基于Python正确读取资源文件
我们知道,当你把一个资源文件和一个.py文件放在一起的时候,你可以直接在这个.py文件中,使用文件名读取它。例如:
with open('test.txt') as f:
content = f.read()
print('文件中的内容为:', content)
运行效果如下图所示:

但请注意,这里我是直接运行的read.py这个文件。如果资源文件是存放在一个包(package)里面,然后我们在外面调用这个包里面的.py文件会怎么样呢?我们试一试:
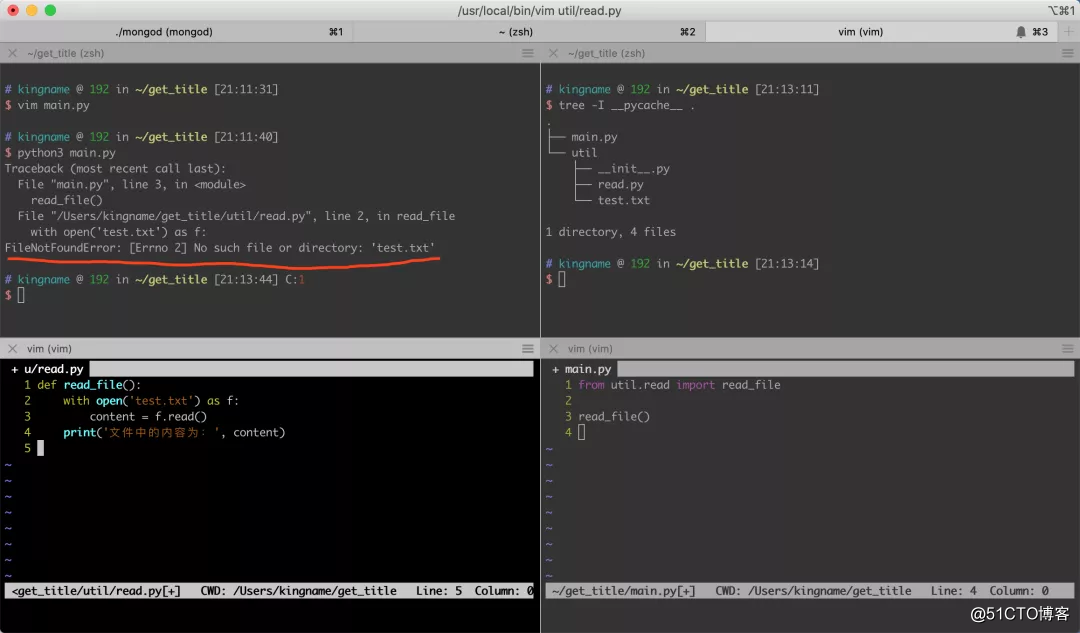
可以看到,现在Python 已经找不到这个文件了。这是因为,我们的入口程序在 ~/get_title文件夹中,而test.txt文件在~/get_title/util文件夹中。因为我们运行的是main.py,所以 Python 会在~/get_title文件夹里面寻找test.txt,自然就找不到了。
如果是引用包里面的其他模块,可以使用相对路径。例如引用同一个包里面名叫sql_util.py里面的conn对象,我们可以直接写为from .sql_util import conn。但是资源文件不能使用相对路径来读取,如下图所示:

有一个笨办法,就是获取当前正在运行的这一行代码所在的文件夹,然后拼出资源文件的完整路径。修改 read.py 文件:
import os
def read_file():
current_folder = os.path.dirname(__file__)
resource_path = os.path.join(current_folder, 'test.txt')
with open(resource_path) as f:
content = f.read()
print('文件中的内容为:', content)
运行效果如下图所示:

但这样写稍显麻烦。
如果你的 Python 版本不低于3.7,那么你可以使用importlib.resources来快速读取资源文件:
from importlib import resources
with resources.open_text('包名', '资源路径') as f:
content = f.read()
运行效果如下图所示:

