SQL Server中的XML数据类型详解
目录
- 一、创建测试数据,指定字段数据类型为XML
- 1、创建表
- 2、插入测试数据
- 3、插入XML文件数据
- 4、创建索引
- 二、查询XML数据
- 1、query(XPath条件):返回xml 类型的节点内容
- 2、value(XPath条件,数据类型):返回标量值
- 3、exist(XPath条件):返回是否存在
- 4、nodes(XPath条件):返回由符合条件的节点组成的多行一列的结果表
- 三、modify():修改XML修改XML字段
- 1、modify(insert)增加节点
- 2、modify(delete )删除节点
- 3、modify(replace value of) --更新单个节点
- 四、for xml子句:表数据自动生成xml格式
- 1、raw模式
- 2、auto模式:表名作为元素名、生成简单的层次结构
- 3、path模式
SQL Server从2005起开始支持xml类型,这个数据类型对于后期的改变非常有用。一对多的关系在后期变成了多对多的关系,XML类型就是一个不错的选择。
一、创建测试数据,指定字段数据类型为XML
1、创建表
--创建表,包含Xml类型列
CREATE TABLE Person
(
Id int,
Info xml
)
2、插入测试数据
--插入3条测试数据 INSERT Person VALUES(1,'<Person><ID>1</ID><Name>刘备</Name></Person>') INSERT Person VALUES(2,'<Person><ID>2</ID><Name>关羽</Name></Person>') INSERT Person VALUES(3,'<Person><ID>3</ID><Name>张飞</Name></Person>')

3、插入XML文件数据
insert Person values(4,select * from openrowset(bulk 'G:\Document\XMLDocument\x3.xml',single_clob) as x)
4、创建索引
--XML“主”索引
create primary xml index IX_Person_Info
on Person ( Info );
--XML“路径”辅助索引
create xml index IX_Person_Info_Path
on Person ( Info )
using xml index IX_Person_Info for path;
--XML“属性”辅助索引
create xml index IX_Person_Info_Property
on Person ( Info )
using xml index IX_Person_Info for property;
--XML“内容”辅助索引
create xml index IX_Person_Info_value
on Person ( Info )
using xml index IX_Person_Info for value;
二、查询XML数据
T-SQL 支持用于查询 XML 数据类型的 XQuery 语言。
XQuery 基于现有的 XPath 查询语言,并支持更好的迭代、更好的排序结果以及构造必需的 XML 的功能。
1、query(XPath条件):返回xml 类型的节点内容
--查询节点内容query()方法
SELECT Id,Info.query('(/Person/Name)[1]') FROM Person WHERE ID = 2

复杂查询
declare @myxml xml
set @myxml='<people>
<student id="201301">
<Name>王五</Name>
<Age>18</Age>
<Address>湖南</Address>
</student>
<student id="201302">
<Name>李一</Name>
<Age>20</Age>
<Address>湖北</Address>
</student>
</people>'
select @myxml.query('
for $ss in /people/student
where $ss/Age[text()]<22
return element Res
{
(attribute age{data($ss/Age[text()[1]])})
}')
结果为: <Res age="18" /><Res age="20" />
一个完整实例:
declare @x xml;
set @x = '
<root>
<people id="001">
<student id="1">
<name>彪</name>
<name>阿彪</name>
<type>流氓</type>
</student >
</people>
<people id="002">
<student id="2">
<name>光辉</name>
<name>二辉</name>
<type>流氓</type>
</student >
</people>
<people id="001">
<student id="3">
<name>小德</name>
<name>小D</name>
<type>臭流氓</type>
</student >
</people>
</root>';
--1、取root的所有子节点
select @x.query('root'), @x.query('/root'), @x.query('.');
--/*注释:
-- 这里实际上是取所有节点,root 必须是最高级节点名称,当换成任意子节点都是取不到值的
--*/
--2、取 student 的所有子节点,不管 student 在文档中的位置。
select @x.query('//student ');
--3、取people下 所有 name
select @x.query('//people//name');
--4、取属性为id 的所有节点
select @x.query('//student [@id]');
/*注释:
XQuery不支持直接顶级 attribute 节点,必须附带上对节点的查找
属性必须要加[]
*/
--5、选取属于 root 子元素的第一个 people 元素。
select @x.query('/root/people[1]');
