Python使用Chrome插件实现爬虫过程图解
做电商时,消费者对商品的评论是很重要的,但是不会写代码怎么办?这里有个Chrome插件可以做到简单的数据爬取,一句代码都不用写。下面给大家展示部分抓取后的数据:

可以看到,抓取的地址,评论人,评论内容,时间,产品颜色都已经抓取下来了。那么,爬取这些数据需要哪些工具呢?就两个:
1. Chrome浏览器;
2. 插件:Web Scraper
插件下载地址:https://chromecj.com/productivity/2018-05/942.html
最后,如果你想自己动手抓取一下,这里是这次抓取的详细过程:
1. 首先,复制如下的代码,对,你不需要写代码,但是为了便于上手,复制代码还是需要的,后续可以自己定制和选择,不需要写代码。
{
"_id": "jdreview",
"startUrl": [
"https://item.jd.com/100000680365.html#comment"
],
"selectors": [
{
"id": "user",
"type": "SelectorText",
"selector": "div.user-info",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "comments",
"type": "SelectorText",
"selector": "div.comment-column > p.comment-con",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "time",
"type": "SelectorText",
"selector": "div.comment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type(4)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": "0"
},
{
"id": "color",
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "main",
"type": "SelectorElementClick",
"selector": "div.comment-item",
"parentSelectors": [
"_root"
],
"multiple": true,
"delay": "10000",
"clickElementSelector": "div.com-table-footer a.ui-pager-next",
"clickType": "clickMore",
"discardInitialElements": false,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2. 然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹出的窗口中找到Web Scraper,如下:
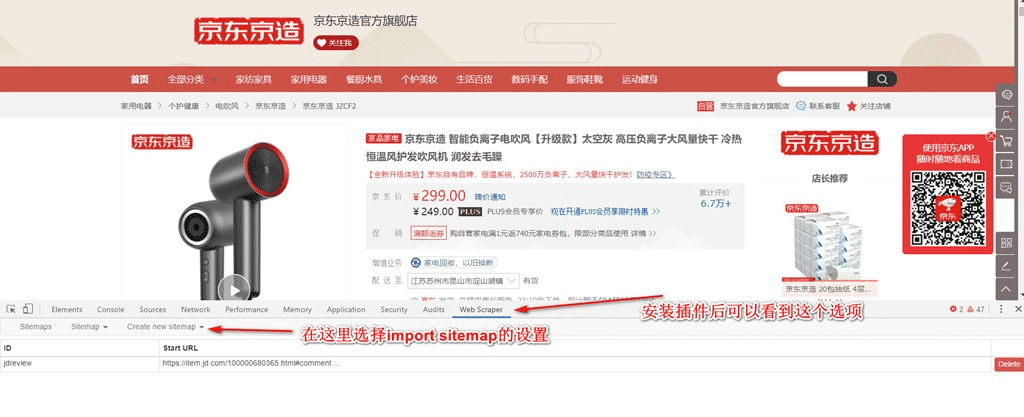
3. 如下
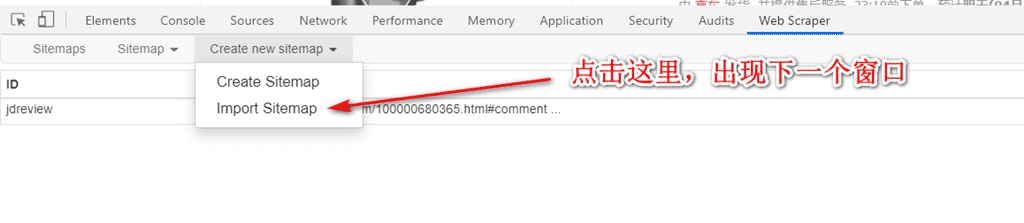
4. 如图,粘贴上述的代码:

5. 如图,如果需要定制网址,注意替代一下,网址后面的#comment是直达评论的链接,不能去掉:

6. 如图:

