关于Python dict存中文字符dumps()的问题
Background
之前数据库只区分了Android,IOS两个平台,游戏上线后现在PM想要区分国服,海外服,港台服。这几个字段从前端那里的接口获得,code过程中发现无论如何把中文的value丢到dict中存到数据库中就变成类似这样**"\u56fd\u670d"**
Solution
1.首先怀疑数据库编码问题,但看了一下数据库其他字段有中文格式的,所以要先check数据库(MySQL)的字符编码。

可以看到明明就TMD是utf-8啊,所以一定不是数据库层出现的问题,回到代码debug
2.Google一下
这个问题好多都是Python2的解决方案,找到了一个感觉靠谱点的
dict1 = {'name':'张三'}
print(json.dumps(dict1,encoding='utf-8',ensure_ascii=False))
博客中的解法,但是我的Python版本是3.9,就会报Error如下
Exception in thread Thread-1:
Traceback (most recent call last):
File "/usr/local/python3/lib/python3.9/threading.py", line 950, in _bootstrap_inner
self.run()
File "/usr/local/python3/lib/python3.9/threading.py", line 888, in run
self._target(*self._args, **self._kwargs)
File "/home/dapan_ext/project_table.py", line 91, in http_request
self.get_data(project_response_data)
File "/home/dapan_ext/project_table.py", line 115, in get_data
json.dumps(dict_1, encoding='utf-8', ensure_ascii=False)
File "/usr/local/python3/lib/python3.9/json/__init__.py", line 234, in dumps
return cls(
TypeError: __init__() got an unexpected keyword argument 'encoding'
意思就是:在__init__json这个东东的时候它不认识'encoding'这个argument。
那就翻阅源码康康->->:
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
"""Serialize ``obj`` to a JSON formatted ``str``.
If ``skipkeys`` is true then ``dict`` keys that are not basic types
(``str``, ``int``, ``float``, ``bool``, ``None``) will be skipped
instead of raising a ``TypeError``.
If ``ensure_ascii`` is false, then the return value can contain non-ASCII
characters if they appear in strings contained in ``obj``. Otherwise, all
such characters are escaped in JSON strings.
If ``check_circular`` is false, then the circular reference check
for container types will be skipped and a circular reference will
result in an ``OverflowError`` (or worse).
If ``allow_nan`` is false, then it will be a ``ValueError`` to
serialize out of range ``float`` values (``nan``, ``inf``, ``-inf``) in
strict compliance of the JSON specification, instead of using the
JavaScript equivalents (``NaN``, ``Infinity``, ``-Infinity``).
If ``indent`` is a non-negative integer, then JSON array elements and
object members will be pretty-printed with that indent level. An indent
level of 0 will only insert newlines. ``None`` is the most compact
representation.
If specified, ``separators`` should be an ``(item_separator, key_separator)``
tuple. The default is ``(', ', ': ')`` if *indent* is ``None`` and
``(',', ': ')`` otherwise. To get the most compact JSON representation,
you should specify ``(',', ':')`` to eliminate whitespace.
``default(obj)`` is a function that should return a serializable version
of obj or raise TypeError. The default simply raises TypeError.
If *sort_keys* is true (default: ``False``), then the output of
dictionaries will be sorted by key.
To use a custom ``JSONEncoder`` subclass (e.g. one that overrides the
``.default()`` method to serialize additional types), specify it with
the ``cls`` kwarg; otherwise ``JSONEncoder`` is used.
"""
# cached encoder
if (not skipkeys and ensure_ascii and
check_circular and allow_nan and
cls is None and indent is None and separators is None and
default is None and not sort_keys and not kw):
return _default_encoder.encode(obj)
if cls is None:
cls = JSONEncoder
return cls(
skipkeys=skipkeys, ensure_ascii=ensure_ascii,
check_circular=check_circular, allow_nan=allow_nan, indent=indent,
separators=separators, default=default, sort_keys=sort_keys,
**kw).encode(obj)
注意到这里:
If ``ensure_ascii`` is false, then the return value can contain non-ASCII
characters if they appear in strings contained in ``obj``. Otherwise, all
such characters are escaped in JSON strings.
意思就是:
ensure_ascii置为false时,返回值就可以返回非ASCII编码的字符,这岂不正是我们需要的,Got it!
