Python图片检索之以图搜图
一、待搜索图

二、测试集
三、new_similarity_compare.py
# -*- encoding=utf-8 -*-
from image_similarity_function import *
import os
import shutil
# 融合相似度阈值
threshold1 = 0.70
# 最终相似度较高判断阈值
threshold2 = 0.95
# 融合函数计算图片相似度
def calc_image_similarity(img1_path, img2_path):
"""
:param img1_path: filepath+filename
:param img2_path: filepath+filename
:return: 图片最终相似度
"""
similary_ORB = float(ORB_img_similarity(img1_path, img2_path))
similary_phash = float(phash_img_similarity(img1_path, img2_path))
similary_hist = float(calc_similar_by_path(img1_path, img2_path))
# 如果三种算法的相似度最大的那个大于0.7,则相似度取最大,否则,取最小。
max_three_similarity = max(similary_ORB, similary_phash, similary_hist)
min_three_similarity = min(similary_ORB, similary_phash, similary_hist)
if max_three_similarity > threshold1:
result = max_three_similarity
else:
result = min_three_similarity
return round(result, 3)
if __name__ == '__main__':
# 搜索文件夹
filepath = r'D:\Dataset\cityscapes\leftImg8bit\val\frankfurt'
#待查找文件夹
searchpath = r'C:\Users\Administrator\Desktop\cityscapes_paper'
# 相似图片存放路径
newfilepath = r'C:\Users\Administrator\Desktop\result'
for parent, dirnames, filenames in os.walk(searchpath):
for srcfilename in filenames:
img1_path = searchpath +"\\"+ srcfilename
for parent, dirnames, filenames in os.walk(filepath):
for i, filename in enumerate(filenames):
print("{}/{}: {} , {} ".format(i+1, len(filenames), srcfilename,filename))
img2_path = filepath + "\\" + filename
# 比较
kk = calc_image_similarity(img1_path, img2_path)
try:
if kk >= threshold2:
# 将两张照片同时拷贝到指定目录
shutil.copy(img2_path, os.path.join(newfilepath, srcfilename[:-4] + "_" + filename))
except Exception as e:
# print(e)
pass
四、image_similarity_function.py
# -*- encoding=utf-8 -*-
# 导入包
import cv2
from functools import reduce
from PIL import Image
# 计算两个图片相似度函数ORB算法
def ORB_img_similarity(img1_path, img2_path):
"""
:param img1_path: 图片1路径
:param img2_path: 图片2路径
:return: 图片相似度
"""
try:
# 读取图片
img1 = cv2.imread(img1_path, cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread(img2_path, cv2.IMREAD_GRAYSCALE)
# 初始化ORB检测器
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# 提取并计算特征点
bf = cv2.BFMatcher(cv2.NORM_HAMMING)
# knn筛选结果
matches = bf.knnMatch(des1, trainDescriptors=des2, k=2)
# 查看最大匹配点数目
good = [m for (m, n) in matches if m.distance < 0.75 * n.distance]
similary = len(good) / len(matches)
return similary
except:
return '0'
# 计算图片的局部哈希值--pHash
def phash(img):
"""
:param img: 图片
:return: 返回图片的局部hash值
"""
img = img.resize((8, 8), Image.ANTIALIAS).convert('L')
avg = reduce(lambda x, y: x + y, img.getdata()) / 64.
hash_value = reduce(lambda x, y: x | (y[1] << y[0]), enumerate(map(lambda i: 0 if i < avg else 1, img.getdata())),
0)
return hash_value
# 计算两个图片相似度函数局部敏感哈希算法
def phash_img_similarity(img1_path, img2_path):
"""
:param img1_path: 图片1路径
:param img2_path: 图片2路径
:return: 图片相似度
"""
# 读取图片
img1 = Image.open(img1_path)
img2 = Image.open(img2_path)
# 计算汉明距离
distance = bin(phash(img1) ^ phash(img2)).count('1')
similary = 1 - distance / max(len(bin(phash(img1))), len(bin(phash(img1))))
return similary
# 直方图计算图片相似度算法
def make_regalur_image(img, size=(256, 256)):
"""我们有必要把所有的图片都统一到特别的规格,在这里我选择是的256x256的分辨率。"""
return img.resize(size).convert('RGB')
def hist_similar(lh, rh):
assert len(lh) == len(rh)