--6、选取属于 root 子元素的最后一个 people 元素。
select @x.query('/root/people[last()]');
--7、选取属于 root 子元素的倒数第二个 people 元素。
select @x.query('/root/people[last()-1]');
--8、选取最前面的两个属于 root 元素的子元素的 people 元素。
select @x.query('/root/people[position()<3]');
--9、选取 root 元素的所有 student 元素,且其中的属性 id 的值须大于 1。
select @x.query('/root//student [@id>1]');
----10、 root 元素的所有 student 元素,且其中的属性 id 的值须大于 1 并且子节点 name 的值为 光辉 的。
select @x.query('/root/people[./student [@id>1 and name="光辉"]]');
--11、选取 root 子元素的所有 people 元素,且 属性id 的值须大于 为001 子元素student 属性 id 的值为 1的
select @x.query('/root/people[@id="001" and ./student [@id=1]]');
--12、if then else 表达式
select @x.query('
if ( 1=2 ) then
/root/people[@id="001"]
else
/root/people[@id="002"]
');
--13、路径表达式步骤中的谓词
select @x.query('/root/people[1]/student /name'); --选择第一个 /root/people 节点下的所有 <Name> 元素。
select @x.query('/root/people/student [1]/name'); --选择 /root/people/student 节点下的所有 <Name> 元素。
select @x.query('/root/people/student /name[1]'); --选择 /root/people/student 节点下的所有第一个 <Name> 元素。
select @x.query('(/root/people/student /name)[1]');
--选择 /root/people/student 节点下的第一个 <Name> 元素。
--14、使用聚合函数
select @x.query('count(/root/people/student /name)'), @x.query('count(/root/people/student /name[1])');
--15、FLWOR 迭代语法。FLWOR 是 for、let、where、order by 和 return 的缩写词。
--1
select @x.query('
<result>
{ for $i in /root/people/student /name[1]
return string($i)
}
</result>');
--<result>彪 光辉 小德</result>
--2
select @x.query('
for $Loc in /root/people/student ,
$FirstStep in $Loc/name[1]
return
string($FirstStep)
');
--彪 光辉 小德
--3
select @x.query('
for $i in /root/people/student
order by $i/@id descending
return string($i/name[1])
');
--小德 光辉 彪
--4
select @x.query('
for $i in /root/people/student
order by local-name($i)
return string($i/name[1])
');
--彪 光辉 小德
2、value(XPath条件,数据类型):返回标量值
该方法对xml执行XQuery查询,返回SQL类型的标量值。xpath条件结果必须唯一。
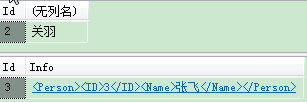
SELECT Id,Info.value('(/Person/Name)[1]','VARCHAR(50)') FROM Person WHERE ID = 2
SELECT * FROM Person WHERE Info.value('(/Person/Name)[1]','VARCHAR(50)') = '张飞'
3、exist(XPath条件):返回是否存在
结果为布尔值; 表示节点是否存在,如果执行查询的 XML 数据类型实例包含NULL则返回NULL。
SELECT * FROM Person WHERE Info.exist('(/Person/Name)[1]') = 1
一个完整实例:
--1、判断 student 中属性 id 的值 是否为空
select @x.exist('(/root/people/student/@id)[1]');
--2、判断指定节点值是否相等
declare @xml xml = '<root><name>a</name></root>';
select @xml.exist('(/root/name[text()[1]="a"])');
--3、比较日期
--代码 cast as xs:date? 用于将值转换为 xs:date 类型,以进行比较。
--@Somedate 属性的值是非类型化的。比较时,此值将隐式转换为比较右侧的类型(xs:date 类型)。
--可以使用 xs:date() 构造函数,而不用 cast as xs:date()。
declare @a xml;
set @a = '<root Somedate = "2012-01-01Z"/>';
select @a.exist('/root[(@Somedate cast as xs:date?) eq xs:date("2012-01-01")]');
4、nodes(XPath条件):返回由符合条件的节点组成的多行一列的结果表