回去改代码:
server_name = str(related['name'])
# print(server_name)
dict_1 = {'appKey': related['appKey'], 'client': related['client'], 'name': server_name}
crasheye.append(dict_1)
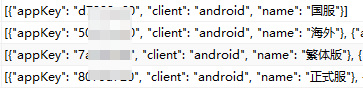
crasheyes = json.dumps(crasheye, ensure_ascii=False)
完美解决问题(●ˇ∀ˇ●)
到此这篇关于Python dict存中文字符dumps()的文章就介绍到这了,更多相关Python dict中文字符dumps()内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python3 json数据格式的转换(dumps/loads的使用、dict to str/str to dict、json字符串/字典的相互转换)
python3 json数据格式的转换(dumps/loads的使用.dict to str/str to dict.json字符串/字典的相互转换) Python3 JSON 数据解析 JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数: json.dumps(): 对数据进行编码. json.loads(): 对数据进
-
关于Python dict存中文字符dumps()的问题
Background 之前数据库只区分了Android,IOS两个平台,游戏上线后现在PM想要区分国服,海外服,港台服.这几个字段从前端那里的接口获得,code过程中发现无论如何把中文的value丢到dict中存到数据库中就变成类似这样**"\u56fd\u670d"** Solution 1.首先怀疑数据库编码问题,但看了一下数据库其他字段有中文格式的,所以要先check数据库(MySQL)的字符编码. 可以看到明明就TMD是utf-8啊,所以一定不是数据库层出现的问题,回到代码de
-
解决Python下json.loads()中文字符出错的问题
Python:2.7 IDE:Pycharm5.0.3 今天遇到一个问题,就是在使用json.load()时,中文字符被转化为Unicode码的问题,解决方案找了半天,无解.全部代码贴出,很简单的一个入门程序,抓的是有道翻译的,跟着小甲鱼的视频做的,但是他的版本是python3.4,所以有些地方还需要自己改,不多说,程序如下: import urllib#python2.7才需要两个urllib url="http://fanyi.youdao.com/translate?smartresult
-
python实现递归查找某个路径下所有文件中的中文字符
本文实例为大家分享了python实现递归查找某个路径下所有文件中的中文字符,供大家参考,具体内容如下 # -*- coding: utf-8 -*- # @ description: # @ author: # @ created: 2018/7/21 import re import sys import os reload(sys) sys.setdefaultencoding("utf8") def translate(str): out = set() line = str.s
-
python统计中文字符数量的两种方法
方法一: def str_count(str): '''找出字符串中的中英文.空格.数字.标点符号个数''' count_en = count_dg = count_sp = count_zh = count_pu = 0 for s in str: # 英文 if s in string.ascii_letters: count_en += 1 # 数字 elif s.isdigit(): count_dg += 1 # 空格 elif s.isspace(): count_sp += 1 #
-
解决python写入带有中文的字符到文件错误的问题
在python写脚本过程中需要将带有中文的字符串内容写入文件,出现了报错的现象. ---------------------------- UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) ---------------------------- 经过网上搜索出错原因得到结果: python中如果使用系统默认的open方法打开的文件只能写入asc
-
在python中pandas读文件,有中文字符的方法
后面要加encoding='gbk' import pandas as pd datt=pd.read_csv('D:\python_prj_1\data_1.txt',encoding='gbk') print(datt) 以上这篇在python中pandas读文件,有中文字符的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python 打印中文字符的三种方法
方法一: 现在用 notepad++,在 UTF-8 格式下编写以下语句: #coding=utf-8 print"打印中文字符" 方法二: 用encode和decode 如: import os.path import xlrd,sys Filename='/home/tom/Desktop/1234.xls' if not os.path.isfile(Filename): raise NameError,"%s is not a valid filename"
-
python中文字符如何转url编码
目录 如何将中文字符转url编码 python url编码和url解码方法 函数介绍 编码 解码 总结 如何将中文字符转url编码 import urllib.parse name = urllib.parse.quote('中文') python url编码和url解码方法 记录一下用python对文字的url编码和url解码方法,不对基础url编码分析 urllib库是一个python的自带库,使用的时候不需要下载,可以直接导入使用 函数介绍 函数 介绍 urllib.parse.quote
-
Python实现针对中文排序的方法
本文实例讲述了Python实现针对中文排序的方法.分享给大家供大家参考,具体如下: Python比较字符串大小时,根据的是ord函数得到的编码值.基于它的排序函数sort可以很容易为数字和英文字母排序,因为它们在编码表中就是顺序排列的. >> print ','< '1'<'A'<'a'<'阿' True 但要很处理中文就没那么容易了.中文通常有拼音和笔画两种排序方式,在最常用中文标准字符集GB2312中,3755个一级中文汉字是按照拼音序进行编码的,而3008个二级汉
-
python dict乱码如何解决
定义字典并直接输出,结果输出结果中文是乱码展示 d={'name':'lily','age':18,'sex':'女','no':1121} print d 输出结果: {'age': 18, 'no': 1121, 'name': 'lily', 'sex': '\xe5\xa5\xb3'} 解决方法: d={'name':'lily','age':18,'sex':'女','no':1121} print json.dumps(d,encoding='utf-8',ensure_ascii=