SQL Server并行操作优化避免并行操作被抑制而影响SQL的执行效率
为什么我也要说SQL Server的并行:
这几天园子里写关于SQL Server并行的文章很多,不管怎么样,都让人对并行操作有了更深刻的认识。
我想说的是:尽管并行操作可能(并不是一定)存在这样或者那样的问题,但是我们不能否认并行,仍然要利用好并行。
但是,实际开发中,某些SQL语句的写法会导致用不到并行,从而影响到SQL的执行效率
所以,本文要表达的是:我们要利用好并行,不要让一些SQL的写法问题“抑制”了并行,让我们享受不了并行带来的快感
关于SQL Server的并行:
所谓的并行,指SQL Server对于那些执行代价相对较大(这个相对跟你的设置有关)的SQL时,如果数据库服务器存在多颗CPU,SQL Server查询引擎会采用并行的方式,也即采用多颗CPU参与整个运算过程,每颗CPU“分担”一部分计算任务,最后汇总合并各个CPU的计算的一种行为有时候,不当的并行查询不但不会加快查询的速度,想反会拖慢查询的效率,如果采用不当的并行操作,甚至会影响到整个服务器的稳定性。
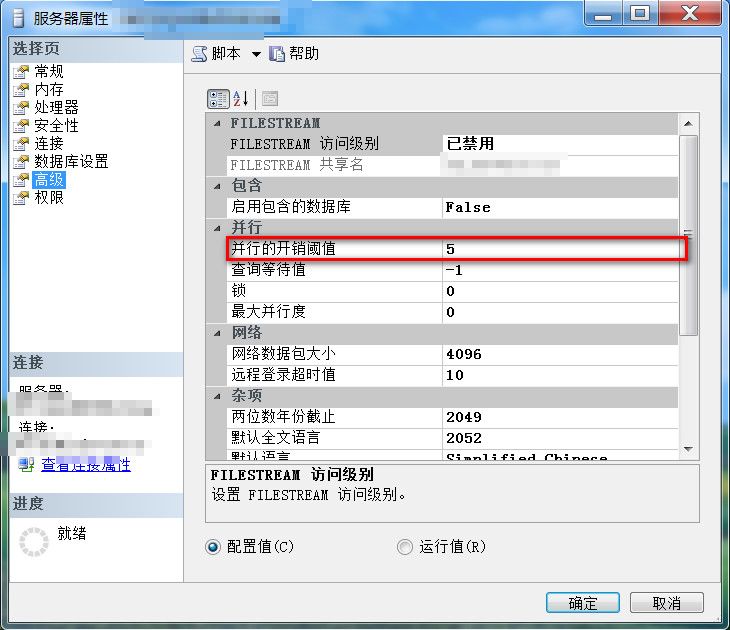
所以SQL Server 究竟在多大代价下启用并行,是由配置的,这个配置可根据具体的情况做修改,有人说这个值的单位是“秒”,貌似没见过权威的资料说过到底单位是什么,这里暂不追究
有清楚这个阈值单位的园友情不惜赐教,谢了
尽管并行操作可能存在这样活着那样的问题,但是我们不能因噎废食,利用好并行,往往总是利大于弊。
但是并不是所有的执行代价较大SQL都能用到并行操作,实际开发中,有一些SQL的写法会抑制到并行操作,结果,导致整个SQL语句(存储过程)的效率上不去。
下面来举例说明。
并行查询是如何变成了串行的:
如下是一个非常简单的查询操作,这些写法下,默认情况下开启了并行,可以看到,一共开启了8个线程来对SQL语句做计算。
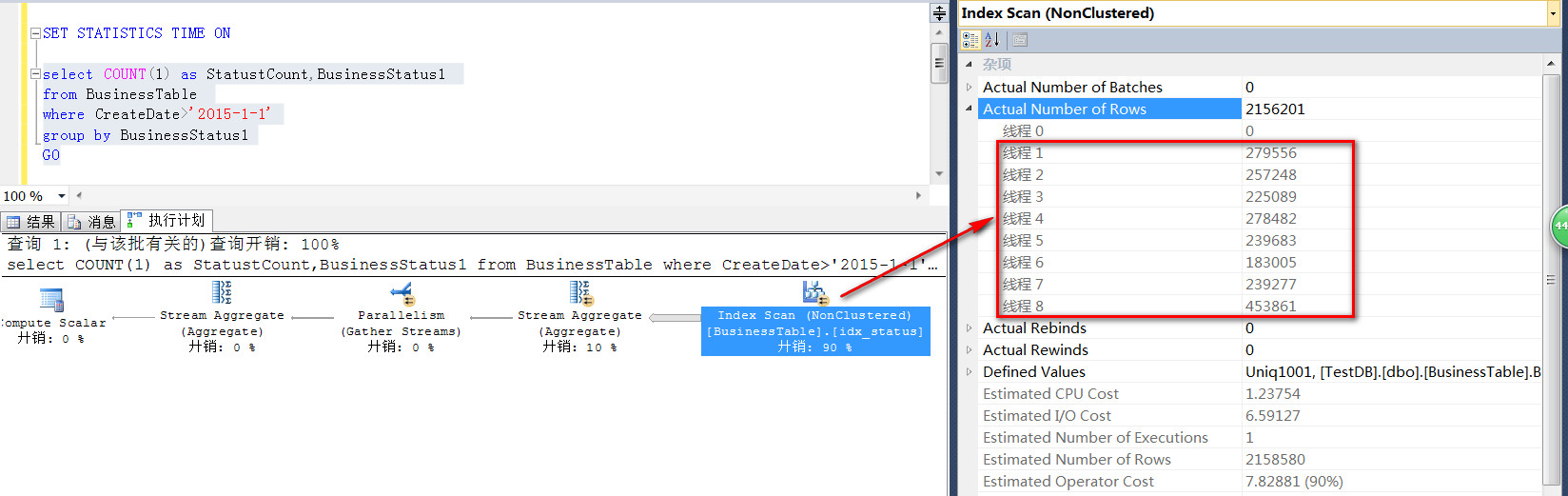
当然这SQL的执行效率还算不错,CPU时间是622毫秒,执行总时间是130毫秒,
这里不要弄混淆了,CPU时间的633毫秒,是8个CPU一共消耗的CPU时间,大于总的执行130毫秒很正常的
下面创建一个非常简单的函数,
CREATE function [dbo].[fn_justFunction](@p_date date) returns date as begin return @p_date end
这个函数并没有什么实际意义,执行也非常简单,传入一个时间,返回这个时间,