语法: nodes(QueryString) as table(column)
如果要将xml数据类型拆分为关系数据,使用nodes方法将非常有效,它允许用户将标识映射到新行的节点。
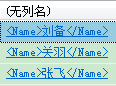
--查询节点
SELECT T2.Loc.query('.') as result
FROM Person
CROSS APPLY Info.nodes('/Person/Name') as T2(Loc)
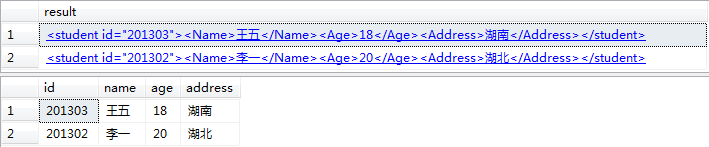
例二:-将 student节点拆分成多行
--获得所有student节点的数据,每一行显示一条student节点的数据
select T.c.query('.') as result from @myxml.nodes('/people/student') as T(c)
--将这些数据显示为一个表格
select T.c.value('(@id)[1]','int') as id,
T.c.value('(./Name)[1]','nvarchar(16)') as name,
T.c.value('(./Age)[1]','int') as age,
T.c.value('(./Address)[1]','nvarchar(16)') as address
from @myxml.nodes('/people/student') as T(c)
一个完整的实例:
--1、 对表中的 xml 数据进行解析, 节点下面有多个相同节点的 使用 cross apply 和 nodes() 方法解析
if object_id('tempdb..[#tb]') is not null
drop table [#tb];
create table [#tb]
(
[id] int ,
[name] xml
);
insert [#tb]
select 1, '<r><i>a</i><i>b</i></r>'
union all
select 2, '<r><i>b</i></r>'
union all
select 3, '<r><i>d</i></r>';
select id, T.c.query('.'), T.c.value('.', 'sysname') from [#tb] A cross apply A.name.nodes('/r/i') T(c);
--2、利用xml 拆分字符串
declare @s varchar(100) = '1,2,3,4,5,6';
select T.c.value('.', 'int') as col
from ( select cast('<x>' + replace(@s, ',', '</x><x>') + '</x>' as xml).query('.') as name ) as a
cross apply a.name.nodes('/x') T(c);
--3、取任意属性的属性值,这里引入了 sql:variable
declare @x1 xml;
select @x1 = '
<Employees Dept="IT">
<Employee Number="1001" Name="Jacob"/>
<Employee Number="1002" Name="Bob" ReportsTo="Steve"/>
</Employees>';
declare @pos int;
select @pos = 2;
select @x1.value('local-name(
(/Employees/Employee[2]/@*[position()=sql:variable("@pos")])[1] )', 'VARCHAR(20)') as AttName;
--4、将普通数据列和 xml 数据列进行合并
--sql:column() 函数
declare @t1 table
(
id int ,
data xml
);
insert into @t1 ( id, data )
select 1, '<root><name>二辉</name><type>流氓</type></root>'
union all
select 2, '<root><name>彪</name><type>流氓</type></root>';
select id, data = data.query('<root>
<id>{sql:column("id")}</id>
{/root/name}
{/root/type}
</root>') from @t1;
--5、提取长度为5的数字
--string-length() 函数 和 number() 函数
declare @t table
(
CustomerID int ,
CustomerAddress varchar(50)
);
insert into @t ( CustomerID, CustomerAddress )
select 1, '12 20 97TH STREET NEW GARDENS, NY 11415 APT 8P'
union all
select 2, '20-10 93RD STREET #8A VICTORIA NY 11106 19TH FLR'
union all
select 3, '290 BERKELEY STREET APT24D NYC, NY 10038'
union all
select 4, '351-250 345 STREET PANAMA BEACH 11414 APT4F';
with cte
as ( select CustomerID, cast('<i>' + replace(CustomerAddress, ' ', '</i><i>') + '</i>' as xml).query('.') as CustomerAddress
from @t )
select CustomerID, x.i.value('.', 'VARCHAR(10)') as ZipCode
from cte
cross apply CustomerAddress.nodes('//i[string-length(.)=5][number()>0]') x(i);
三、modify():修改XML修改XML字段
使用此方法可以修改xml数据内容。
