Python+tkinter实现高清图片保存
目录
- 前言
- 基本开发环境
- 分析网页
- 开始工作
- 实现
- 全部代码
作为爱玩电脑的你是不是也需要经常更换一下自己的电脑壁纸呢? 换上一张心仪的图片整个人都舒畅多了。但是在网上有很多心仪的图片想要保存下来,如果一张张的去保存那效率又低,而后面的壁纸很有很多好看的又没有时间去看,这样就让我们错过了很多好看的壁纸,我们从从网站上一个一个下载实在太麻烦。

于是我用Python写一个保存图片的功能,把我们的图片给保存到我们的电脑,这样就可以浏览哪张好看就换哪张,不用再去慢慢保存了。

提示:以下是本篇文章正文内容,下面案例可供参考
前言
Python的学习先从基础开始,给自己找任务多给自己实践的机会只有实践才能悟出道理,因为实践练习才是学习的最好方式。
基本开发环境
pycharm
Python 3.8
主要相关模块
request,BeautifulSoup,tkinter(Python内置库,直接导入即可)
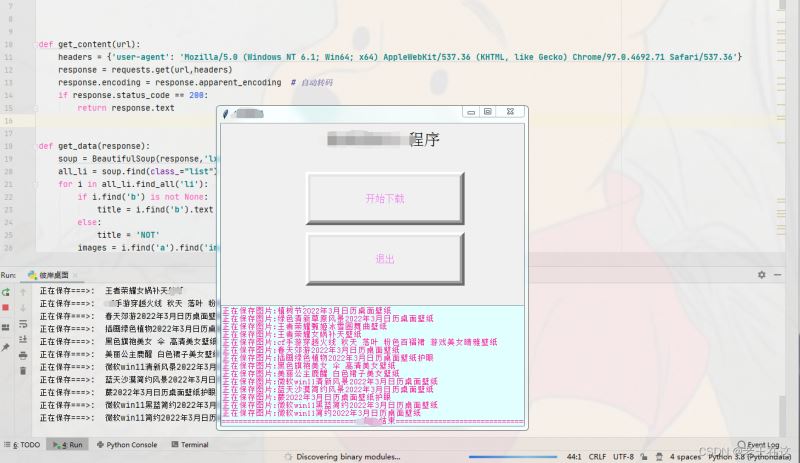
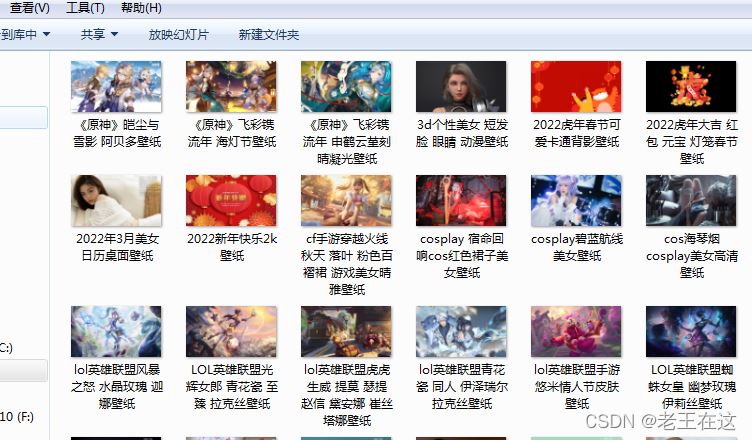
先看一下(Python+tkinter(图形化界面设计))最终效果吧,高清大图保存到本地电脑了,
(现在只需要在控制台输入pyinstaller -F -w 自己的py文件名.py)就可以就能打包成exe放到桌面了。
分析网页
在爬取之前第一步还是先对网页进行分析,确定网页是静态的还是动态的,知己知彼才好下手,是吧!以避开爬取难点,节约时间。
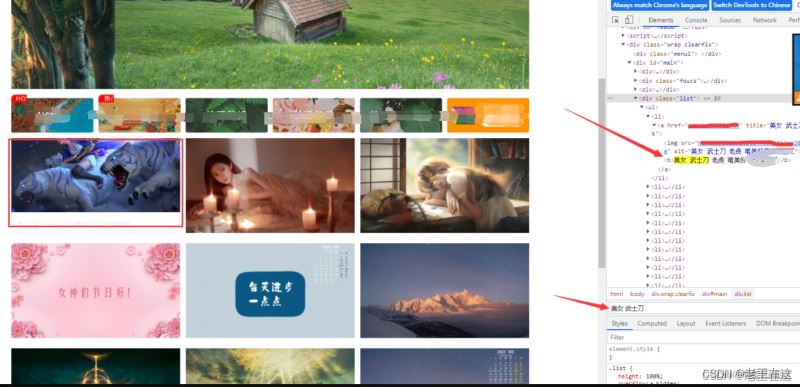
我们打开网页右键检查输入关键字发现可以找到图片的信息,我们大致可以确定这个网站是静态的。那么我们就可以根据普通的方法对网页进行抓取。
开始工作
1.1
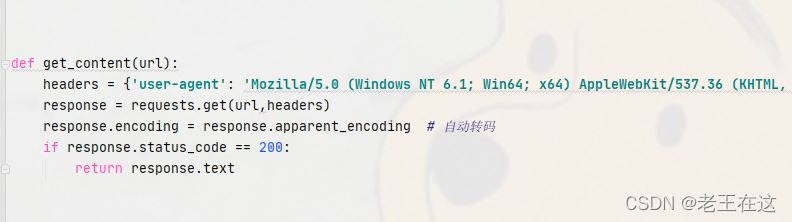
先是构造个伪造头防止简单的的反爬,然后对网页发起请求,如果我请求的对象得到的状态码是200(成功访问)那么就返回text文本给我。
1.2
网页请求成功之后我们就可以在网页分析图片存放的位置在哪。
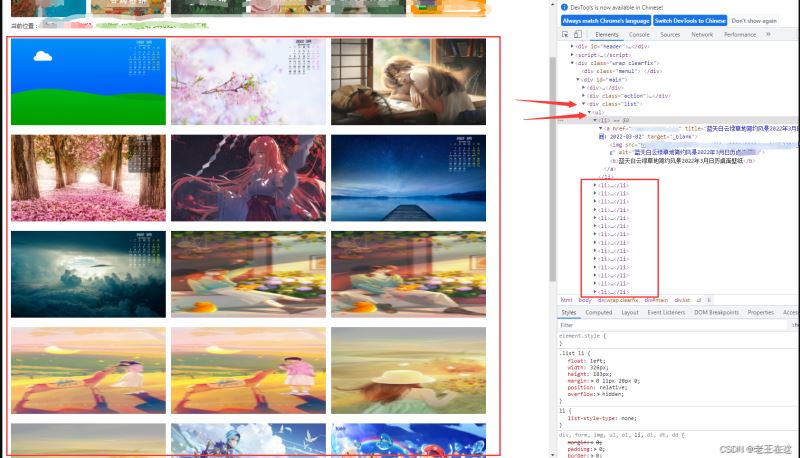
通关观察发现,我们要的图片储存在标签div class=‘list’下面的ul标签,ul标签下面li全部是我们需要的图片。位置我们找到了那么接下来就实例化一个soup对象来找到所有的li标签,紧接着循环每个li标签,获取li标签里边标签b获取图片的名字,然后再到img标签src这个属性提取图片链接。

下面代码演示。

1.3
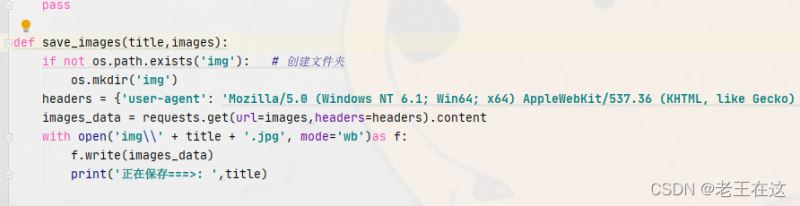
图片的名字和图片的链接都有了,接下来就是创建存放位置,因为图片是二进制数据,所以以content的方式请求,最后以wb的形式写入文件夹。
分析网页我们不难发现页面翻页的规律,只要循环一下就能实现,页面翻页实现翻页爬取。(想要更多翻页自己改数字吧)
index_2.htm
index_3.htm
index_4.htm
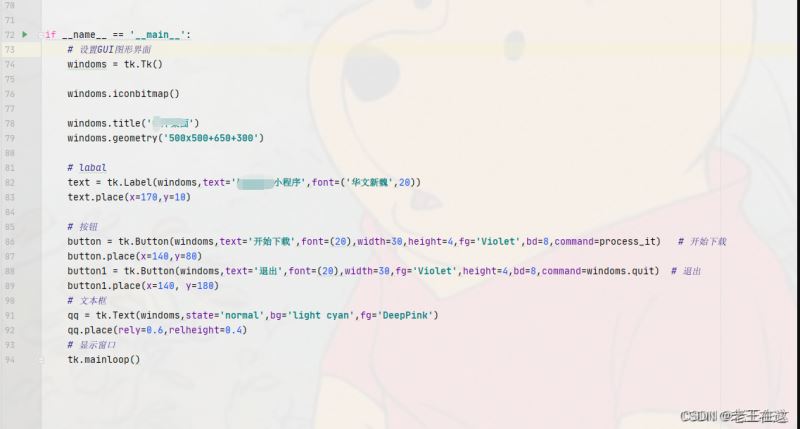
最后就是设置一下tkinter图形化界面(这里不再过多详解,可以上博客查看),设计与程序结合一下就完成了。
实现
全部代码
# @Author : 王同学
import requests
from bs4 import BeautifulSoup
import os
import tkinter as tk # GUI
import concurrent.futures
import threading