7. 如图:
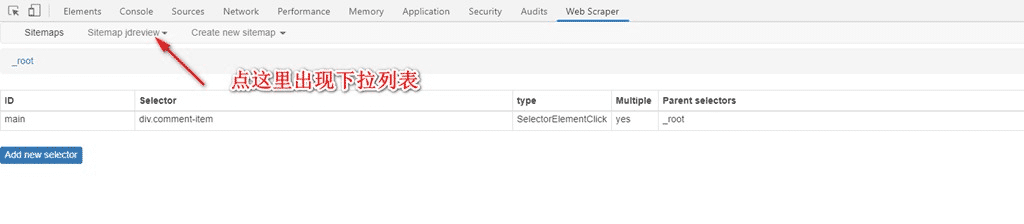
8. 如图,点击Scrape后,会自动运行打开需要抓取得页面,不要关闭窗口,静静等待完成,完成后右下方会提示完成,一般1000条以内的评论不会有问题:
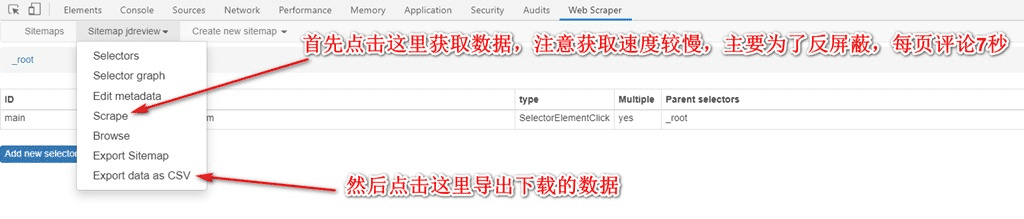
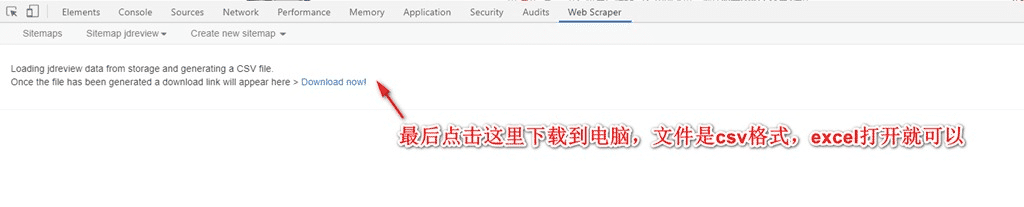
9. 最后,点击下载到电脑,数据保存好。
使用这个工具的好处是:
1. 不需要编程;
2. 京东的评论基本可以通用此脚本,修改对应的url即可;
3. 如果需要爬取的评论不到1000条,这个工具会非常称手,所有的数据完全自动下载;
使用的注意点:
1. 抓取过一次的数据会有记录,立刻再次抓取将不会保存,建议关闭浏览器重新打开后再试;
2. 抓取数量:1000条以内没有问题,可能是京东按照IP直接阻止了更多的爬取;
如果你的英语水平不错,可以尝试阅读官方文档,进一步学习和定制自己的爬虫。
官方教程:https://www.webscraper.io/documentation
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python3爬虫怎样构建请求header
写一个爬虫首先就是学会设置请求头header,这样才可以伪装成浏览器.下面小编我就来给大家简单分析一下python3怎样构建一个爬虫的请求头header. 1.python3跟2有了细微差别,所以我们先要引入request,python2没有这个request哦.然后复制网址给url,然后用一个字典来保存header,这个header怎么来的?看第2步. 2.打开任意浏览器某一页面(要联网),按f12,然后点network,之后再按f5,然后就会看到"name"这里,我们点击name里
-
通过python爬虫赚钱的方法
(1)在校大学生.最好是数学或计算机相关专业,编程能力还可以的话,稍微看一下爬虫知识,主要涉及一门语言的爬虫库.html解析.内容存储等,复杂的还需要了解URL排重.模拟登录.验证码识别.多线程.代理.移动端抓取等.由于在校学生的工程经验比较少,建议找一些少量数据抓取的项目,而不要去接一些监控类的项目.或大规模抓取的项目.慢慢来,步子不要迈太大. (2)在职人员.如果你本身就是爬虫工程师,挣钱很简单.如果你不是,也不要紧.只要是做IT的,稍微学习一下爬虫应该不难.在职人员的优势是熟悉项目开发流程
-
Python爬虫文件下载图文教程
而今天我们要说的内容是:如果在网页中存在文件资源,如:图片,电影,文档等.怎样通过Python爬虫把这些资源下载下来. 1.怎样在网上找资源: 就是百度图片为例,当你如下图在百度图片里搜索一个主题时,会为你跳出一大堆相关的图片. 还有如果你想学英语,找到一个网站有很多mp3的听力资源,这些可能都是你想获取的内容. 现在是一个互联网的时代,只要你去找,基本上能找到你想要的任何资源. 2.怎样识别网页中的资源: 以上面搜索到的百度图片为例.找到了这么多的内容,当然你可以通过手动一张张的去保存,但这样
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-