xml数据类型的modify方法只能在update语句的set字句中使用,注意如果是针对null值调用modify方法将返回错误。
1、modify(insert)增加节点
--modify(insert)增加节点
update Person set Info.modify('
insert <Age>25</Age>
into (/Person)[1]')
where Id = 3;

实例:
--1、在 student 节点下插入 一个新节点
SET @x.modify('
insert <nickname>阿彪</nickname>
as first
into (/root/people/student)[1]
');
SELECT @x
--注释:如果某节点下面有多个节点的时候可以使用 as first 或 as last 来指定所需的新节点添加位置。
---2、在指定的 student 节点下,插入同一级节点
SET @x.modify('
insert <id>1</id>
before (/root/people/student)[1]
');
SELECT @x
--注释:是用 before 或者 after 关键字代替 into 在指定节点的 前面 或者 后面 插入同级节点
--after 关键字 和 before 关键字不能用于插入属性
--3、插入属性 一次插入多个属性值/使用变量/属性定位
DECLARE @a INT =5
SET @x.modify('
insert (
attribute a {sql:variable("@a")},
attribute b {".5"}
)
into (/root/people/student[@id=1])[1]
');
SELECT @x;
GO
2、modify(delete )删除节点
xQuery知识,没有text()就直接删除节点
UPDATE Person
SET Info.modify('
delete (/Person)[1]/Age/text()'
)
where ID = 3
实例:
-- 1、删除属性
SET @x.modify('
delete /root/people/student/@id
')
SELECT @x
-- 2、删除节点
SET @x.modify('
delete /root/people/student/name[1]
')
SELECT @x
-- 3、删除节点内容
SET @x.modify('
delete /root/people/student/type/text()
')
SELECT @x
-- 4、删除所有处理指令
SET @x.modify('
delete //processing-instruction()
')
SELECT @x
-- 5、删除所有的内容为空的节点
SET @x.modify('
delete //*[empty(./*)]
')
SELECT @x
-----------------------------------------------------------
-- 把 小D 移动到 彪 前面
------------------------------------------------------------
SET @x1.modify('
insert /people/student[@name="小D"]
before (/people/student[@name="彪"])[1]
')
SET @x1.modify ('
delete (/people/student[@name="小D"])[2]
')
SELECT @x1
------------------------------------------------------------
-- 把 野子 向前移动一级
------------------------------------------------------------
SET @x1.modify('
insert /people/student[@name="野子"]
before (/people/student[. << (/people/student[@name="野子"])[1]])[last()]
')
SET @x1.modify ('
delete /people/student[@name="野子"]
[. is (/people/student[@name="野子"])[last()]]
')
SELECT @x1
------------------------------------------------------------
-- 把 彪 向后 移一级
------------------------------------------------------------
set @x1.modify('
insert /people/student[@name="彪"]
before (/people/student[. >> (/people/student[@name="彪"])[1]])[2]
')
SELECT @x1
SET @x1.modify ('
delete (/people/student[@name="彪"])[1]
')
SELECT @x1
3、modify(replace value of) --更新单个节点
在修改语法当中 每次只能修改一个单个节点,不能批量修改或者一次修改多个值,这一点是比较郁闷的
declare @x xml;
set @x = '
<root>
<people id="001">
<student id="1" weight="80" age="25">
<name>彪</name>
<nickname>阿彪</nickname>
<type>流氓</type>
</student>
</people>
<people id="002">
<student id="2">
<name>光辉</name>
<nickname>二辉</nickname>
<type>流氓</type>
</student>
</people>
</root>';
-- 修改节点值
SET @x.modify('
replace value of (/root/people/student/name/text())[1]
with "光辉"
')
SELECT @x
-- 修改属性值
SET @x.modify('