def get_content(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
response = requests.get(url,headers)
response.encoding = response.apparent_encoding # 自动转码
if response.status_code == 200:
return response.text
def get_data(response):
soup = BeautifulSoup(response,'lxml')
all_li = soup.find(class_="list").find('ul')
for i in all_li.find_all('li'):
if i.find('b') is not None:
title = i.find('b').text
else:
title = 'NOT'
images = i.find('a').find('img').get('src')
save_images(title,images)
def save_csv():
pass
def save_images(title,images):
if not os.path.exists('img'): # 创建文件夹
os.mkdir('img')
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
images_data = requests.get(url=images,headers=headers).content
with open('img\\' + title + '.jpg', mode='wb')as f:
f.write(images_data)
print('正在保存===>: ',title)
# GUI文本框输入
qq.insert(tk.INSERT,"正在保存图片:" + title + '\n')
qq.yview_moveto(1)
qq.update()
def main():
print('===================已经点击按钮===========================')
for i in range(2,11):
url = f'http://www.netbian.com/index_{i}.htm' # 循环
qq.insert(tk.INSERT,f'==========================正在保存第{i}页的图片=========================='+ '\n')
qq.update()
print(f'============================正在保存第{i}页的数据内容========================')
response = get_content(url)
get_data(response)
qq.insert(tk.INSERT,'=================================保存结束================================')
# 多线程 防止GUI卡死
def process_it():
it = threading.Thread(target=main)
it.setDaemon(True)
it.start()
if __name__ == '__main__':
# 设置GUI图形界面
windoms = tk.Tk()
windoms.iconbitmap()
windoms.title('图片')
windoms.geometry('500x500+650+300')
# labal
text = tk.Label(windoms,text='图片小程序',font=('华文新魏',20))