Python爬虫实战之12306抢票开源
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 余票查询界面 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-2
-
Python爬虫实现获取动态gif格式搞笑图片的方法示例
本文实例讲述了Python爬虫实现获取动态gif格式搞笑图片的方法.分享给大家供大家参考,具体如下: 有时候看到一些喜欢的动图,如果一个个取保存挺麻烦,有的网站还不支持右键保存,因此使用python来获取动态图,就看看就很有意思了 本次爬取的网站是 居然搞笑网 http://www.zbjuran.com/dongtai/list_4_1.html 思路: 获取当前页面内容 查找页面中动图所代表的url地址 保存这个地址内容到本地 如果想爬取多页,就可以加上一个循环条件 代码: #!/usr/
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带
-
Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每
-
Python使用Chrome插件实现爬虫过程图解
做电商时,消费者对商品的评论是很重要的,但是不会写代码怎么办?这里有个Chrome插件可以做到简单的数据爬取,一句代码都不用写.下面给大家展示部分抓取后的数据: 可以看到,抓取的地址,评论人,评论内容,时间,产品颜色都已经抓取下来了.那么,爬取这些数据需要哪些工具呢?就两个: 1. Chrome浏览器: 2. 插件:Web Scraper 插件下载地址:https://chromecj.com/productivity/2018-05/942.html 最后,如果你想自己动手抓取一下,这里是这次
-
基于Python开发chrome插件的方法分析
本文实例讲述了基于Python开发chrome插件的方法.分享给大家供大家参考,具体如下: 谷歌Chrome插件是使用HTML.JavaScript和CSS编写的.如果你之前从来没有写过Chrome插件,我建议你读一下这个.在这篇教程中,我们将教你如何使用Python代替JavaScript. 创建一个谷歌Chrome插件 首先,我们必须创建一个清单文件:manifest.json. { "manifest_version": 2, "name": "Py
-
Python爬取阿拉丁统计信息过程图解
背景 目前项目在移动端上,首推使用微信小程序.各项目的小程序访问数据有必要进行采集入库,方便后续做统计分析.虽然阿拉丁后台也提供了趋势分析等功能,但一个个的获取数据做数据分析是很痛苦的事情.通过将数据转换成sql持久化到数据库上,为后面的数据分析和展示提供了基础. 实现思路 阿拉丁产品分开放平台和统计平台两个产品线,目前开放平台有api及配套的文档.统计平台api需要收费,而且贼贵.既然没有现成的api可以获取数据,那么我们尝试一下用python抓取页面上的数据,毕竟python擅长干这种事情.
-
Python数据可视化实现漏斗图过程图解
项目实现知识点: Pandas库及pyecharts库 Pandas:数据分析和处理工具. pd.read_csv():读取csv文件. pyecharts:绘图库,提供30多种图标,超过400个以上的地图文件,支持原生百度地图,为地理数据可视化提供支持. pyecharts.charts:提供了基本的图表,例如条形图.直方图等. Python数据可视化:漏斗图的制作 项目实现过程: 1.导入模块 2.打开文件 3.读取数据 4.整理数据 5.创建漏斗图 6.添加组件 7.显示漏斗并设置名称 8
-
Python虚拟环境virtualenv创建及使用过程图解
virtualenv 是用来创建一个虚拟的python环境的第三方包,一个专属于项目的python环境. 安装virtualenv(请确保python和pip成功安装): pip3 install virtualenv 创建python虚拟环境: virtualenv [虚拟环境名称] # 会在当前目录下生成一个对应的文件夹 virtualenv -p /usr/bin/python [虚拟环境名称] # 指定python解释器版本 进入python虚拟环境: Linux系统: cd my-en
-
基于python爬取有道翻译过程图解
1.准备工作 先来到有道在线翻译的界面http://fanyi.youdao.com/ F12 审查元素 ->选Network一栏,然后F5刷新 (如果看不到Method一栏,右键Name栏,选中Method) 输入文字自动翻译后发现Method一栏有GET还有POST:GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据. 随便打开一个POST,找到preview可以看到我们输入的"我爱你一生一世"数据,可以证明post的提交数据的 下面分析一下Header
-
jenkins配置python脚本定时任务过程图解
这篇文章主要介绍了jekins配置python脚本定时任务过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.首先安装jekins环境,访问网页https://jenkins.io/zh/download/,下载长期稳定版如下: 2.下载安装包后直接运行,进行选择安装路径,傻瓜式安装.安装完成后,点Finished,弹出jekins输入密匙网页,根据网页提示路径,找到 对应的jekins密匙输入后,选择推荐插件安装即可.(也可以不安装插
-
Python爬虫过程解析之多线程获取小米应用商店数据
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于IT共享之家 ,作者IT共享者 前言 小米应用商店给用户发现最好的安卓应用和游戏,安全可靠,可是要下载东西要一个一个地搜索太麻烦了.而且速度不是很快. 今天用多线程爬取小米应用商店的游戏模块.快速获取. 二.项目目标 目标 :应用分类 - 聊天社交 应用名称, 应用链接,显示在控制台供用户下载. 三.涉及的库和网站 1.网址:百度搜 - 小米应用商店,进入官网. 2.涉及的库:re
-
Python远程开发环境部署与调试过程图解
这篇文章主要介绍了Python远程开发环境部署与调试过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.下载相应开发工具 Pycharm :下载地址 二.部署开发机 一般在工作过程中,开发环境并不是本地环境,而是指在开发机:因为,有很多依赖本地部署非常麻烦,而开发机中则内置了很多相关的服务 三.代码自动化部署 由于我们在本地进行代码编辑.在开发机中进行代码的运行及调试,因此,需要一种很方便的方式进行代码的远程自动化部署Pycharm 基
-
Python搭建HTTP服务过程图解
这篇文章主要介绍了Python搭建HTTP服务过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 我们平时可能会需要HTTP服务,本机搭建一个服务器来完成有些过于繁琐,这时就可以用python帮我们搭建一个HTTP服务器,省时高效. python 2.x 输入命令:python -m SimpleHTTPServer 8000(8000为端口号,如果不指定则默认8000端口) python 3.x 输入命令:python -m http.s