replace value of (/root/people/student/@weight)[1]
with "70"
')
SELECT @x
-- 使用 if 表达式
SET @x.modify('
replace value of (/root/people/student/@age)[1]
with (
if (count(/root/people/student/*) > 4) then
"30"
else
"10"
)
')
SELECT @x
四、for xml子句:表数据自动生成xml格式
通过使用for xml子句,我们可以检索系统中表的数据并自动生成xml格式。一共有4种模式:RAW、AUTO、EXPLICIT、PATH。
for xml子句可以用在顶级查询和子查询中,顶级for xml子句只能出现在select语句中,子查询中的for xml子句可以出现在insert、delete、update以及赋值语句中。
1、raw模式
raw模式是这4种模式里最简单的一种。将为select语句所返回的查询结果集中的每一行转换为带有通用标记符“<row>”或可能提供元素名称的xml元素。
默认情况下,行集中非null的列都将映射为<row>元素的一个属性。这样当使用select查询时,会对结果集进行xml的转换,它们将会被转为row元素的属性。
select teacherId, teacherName from teacher where teacherSex = '女' for xml raw;
--结果:<row teacherId="4" teacherName="谢一"/>
-- <row teacherId="5" teacherName="罗二"/>
select student.id, student.name, teacher.teacherId, teacher.teacherName
from student
inner join teacher on student.teacherId = teacher.teacherId
for xml raw;
--结果: <row id="10" name="小李" teacherId="1" teacherName="王静" />
-- <row id="11" name="小方" teacherId="2" teacherName="李四" />
- 如果将 ELEMENTS 指令添加到 FOR XML 子句,则每个列值都将映射到 <row> 元素的子元素。
- 指定 ELEMENTS 指令之后,您还可以选择性地指定 XSINIL 选项以将结果集中的 NULL 列值映射到具有 xsi:nil="true" 属性的元素。
- 您可以通过向 RAW 模式指定一个可选参数为该元素指定另一个名称,如该查询中所示。SELECT * FROM #tb FOR XML RAW('流氓们')
- RAW 模式和 AUTO 模式都可以使用 ROOT , ELEMENTS XSINIL, TYPE 指令。
--> 测试数据:#tb
IF OBJECT_ID('TEMPDB.DBO.#tb') IS NOT NULL DROP TABLE #tb
CREATE TABLE #tb ( [id] INT IDENTITY PRIMARY KEY , [name] VARCHAR(4), [type] VARCHAR(10) )
INSERT #tb SELECT '中' , 'OK' UNION ALL SELECT '美' , 'NG'
--------------开始查询--------------------------
SELECT * FROM #tb FOR XML raw;--<row id="1" name="中" type="OK"/><row id="2" name="美" type="NG"/>
SELECT * FROM #tb FOR XML raw('行'),ELEMENTS;--<行><id>1</id><name>中</name><type>OK</type></行><行><id>2</id><name>美</name><type>NG</type></行>
2、auto模式:表名作为元素名、生成简单的层次结构
auto模式也是返回xml数据,它与raw的区别在于返回的xml数据中,不是以raw作为元素节点名,而是使用表名作为元素名。这个是最明显的区别。
除此之外,auto模式的结果集还可以形成简单的层次关系。
select teacherId, teacherName from teacher where teacherSex = '女' for xml auto;
--结果:<teacher teacherId="4" teacherName="谢一"/>
-- <teacher teacherId="5" teacherName="罗二"/>
select student.id, student.name, teacher.teacherId, teacher.teacherName
from student
inner join teacher on student.teacherId = teacher.teacherId
for xml auto;
/* 生成了嵌套关系
<student id="10" name="小李 ">
<teacher teacherId="1" teacherName="王静" />
</student>
<student id="11" name="小方 ">
<teacher teacherId="2" teacherName="李四" />
</student>
*/
3、path模式
--> 测试数据:#tb
if object_id('TEMPDB.DBO.#tb') is not null
drop table #tb;
create table #tb
(
[id] int identity primary key ,
[name] varchar(4) ,
[type] varchar(10)
);
insert #tb select '中', 'OK' union all select '美', 'NG';
--------------开始查询--------------------------
--1、没有名称的列
--生成此 XML。 默认情况下,针对行集中的每一行,生成的 XML 中将生成一个相应的 <row> 元素。 这与 RAW 模式相同。