text.place(x=170,y=10)
# 按钮
button = tk.Button(windoms,text='开始下载',font=(20),width=30,height=4,fg='Violet',bd=8,command=process_it) # 开始下载
button.place(x=140,y=80)
button1 = tk.Button(windoms,text='退出',font=(20),width=30,fg='Violet',height=4,bd=8,command=windoms.quit) # 退出
button1.place(x=140, y=180)
# 文本框
qq = tk.Text(windoms,state='normal',bg='light cyan',fg='DeepPink')
qq.place(rely=0.6,relheight=0.4)
# 显示窗口
tk.mainloop()
到此这篇关于Python+tkinter实现高清图片保存的文章就介绍到这了,更多相关Python tkinter图片保存内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python自动爬取图片并保存实例代码
目录 一.准备工作 二.代码实现 三.总结 一.准备工作 用python来实现对百度图片的爬取并保存,以情绪图片为例,百度搜索可得到下图所示 f12打开源码 在此处可以看到这次我们要爬取的图片的基本信息是在img - scr中 二.代码实现 这次的爬取主要用了如下的第三方库 import re import time import requests from bs4 import BeautifulSoup import os 简单构思可以分为三个小部分 1.获取网页内容 2.解析网页 3.保存
-
Python中scrapy下载保存图片的示例
在日常爬虫练习中,我们爬取到的数据需要进行保存操作,在scrapy中我们可以使用ImagesPipeline这个类来进行相关操作,这个类是scrapy已经封装好的了,我们直接拿来用即可. 在使用ImagesPipeline下载图片数据时,我们需要对其中的三个管道类方法进行重写,其中 - get_media_request 是对图片地址发起请求 - file path 是返回图片名称 - item_completed 返回item,将其返回给下一个即将被执行的管道类 那具
-
Python使用scipy保存图片的一些注意点
首先我们载入一张灰度图片,一般灰度图片像素为0-255. 可以发现该图片的最大像素为254,最小像素为2.一般处理图片时会转化为double类型. 我们将图片使用scipy保存为pgm格式. 然后我们重新读取该图片信息. 其像素值发生了变化,自动标准化到了0-255范围,最小值变为0,最大值变为255. 所以,使用scipy保存图像时,加上2个参数,cmin和cmax.就可以了 重新读取图片.结果正确 补充:from scipy import misc 读取和保存图片 from scipy im
-
Python3基于plotly模块保存图片表格
使用plotly模块保存图片 目的 使用Python3的Plotly模块,实现对数据库数据的读取,然后形成Table表格,并通过钉钉机器人定时发送到钉钉群组. 难点 Plotly本身是通过html页面展示的,先要把图片保存下来需要安装一些其他的包:通过网上的无数文章都是错误的,弄了将近两天才把环境搞得,不得不感慨一下,下面就自己总结成文,飞快的就能搞定. 步骤 1.环境 CentOS Linux release 7.6.1810 (Core) 2.Python环境1)安装pip与pip32)安装
