进行访问 * 其实这些方法最终操作的都是数组的角标 * 缓冲的原理: * 其实就是从源中获取一批数据装进缓冲区,再从缓冲区取出数据 * 当此次取完后,继续从源中取出一批数据到缓冲区 * 当源中的数据取光时
-
python中reader的next用法
python中有个csv包(build-in),该包有个reader,按行读取csv文件中的数据 reader.next()作用:打印csv文件中的第一行标题header (python3中的用法) allElectronicsData = open(r'C:/pydata/AllElectronics.csv', 'rt') reader = csv.reader(allElectronicsData) headers = next(reader) (python2中的用法) allElect
-
Java中BufferedReader类获取输入输入字符串实例
使用Scanner来取得使用者的输入很方便,但是它以空白来区隔每一个输入字符串,在某些时候并不适用,因为使用者可能输入一个字符串,中间会包括空白字元,而您希望取得完整的字符串. 您可以使用BufferedReader类别,它是java.io包中所提供的一个类,所以使用这个类时必须先import java.io包:使用BufferedReader对象的readLine()方法必须处理IOException异常(exception),异常处理机制是Java提供给程序设计人员捕捉程序中可能发生的错误所
-
spring batch使用reader读数据的内存容量问题详解
概述 本篇博客是记录使用spring batch做数据迁移时时遇到的一个关键问题:数据迁移量大时如何保证内存.当我们在使用spring batch时,我们必须配置三个东西: reader,processor,和writer.其中,reader用于从数据库中读数据,当数据量较小时,reader的逻辑不会对内存带来太多压力,但是当我们要去读的数据量非常大的时候,我们就不得不考虑内存等方面的问题,因为若数据量非常大,内存,执行时间等等都会受到影响.关于spring batch的基础知识和介绍请参考这篇
-
Spring AOP里的静态代理和动态代理用法详解
什么是代理? 为某一个对象创建一个代理对象,程序不直接用原本的对象,而是由创建的代理对象来控制原对象,通过代理类这中间一层,能有效控制对委托类对象的直接访问,也可以很好地隐藏和保护委托类对象,同时也为实施不同控制策略预留了空间 什么是静态代理? 由程序创建或特定工具自动生成源代码,在程序运行前,代理类的.class文件就已经存在 通过将目标类与代理类实现同一个接口,让代理类持有真实类对象,然后在代理类方法中调用真实类方法,在调用真实类方法的前后添加我们所需要的功能扩展代码来达到增强的目的. 优点
-
spring security在分布式项目下的配置方法(案例详解)
分布式项目和传统项目的区别就是,分布式项目有多个服务,每一个服务仅仅只实现一套系统中一个或几个功能,所有的服务组合在一起才能实现系统的完整功能.这会产生一个问题,多个服务之间session不能共享,你在其中一个服务中登录了,登录信息保存在这个服务的session中,别的服务不知道啊,所以你访问别的服务还得在重新登录一次,对用户十分不友好.为了解决这个问题,于是就产生了单点登录: **jwt单点登录:**就是用户在登录服务登录成功后,登录服务会产生向前端响应一个token(令牌),以后用户再访问系
-
AMP Tensor Cores节省内存PyTorch模型详解
目录 导读 什么是Tensor Cores? 那么,我们如何使用Tensor Cores? 使用PyTorch进行混合精度训练: 基准测试 导读 只需要添加几行代码,就可以得到更快速,更省显存的PyTorch模型. 你知道吗,在1986年Geoffrey Hinton就在Nature论文中给出了反向传播算法? 此外,卷积网络最早是由Yann le cun在1998年提出的,用于数字分类,他使用了一个卷积层.但是直到2012年晚些时候,Alexnet才通过使用多个卷积层来实现最先进的imagene
-
SQLServer的内存管理架构详解
目录 一.Windows的虚拟内存管理器 二.SQL Server 内存体系结构 2.1.传统(虚拟)内存 2.2.地址窗口扩展 (AWE) 内存 三.从 SQL Server 2012 (11.x) 开始发生的改变 3.1.对内存管理的更改 3.2.对memory_to_reserve所做的更改 四.动态内存管理 4.1.堆栈大小 五.缓冲区管理 5.1.缓冲区管理的工作原理 5.2.支持的功能 5.3.磁盘 I/O 5.4.长 I/O 请求 5.5.长时间 I/O 请求的原因 六.了解非一致
-
内存溢出和内存泄漏的详解及区别
内存溢出和内存泄漏的详解及区别 内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory:比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出. 内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光. memory leak会最终会导致out of memory! 内存溢出就是你要求分配的内存超出了系统能
-
Java Spring MVC 上传下载文件配置及controller方法详解
下载: 1.在spring-mvc中配置(用于100M以下的文件下载) <bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter"> <property name="messageConverters"> <list> <!--配置下载返回类型--> <bean class="or
-
C语言动态内存分配的详解
C语言动态内存分配的详解 1.为什么使用动态内存分配 数组在使用的时候可能造成内存浪费,使用动态内存分配可以解决这个问题. 2. malloc和free C函数库提供了两个函数,malloc和free,分别用于执行动态内存分配和释放. (1)void *malloc(size_t size); malloc的参数就是需要分配的内存字节数.malloc分配一块连续的内存.如果操作系统无法向malloc提供更多的内存,malloc就返回一个NULL指针. (2)void free(void *poi
-
C++中的内存对齐实例详解
C++中的内存对齐实例详解 内存对齐 在我们的程序中,数据结构还有变量等等都需要占有内存,在很多系统中,它都要求内存分配的时候要对齐,这样做的好处就是可以提高访问内存的速度. 我们还是先来看一段简单的程序: 程序一 #include <iostream> using namespace std; struct X1 { int i;//4个字节 char c1;//1个字节 char c2;//1个字节 }; struct X2 { char c1;//1个字节 int i;//4个字节 ch
-
Java GC 机制与内存分配策略详解
Java GC 机制与内存分配策略详解 收集算法是内存回收的方法论,垃圾收集器是内存回收的具体实现 自动内存管理解决的是:给对象分配内存 以及 回收分配给对象的内存 为什么我们要了解学习 GC 与内存分配呢? 在 JVM 自动内存管理机制的帮助下,不再需要为每一个new操作写配对的delete/free代码.但出现内存泄漏和溢出的问题时,如果不了解虚拟机是怎样使用内存的,那么排查错误将是一项非常艰难的工作. GC(垃圾收集器)在对堆进行回收前,会先确定哪些对象"存活",哪些已经&quo