select 1 for xml path;
--<row>1</row>
--2、延伸
select [name] + '' from #tb for xml path;
--select [name] + '' from #tb for xml path;
--3、去掉<row> 元素
select [name] + '' from #tb for xml path('');
--中美
--4、具有名称的列
select [name] from #tb for xml path;
--<row><name>中</name></row><row><name>美</name></row>
--5、列名以 @ 符号开头。
select id as '@id', [name] from #tb for xml path;
--<row id="1"><name>中</name></row><row id="2"><name>美</name></row>
--6、列名不以 @ 符号开头
select [name] as 臭流氓 from #tb for xml path('一群流氓');
--<一群流氓><臭流氓>中</臭流氓></一群流氓><一群流氓><臭流氓>美</臭流氓></一群流氓>
--7、列名以 @ 符号开头并包含斜杠标记 (/)
select id as '@id', [name] as '一群流氓/臭流氓' from #tb for xml path;
--<一群流氓><臭流氓>中</臭流氓></一群流氓><一群流氓><臭流氓>美</臭流氓></一群流氓>
--8、名称指定为通配符的列
--如果指定的列名是一个通配符 (*),则插入此列的内容时就像没有指定列名那样插入。
--如果此列不是 xml 类型的列,则此列的内容将作为文本节点插入
select id as '@id', [name] as '*' from #tb for xml path;
--<row id="1">中</row><row id="2">美</row>
--9、列名为 XPath 节点测试的列
--text()
--对于名为 text() 的列,该列中的字符串值将被添加为文本节点。
--comment()
--对于名为 comment() 的列,该列中的字符串值将被添加为 XML 注释。
--node()
--对于名为 node() 的列,结果与列名为通配符 (*) 时相同。
--处理指令(名称)
--如果列名为处理指令,该列中的字符串值将被添加为此处理指令目标名称的 PI 值。
select id as '@id', '臭流氓' as 'text()', '一个臭流氓' as "processing-instruction(PI)", 'chouliumang' as 'comment()', [name] as 'EmpName/text()' ,
[name] as '臭流氓/node()'
from #tb
where id = 1
for xml path;
--<row id="1">臭流氓<?PI 一个臭流氓?><!--chouliumang--><EmpName>中</EmpName><臭流氓>中</臭流氓></row>
--10、带有指定为 data() 的路径的列名
--如果被指定为列名的路径为 data(),则在生成的 XML 中,该值将被作为一个原子值来处理。
--如果序列化中的下一项也是一个原子值,则将向 XML 中添加一个空格字符。
--这在创建列表类型化元素值和属性值时很有用。 以下查询将检索产品型号 ID、名称和该产品型号中的产品列表。
select id as '@id', [name] as '@name', [name], [type] as 'data()' from #tb where id = 1 for xml path;
--<row id="1" name="中"><name>中</name>OK</row>
--11、默认情况下,列中的 Null 值映射为“缺少相应的属性、节点或元素”。
--通过使用 ELEMENTS 指令请求以元素为中心的 XML 并指定 XSINIL 来请求为 NULL 值添加元素,
--可以覆盖此默认行为,如以下查询所示:
--未指定 XSINIL,将缺少 <null> 元素。
select id as '@id', null as 'xx/null', [name] as 'xx/name', [type] as 'xx/type' from #tb for xml path;
--<row id="1"><xx><name>中</name><type>OK</type></xx></row><row id="2"><xx><name>美</name><type>NG</type></xx></row>
select id as '@id', null as 'xx/null', [name] as 'xx/name', [type] as 'xx/type' from #tb for xml path, elements xsinil;
--<row xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" id="1"><xx><null xsi:nil="true"/><name>中</name><type>OK</type></xx></row><row xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" id="2"><xx><null xsi:nil="true"/><name>美</name><type>NG</type></xx></row>
--12、ROOT/TYPE/BINARY选项
select id as '@id', [name], [type], 0x78786F6F as 'VARBINARY'
from #tb
for xml path, root('oo'), --指定向产生的 XML 中添加单个顶级元素。 可以选择指定要生成的根元素名称。 默认值为“root”。
type, --指定查询以 xml 类型返回结果。
binary base64; --如果指定 BINARY Base64 选项,则查询所返回的任何二进制数据都用 base64 编码格式表示。