-
Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
python pyqtgraph 保存图片到本地的实例
pyqtgraph官方给的示例居然会报错2333 官方文档传送门:#####pyqtgraph export pyqtgraph支持在可视化窗口中右键保存(Exporting from the GUI)试了一下只能保存为svg格式, 保存为png会闪退不知道是我这里的原因还是这里有bug,我希望直接生成图片(Exporting from the API) 先查看本地site-packages里面有test文件,里面有生成svg的版本画出来的图是svg格式只能放在浏览器看不能改后缀名 而我希望生成
-
Python爬取网站图片并保存的实现示例
先看看结果吧,去bilibili上拿到的图片=-= 第一步,导入模块 import requests from bs4 import BeautifulSoup requests用来请求html页面,BeautifulSoup用来解析html 第二步,获取目标html页面 hd = {'user-agent': 'chrome/10'} # 伪装自己是个(chrome)浏览器=-= def download_all_html(): try: url = 'https://www.bilibili
-
Python+tkinter实现高清图片保存
目录 前言 基本开发环境 分析网页 开始工作 实现 全部代码 作为爱玩电脑的你是不是也需要经常更换一下自己的电脑壁纸呢? 换上一张心仪的图片整个人都舒畅多了.但是在网上有很多心仪的图片想要保存下来,如果一张张的去保存那效率又低,而后面的壁纸很有很多好看的又没有时间去看,这样就让我们错过了很多好看的壁纸,我们从从网站上一个一个下载实在太麻烦. 于是我用Python写一个保存图片的功能,把我们的图片给保存到我们的电脑,这样就可以浏览哪张好看就换哪张,不用再去慢慢保存了. 提示:以下是本篇文章正文内容
-
只用50行Python代码爬取网络美女高清图片
一.技术路线 requests:网页请求 BeautifulSoup:解析html网页 re:正则表达式,提取html网页信息 os:保存文件 import re import requests import os from bs4 import BeautifulSoup 二.获取网页信息 常规操作,获取网页信息的固定格式,返回的字符串格式的网页内容,其中headers参数可模拟人为的操作,'欺骗'网站不被发现 def getHtml(url): #固定格式,获取html内容 headers
-
Python数据可视化JupyterNotebook绘图生成高清图片
大家好,我是小五???? 最近有小伙伴问了个问题:如何在jupyter notebook,用Matplotlib画图时能够更"高清"? 今天正好跟大家聊聊,解决办法. 先举个小例子,用 Matplotlib 绘制极坐标图: import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline s = pd.Series(np.arange(20)) fig = plt.figu
-
基于python利用Pyecharts使高清图片导出并在PPT中动态展示
目录 1.前言 2.导出png格式图片 3.如何在PPT中展示pyecharts图片 1.前言 pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 JS 库.用 Echarts 生成的图可视化效果非常棒,为了与 Python 进行对接,方便在 Python 中直接使用数据生成图”.pyecharts可以展示动态图,在线报告使用比较美观,并且展示数据方便,鼠标悬停在图上,即可显示数值.标签等.pyecharts画出的图很好看,但是怎么展示是个