如果你读取的不是文本文件,那么你可以把resources.open_text改成resources.open_binary,从而读取二进制文件。
但需要注意的是,资源文件必须放在包的根目录。这样才能正确读取。如果资源文件在包内部的子目录中,importlib.resources是不能直接读取的。
例如我们的包为util,里面有一个文件夹叫做deep_folder,资源文件test.txt放在deep_folder中,此时,我们如果要读取这个资源文件,就必须把在deep_folder文件夹中创建一个init.py,把它也变成一个包。然后修改read.py的代码:
from importlib import resources
from . import deep_folder
def read_file():
with resources.open_text(deep_folder, 'test.txt') as f:
content = f.read()
print('文件中的内容为:', content)
把deep_folder作为一个 module 导入,然后把这个 module 作为resources.open_text的第一个参数。这样才能正确读取,如下图所示:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python读取yaml文件的详细教程
yaml简介 1.yaml [ˈjæməl]: Yet Another Markup Language :另一种标记语言.yaml 是专门用来写配置文件的语言,非常简洁和强大,之前用ini也能写配置文件,看了yaml后,发现这个更直观,更方便,有点类似于json格式.在自动化测试用的相当多所以需要小伙伴们要熟练掌握 2.yaml基本语法规则: 大小写敏感 使用缩进表示层级关系 缩进时不允许使用Tab键,只允许使用空格. 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 #表示注释,从这个字符
-
python读取yaml文件后修改写入本地实例
首先安装pip install ruamel.yaml 用于修改yaml文件 #coding:utf-8 from ruamel import yaml def up_yml(ip_server): with open('./../docker-compose-demo.yml', encoding="utf-8") as f: content = yaml.load(f, Loader=yaml.RoundTripLoader) # 修改yml文件中的参数 content['serv
-
Python 读取位于包中的数据文件
问题 你的包中包含代码需要去读取的数据文件.你需要尽可能地用最便捷的方式来做这件事. 解决方案 假设你的包中的文件组织成如下: mypackage/ __init__.py somedata.dat spam.py 现在假设spam.py文件需要读取somedata.dat文件中的内容.你可以用以下代码来完成: # spam.py import pkgutil data = pkgutil.get_data(__package__, 'somedata.dat') 由此产
-
python读取hdfs上的parquet文件方式
在使用python做大数据和机器学习处理过程中,首先需要读取hdfs数据,对于常用格式数据一般比较容易读取,parquet略微特殊.从hdfs上使用python获取parquet格式数据的方法(当然也可以先把文件拉到本地再读取也可以): 1.安装anaconda环境. 2.安装hdfs3. conda install hdfs3 3.安装fastparquet. conda install fastparquet 4.安装python-snappy. conda install python-s
-
python文件操作seek()偏移量,读取指正到指定位置操作
python 文件操作seek() 和 telll() 自我解释 file.seek()方法格式: seek(offset,whence=0) 移动文件读取指针到制定位置 offset:开始的偏移量,也就是代表需要移动偏移的字节数. whence: 给offset参数一个定义,表示要从哪个位置开始偏移:0代表从文件开头算起,1代表开始从当前位置开始算起,2代表从文件末尾开始算起.当有换行时,会被换行截断. seek()无返回值,故值为None tell() : 文科文件的当前位置,即tell是获
-
python3读取autocad图形文件.py实例
废话不多说,看代码吧! ''' 待完善. 此代码实现了,根据标注文本的 属性,数值,位置,及 容差, 去判断 设计 和 实测两图中的同一位置的尺寸. 如果是同一位置的尺寸,则进行比较, 并把结果存成表格,到运行此代码的当前目录. 此代码运行时,要读取的 dwg文件 必须处于打开状态. 且 不能在 移动(pan) 模式. 启动代码: python dwg_measurements_comparison4.py [8] 其中,8代表,判定两图尺寸为同一尺寸的最大距离, 单位:米(图上单位).自己决定
-
Python实现读取并写入Excel文件过程解析
需求是有两个Excel文件:1.xlsx,2.xlsx,比较2.xlsx中的A,B列和1.xlsx中的A,B列:查找1.xlsx中存在,2.xlsx中不存在的行数据,输出到result.xlsx文件中 1.xlsx内容如下 2.xlsx内容如下 上代码 # coding=utf-8 import xlrd import xlwt # 打开文件 #data = xlrd.open_workbook('./附件7:溶洞钻孔.埋管.注浆.xlsx') # 查看工作表 #data.sheet_names
-
Python自动化测试中yaml文件读取操作
什么是yaml 一种标记语言.yaml 是专门用来写配置文件的语言,非常简洁和强大 更直观,更方便,有点类似于json格式 yaml文件格式:test.yaml 安装yaml pip install pyyaml yaml基本语法规则 大小写敏感 使用缩进表示层级关系 缩进时不允许使用Tab键,只允许使用空格. 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可 #表示注释,从这个字符一直到行尾,都会被解析器忽略,这个和python的注释一样 键值对(dict) yaml文件 user: ad
-
python3 循环读取excel文件并写入json操作
文件内容: excel内容: 代码: import xlrd import json import operator def read_xlsx(filename): # 打开excel文件 data1 = xlrd.open_workbook(filename) # 读取第一个工作表 table = data1.sheets()[0] # 统计行数 n_rows = table.nrows data = [] # 微信文章属性:wechat_name wechat_id title abstr
-
基于Python正确读取资源文件
我们知道,当你把一个资源文件和一个.py文件放在一起的时候,你可以直接在这个.py文件中,使用文件名读取它.例如: with open('test.txt') as f: content = f.read() print('文件中的内容为:', content) 运行效果如下图所示: 但请注意,这里我是直接运行的read.py这个文件.如果资源文件是存放在一个包(package)里面,然后我们在外面调用这个包里面的.py文件会怎么样呢?我们试一试: 可以看到,现在Python 已经找不到这个文件
-