return sum(1 - (0 if l == r else float(abs(l - r)) / max(l, r)) for l, r in zip(lh, rh)) / len(lh)
def calc_similar(li, ri):
return sum(hist_similar(l.histogram(), r.histogram()) for l, r in zip(split_image(li), split_image(ri))) / 16.0
def calc_similar_by_path(lf, rf):
li, ri = make_regalur_image(Image.open(lf)), make_regalur_image(Image.open(rf))
return calc_similar(li, ri)
def split_image(img, part_size=(64, 64)):
w, h = img.size
pw, ph = part_size
assert w % pw == h % ph == 0
return [img.crop((i, j, i + pw, j + ph)).copy() for i in range(0, w, pw) \
for j in range(0, h, ph)]
五、结果
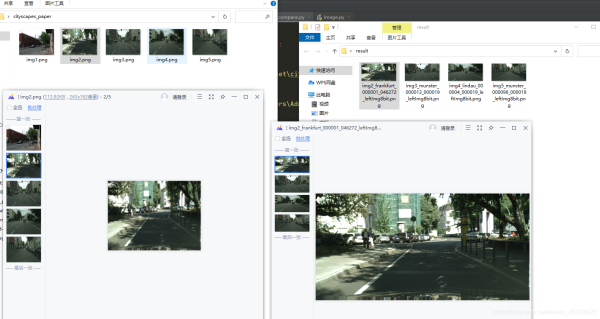
到此这篇关于Python图片检索之以图搜图的文章就介绍到这了,更多相关Python以图搜图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 爬取英雄联盟皮肤图片
一开始都是先去<英雄联盟>官网找到英雄及皮肤图片的网址: URL = r'https://lol.qq.com/data/info-heros.shtml' 从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号(如下图). 但是只有英雄的名字(英文)以及对应的编号并不能找到
-
利用Python实现简单的相似图片搜索的教程
大概五年前吧,我那时还在为一家约会网站做开发工作.他们是早期创业公司,但他们也开始拥有了一些稳定用户量.不像其他约会网站,这家公司向来以洁身自好为主要市场形象.它不是一个供你鬼混的网站--是让你能找到忠实伴侣的地方. 由于投入了数以百万计的风险资本(在US大萧条之前),他们关于真爱并找寻灵魂伴侣的在线广告势如破竹.Forbes(福布斯,美国著名财经杂志)采访了他们.全国性电视节目也对他们进行了专访.早期的成功促成了事业起步时让人垂涎的指数级增长现象--他们的用户数量以每月加倍的速度增长.对他们而
-
Python对130w+张图片检索的实现方法
任务说明: 130w+张图片,8张excel表里记录了需要检索图片的文件名,现在需要找出对应的图片,将找出的图片按不同的excel分别保存,并且在excel里能够直接打开图片. 任务分析: 如果数据量不大的话,可以直接读取excel表里的文件名进行搜索保存,但这次的任务显然不合适,因为图片实在太多,所以考虑后按照以下步骤: 1.遍历图片文件夹,读取文件名和文件路径,写入到csv文件中: 2.使用pandas的merge函数,实现8张原始excel表与csv文件根据图片文件名的对碰: 3.使用sh
-
如何利用Python识别图片中的文字详解
一.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需要完成一个繁琐的工作. (1)Tesseract的安装及配置 Tesseract的安装我们可以移步到该网址 https://digi.bib.uni-mannheim.de/tesseract/,我们可以看到如下界面: 有很多版本供大家选择,大家可以根据自己的需求选择.其中w32表示32
-
使用python如何删除同一文件夹下相似的图片
前言 最近整理图片发现,好多图片都非常相似,于是写如下代码去删除,有两种方法: 注:第一种方法只对于连续图片(例一个视频里截下的图片)准确率也较高,其效率高:第二种方法准确率高,但效率低 方法一:相邻两个文件比较相似度,相似就把第二个加到新列表里,然后进行新列表去重,统一删除. 例如:有文件1-10,首先1和2相比较,若相似,则把2加入到新列表里,再接着2和3相比较,若不相似,则继续进行3和4比较-一直比到最后,然后删除新列表里的图片 代码如下: #!/usr/bin/env python #
-
python opencv通过按键采集图片源码
一.python版本 写了个python opencv的小demo,可以通过键盘按下字母s进行采集图像. 功能说明 "N" 新建文件夹 data/ 用来存储图像 "S" 开始采集图像,将采集到的图像放到 data/ 路径下 "Q" 退出窗口 python opencv源码 ''' "N" 新建文件夹 data/ 用来存储图像 "S" 开始采集图像,将采集到的图像放到 data/ 路径下 "Q&qu
-
Python如何生成随机高斯模糊图片详解
高斯模糊的介绍与原理 通常,图像处理软件会提供"模糊"(blur)滤镜,使图片产生模糊的效果. "模糊"的算法有很多种,其中有一种叫做"高斯模糊"(Gaussian Blur).它将正态分布(又名"高斯分布")用于图像处理. 所谓"模糊",可以理解成每一个像素都取周边像素的平均值. 上图中,2是中间点,周边点都是1. "中间点"取"周围点"的平均值,就会变成1.在数值
-
Python批量图片去水印的方法
平常工作中,有时为了采用网络的一些素材,但这些素材往往被打了水印,如果我们不懂PS就无法去掉水印,或者无法批量去掉水印.这些就很影响我们的工作效率. 今天我们就一起来,用Python + OpenCV三步去除水印,去水印需要使用的库:cv2.numpy.cv2是基于OpenCV的图像处理库,可以对图像进行腐蚀,膨胀等操作:numpy这是一个强大的处理矩阵和维度运算的库. 图片去水印原理 1.标定噪声的特征,使用cv2.inRange二值化标识噪声对图片进行二值化处理,具体代码:cv2.inRa
-
Python基于Opencv识别两张相似图片
在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 看到一篇博客是介绍这个,但他用的是PIL中的Image实现的,感觉比较麻烦,于是利用Opencv库进行了更简洁化的实现. 相关背景 要识别两张相似图像,我们从感性上来谈是怎么样的一个过程?首先我们会区分这两张相片的类型,例如是风景照,还是人物照.风景照中
-
Python图片处理之图片裁剪教程
一.操作流程 首先复制代码会吧? 1.有张照片 这是网上随便找的一张照片,自行保存测试 2.看看照片 运行代码,其中show_img函数是展示照片 3.选择角点 按照左上,右上,右下,左下的顺序选择四个角点 如果担心自己选不好,可以直接去除我代码里的points的注释,那是我自己用的原版 4.最终结果 二.代码分析 import 没什么好说的 #如果python没有安装cv2,那么就安装python-opencv就好 import cv2 as cv import numpy as np 获取图
-
python生成器generator:深度学习读取batch图片的操作
在深度学习中训练模型的过程中读取图片数据,如果将图片数据全部读入内存是不现实的,所以有必要使用生成器来读取数据. 通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了. 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间.在Python