--若要使用 RAW 和 EXPLICIT 模式检索二进制数据,必须指定此选项。
--在 AUTO 模式中,默认情况下将二进制数据作为引用返回。 有关使用示例,请参阅将 RAW 模式与 FOR XML 一起使用。
--<oo><row id="1"><name>中</name><type>OK</type><VARBINARY>eHhvbw==</VARBINARY></row><row id="2"><name>美</name><type>NG</type><VARBINARY>eHhvbw==</VARBINARY></row></oo>
到此这篇关于SQL Server操作XML类型的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
关于SQLServer2005的学习笔记 XML的处理
关于 xml ,难以理解的不是 SQLServer 提供的函数,而是对 xml 本身的理解,看似很简单的文件格式,处理起来却是非常困难的.本文只是初探一下而已. 详见 SQLServer 联机帮助: 主题 说明 query() 方法( xml 数据类型) 此方法用于对 XML 实例进行查询. value() 方法( xml 数据类型) 此方法用于从 XML 实例检索 SQL 类型的值. exist() 方法( xml 数据类型) 此方法用于确定查询是否返回非空结果. modify() 方法( x
-
SQLServer XML数据的五种基本操作
1.xml.exist 输入为XQuery表达式,返回0,1或是Null.0表示不存在,1表示存在,Null表示输入为空 2.xml.value 输入为XQuery表达式,返回一个SQL Server标量值 3.xml.query 输入为XQuery表达式,返回一个SQL Server XML类型流 4.xml.nodes 输入为XQuery表达式,返回一个XML格式文档的一列行集 5.xml.modify 使用XQuery表达式对XML的节点进行insert , update 和 delete
-
SQL Server中的XML数据进行insert、update、delete
SQL Server中新增加了XML.Modify()方法,分别为xml.modify(insert),xml.modify(delete),xml.modify(replace)对应XML的插入,删除和修改操作. 本文以下面XML为例,对三种DML进行说明: declare @XMLVar xml = ' <catalog> <book category="ITPro"> <title>Windows Step By Step</title&
-
SQL Server解析XML数据的方法详解
本文实例讲述了SQL Server解析XML数据的方法.分享给大家供大家参考,具体如下: --5.读取XML --下面为多种方法从XML中读取EMAIL DECLARE @x XML SELECT @x = ' <People> <dongsheng> <Info Name="Email">dongsheng@xxyy.com</Info> <Info Name="Phone">678945546</
-
SQL Server中的XML数据进行insert、update、delete操作实现代码
SQL Server中新增加了XML.Modify()方法,分别为xml.modify(insert),xml.modify(delete),xml.modify(replace)对应XML的插入,删除和修改操作. 本文以下面XML为例,对三种DML进行说明: 复制代码 代码如下: declare @XMLVar XML; SET @XMLVar= ' <catalog> <book category="ITPro"> <title>Windows
-
SQLSERVER 2005中使用sql语句对xml文件和其数据的进行操作(很全面)
--用SQL多条可以将多条数据组成一棵XML树L一次插入 --将XML树作为varchar参数传入用 --insert xx select xxx from openxml() 的语法插入数据 -----------------------------------导入,导出xml-------------------------- --1导入实例 --单个表 create table Xmltable(Name nvarchar(20),Nowtime nvarchar(20)) declare
-
SQLServer2005 XML数据操作代码
示例: 创建Table 复制代码 代码如下: CREATE TABLE [dbo].[xmlTable]( [id] [int] IDENTITY(1,1) NOT NULL, [doc] [xml] NULL ) 一.插入数据 1.通过XML文件插入 1.xml 复制代码 代码如下: <?xml version='1.0' encoding='utf-8' ?> <dd> <a id="2">dafaf2</a> <a id=&q
-

SQL Server中的XML数据类型详解
目录 一.创建测试数据,指定字段数据类型为XML 1.创建表 2.插入测试数据 3.插入XML文件数据 4.创建索引 二.查询XML数据 1.query(XPath条件):返回xml 类型的节点内容 2.value(XPath条件,数据类型):返回标量值 3.exist(XPath条件):返回是否存在 4.nodes(XPath条件):返回由符合条件的节点组成的多行一列的结果表 三.modify():修改XML修改XML字段 1.modify(insert)增加节点 2.modify(delet
-
SQL Server中的约束(constraints)详解
目录 一.约束的分类 二.约束命名 三.主键约束 1.在创建表的时候创建主键约束. 2.在已存在的表上创建主键约束 3.复合主键的创建 四.外键约束 4.1.创建表的时候创建外键 4.2.在已存在的表中添加一个外键 4.3.级联动作 五.唯一约束 主键和唯一约束的区别: 六.CHECK约束 七.DEFAULT约束 7.1在创建表时定义DEFAULT约束: 7.2在已存在的表上添加DEFAULT约束: 八.禁用约束 8.1.在创建约束时,忽略检查之前的不满足数据 8.2.临时禁用已存在的约束 九.