浅谈Python xlwings 读取Excel文件的正确姿势
使用Python加载最新的Excel读取类库xlwings可以说是Excel数据处理的利器,但使用起来还是有一些注意事项,否则高大上的Python会跑的比老旧的VBA还要慢. 这里我们对比一下,用几种不同的方法,从一个Excel表格中读取一万行数据,然后计算结果,看看他们的耗时. 1. 处理要求: 一个Excel表格中包含了3万条记录,其中B,C两个列记录了某些计算值,读取前一万行记录,将这两个列的差值进行计算,然后汇总得出差的和. 文件是这个样子:Book300s.xlsx . 2. 处理方式
-
基于python实现cdn日志文件导入mysql进行分析
目录 一.本文需求背景 二.需求落地如下 三.自定义查询 一.本文需求背景 周六日出现CDN大量请求,现需要分析其请求频次与来源,查询是否存在被攻击问题. 本文以阿里云CDN日志作为辅助查询数据,其它云平台大同小异. 系统提供的离线日志如下所示: 二.需求落地如下 日志实例如下所示: [9/Jun/2015:01:58:09 +0800] 10.10.10.10 - 1542 "-" "GET http://www.aliyun.com/index.html" 20
-
python简单读取大文件的方法
本文实例讲述了python简单读取大文件的方法.分享给大家供大家参考,具体如下: Python读取大文件(GB级别)采用的办法很简单: with open(...) as f: for line in f: <do something with line> 例如: with open(filepath,'r') as infile: for line in infile: print line 一切都交给python解释器处理,读取效率很高,且占用资源少. stackoverflow参考链接:
-
基于python批量处理dat文件及科学计算方法详解
摘要:主要介绍一些python的文件读取功能,文件内容修改,文件名后缀更改等操作. 批处理文件功能 import os path1 = 'C:\\Users\\awake_ljw\\Documents\\python for data analysis\\test1' path2 = 'C:\\Users\\awake_ljw\\Documents\\python for data analysis\\test2' filelist = os.listdir(path1) for files i
-
使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3
-
基于JavaBean编辑器读取peroperties文件的实例
引言 最近在重读<精通Spring+4.x++企业应用开发实战>这本书,看到了有关JavaBean编辑器的部分,了解到PropertyEditor和BeanInfo的使用.不得不说,BeanInfo是一个很强大的东西,Java中的内省也与之有一点点小关联. JavaBean.PropertyEditor与BeanInfo JavaBean简单介绍 JavaBean是一种Java写成的可重用组件,本质上还是一个Java类,但是与一般的Java类不同,JavaBean必须有一个无参的构造函数,其字
-
Python实现读取TXT文件数据并存进内置数据库SQLite3的方法
本文实例讲述了Python实现读取TXT文件数据并存进内置数据库SQLite3的方法.分享给大家供大家参考,具体如下: 当TXT文件太大,计算机内存不够时,我们可以选择按行读取TXT文件,并将其存储进Python内置轻量级splite数据库,这样可以加快数据的读取速度,当我们需要重复读取数据时,这样的速度加快所带来的时间节省是非常可观的,比如,当我们在训练数据时,要迭代10万次,即要从文件中读取10万次,即使每次只加快0.1秒,那么也能节省几个小时的时间了. #创建数据库并把txt文件的数据存进
-
Java实现的读取资源文件工具类ResourcesUtil实例【可动态更改值的内容】
本文实例讲述了Java实现的读取资源文件工具类ResourcesUtil.分享给大家供大家参考,具体如下: package com.gcloud.common; import java.io.Serializable; import java.text.MessageFormat; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Locale; impor