-
Python利用pywin32库实现将PPT导出为高清图片
目录 一.安装库 二.代码原理 三.使用效果 四.所有代码 一.安装库 需要安装pywin32库 pip install pywin32 二.代码原理 WPS高清图片导出需要会员,就为了一个这个小需求开一个会员太亏了,因此就使用python对ppt进行高清图片导出. 设置format=19即可: ppt.SaveAs(imgs_path, 19) 三.使用效果 输入一个文件路径 path = 'D:\\自动化\\课件.pptx' 最后的效果: 会在路径下创建一个‘’课件‘’文件夹 里面是所有转换
-
go语言实现抓取高清图片
看到有很多python 的,然后写了个go 的,可以抓取高清图片 getp.go 复制代码 代码如下: package main import ( "io/ioutil" "log" "net/http" "os" "regexp" "strconv" "strings" "sync"
-
深入分析WPF客户端读取高清图片卡以及缩略图的解决方法详解
在Ftp上传上,有人上传了高清图片,每张图片大约2M.如果使用传统的BitmapImage类,然后绑定 Source 属性的方法,有些电脑在首次会比较卡,一张电脑10秒,4张大约会卡40秒. 所以我先异步的下载图片,得到downloadFileStream对象,然后绑定到BitmapImage类上.例如:System.Windows.Controls.Image photo = new Image{ Width = 100, Height = 100, Margin = new
-
Python实现base64编码的图片保存到本地功能示例
本文实例讲述了Python实现base64编码的图片保存到本地功能.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import os import base64 sss ="""/9j/4AAQSkZJRgABAQEASABIAAD//gAyUHJvY2Vzc2VkIEJ5IGVCYXkgd2l0aCBJbWFnZU1hZ2ljaywgejEuMS4wLiB8fEIy/9sAQwAGBAUGBQQGBgUGBwcGCAoQ
-
详解Python静态网页爬取获取高清壁纸
前言 在设计爬虫项目的时候,首先要在脑内明确人工浏览页面获得图片时的步骤 一般地,我们去网上批量打开壁纸的时候一般操作如下: 1.打开壁纸网页 2.单击壁纸图(打开指定壁纸的页面) 3.选择分辨率(我们要下载高清的图) 4.保存图片 实际操作时,我们实现了如下几步网页地址的访问:打开了壁纸的网页→单击壁纸图打开指定页面→选择分辨率,点击后打开最终保存目标图片网页→保存图片 在爬虫的过程中我们就尝试通过模拟浏览器打开网页的操作,一步步获得.访问网页.最后获得目标图片的下载地址,对图片进行下载保存到
-
php imagecreatetruecolor 创建高清和透明图片代码小结
(PHP 4 >= 4.0.6, PHP 5) imagecreatetruecolor - 新建一个真彩色图像 说明 resource imagecreatetruecolor ( int $x_size , int $y_size ) imagecreatetruecolor() 返回一个图像标识符,代表了一幅大小为 x_size 和 y_size 的黑色图像. 是否定义了本函数取决于 PHP 和 GD 的版本.从 PHP 4.0.6 到 4.1.x 只要加载了 GD 模块本函数一直存在,但