-
SQL Server中T-SQL 数据类型转换详解
常用的转换函数是 cast 和 convert,用于把表达式得出的值的类型转换成另一个数据类型,如果转换失败,该函数抛出错误,导致整个事务回滚.在SQL Server 2012版本中,新增两个容错的转换函数:try_cast 和 try_convert,如果转换操作失败,该函数返回null,不会导致整个事务失败,事务继续执行下去. 注意:对于SQL Server显式定义的不合法转换,try_cast 和 try_convert 会失败,抛出错误信息:Explicit conversion fro
-
SQL Server中索引的用法详解
目录 一.索引的介绍 什么是索引? 1.聚集索引和非聚集索引 2.索引的利弊 3.索引的存储机制 二.设置索引的权衡 1.什么情况下设置索引 2.什么情况下不要设置索引 三.聚集索引 1.使用SSMS创建聚集索引 2.使用T-SQL创建聚集索引 四.非聚集索引 1.SSMS创建方法同上,T-SQL创建方法如下: 2.添加索引选项 五.示例 六.管理索引 一.索引的介绍 什么是索引? 索引是一种磁盘上的数据结构,建立在表或视图的基础上.使用索引可以使数据的获取更快更高校,也会影响其他的一些性能,如
-
SQL Server中的连接查询详解
在查询多个表时,我们经常会用"连接查询".连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志. 什么是连接查询呢? 概念:根据两个表或多个表的列之间的关系,从这些表中查询数据. 目的:实现多个表查询操作. 知道了连接查询的概念之后,什么时候用连接查询呢? 一般是用作关联两张或两张以上的数据表时用的.看起来有点抽象,我们举个例子,做两张表:学生表(T_student)和班级表(T_class). T_student T_class 连接标准语法格式: SQL-9
-
SQL Server实现全文搜索查询详解
目录 一.概述 二.全文搜索查询 三.将全文搜索查询与 LIKE 谓词进行比较 四.全文搜索体系结构 4.1.SQL Server 进程 4.2.过滤器守护程序主机进程 五.全文搜索处理 5.1.全文索引过程 5.2.全文查询流程 六.全文索引体系结构 6.1.全文索引结构 6.2.全文索引片段 6.3.全文索引和常规 SQL Server 索引之间的差异 总结 一.概述 全文索引在表中包括一个或多个基于字符的列.这些列可以具有以下任何数据类型:char.varchar.nchar.nvarch
-
SQL Server 2012 FileTable 新特性详解
FileTable是基于FILESTREAM的一个特性.有以下一些功能: •一行表示一个文件或者目录. •每行包含以下信息: • •file_Stream流数据,stream_id标示符(GUID). •用户表示和维护文件及目录层次关系的path_locator和parent_path_locator •有10个文件属性 •支持对文件和文档的全文搜索和语义搜索的类型列. •filetable强制执行某些系统定义的约束和触发器来维护命名空间的语义 •针对非事务访问时,SQL Server配置FIL
-
sql server 交集,差集的用法详解
概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便. 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合. 在T-SQL中.UNION集合运算可以将两个输入查询的结果组合成一个结果集.需要注意的是:如果一个行在任何一个输入集合中出现,它也会在UNION运算的结果中出现.T-SQL支持以下两种选项: (1)UNION ALL:不会删除重复行 -- union allselect country, region, city fr
-
SQL Server批量插入数据案例详解
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题.下面介绍SQL Server支持的两种批量数据插入方法:Bulk和表值参数(Table-Valued Parameters),高效插入数据. 新建数据库: --Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create tab
-
SQL Server的行级安全性详解
目录 一.前言 二.描述 三.权限 四.安全说明:侧信道攻击 五.跨功能兼容性 六.示例 一.前言 行级别安全性使您能够使用组成员身份或执行上下文来控制对数据库表中行的访问. 行级别安全性 (RLS) 简化了应用程序中的安全性设计和编码.RLS 可帮助您对数据行访问实施限制.例如,您可以确保工作人员仅访问与其部门相关的数据行.另一个示例是将客户的数据访问限制为仅与其公司相关的数据. 访问限制逻辑位于数据库层中,而不是远离另一个应用程序层中的数据.每次尝试从任何层访问数据时,数据库系统都会应用访问