当然这里只是为了下面的操作演示,你完全可以说我蛋疼,我只是为了演示并行被抑制的现象
翻翻你的SQL代码,有没有类似这种写法?
然后我们这么写这个查询,就是在查询条件上这么处理CreateDate>dbo.fn_justFunction('2015-1-1')(注意不是表的列,而是函数作用在查询条件上),注意这个函数并不影响任何查询结果,传入的2015-1-1,返回位依旧是2015-1-1,但是这么一变化,并行就变成串行的了,SQL执行期间只有一个CPU飚了起来,使用了到达80%左右,,与此同时其他CPU跟没事人一样,也不上来帮忙,还是很闲还记得上面并行操作方式执行时间是多少么?130毫秒,现在粗看起来是多少,这里是4S,也就是4000毫秒了。差了多少倍,我数学不好算不出来
可以看到,并行操作和串行操作的效率差别还是很大的,对于CPU的利用也不充分(当然我不是强调一定要用满所有的CPU才算合理)
再次强调一点,这里并不是在表的字段上加函数抑制了索引什么的,纯粹的影响到的是并行操作。
当然,抑制并行的写法不单单是在查询条件在使用函数,实际开发中,影响会更大,
因为实际业务中数据有可能会更大,SQL也可能更加复杂,这种情况可能更加难以甄别。
比如连接条件上,如下,连接条件上使用函数导致无法使用并行的情况,也是实际开发中遇到的
select * from TableA a inner join TableB b on a.id=b.id and a.Column=dbo.function(@Variable) where ***
当然抑制到并行操作的不单单只有这两种写法,还有可能潜在其他类似的写法也会影响到并行查询。
这就要求我们在写SQL的时候,不但要注意不能再字段上使用函数(无法使用该字段上的索引),同样,查询条件上也尽可能不要使用函数,有可能影响到并行操作。
如果处理并行操作被抑制的情况:
如果要解决类似这些个问题,该怎么办?其实也很简单,建议查询条件通过函数运算之后赋值给一个变量,用变量去作为查询条件进行查询。
再次开始了愉快的并行,享受并行带来的快感。
对于连接条件上的函数处理也类似,将结果计算出来之后,保存在一个变量中,把变量写在连接条件中,
当然可能有其他办法,我暂时还没有想到。
总结:
本文通过一个简单的例子演示了并行操作被抑制的现象,说明了并行和串行在执行一个代价较大的SQL上的性能的巨大的差别
其中提到的查询方式是查询条件上因为函数的原因抑制了并行,完全区别于在查询列上使用函数抑制索引的情况。
并行查询可以充分调动CPU资源,以高效的方式完成查询,合理的利用并行会很大程度上提高SQL的执行效率。
为了利用好并行,在写SQL的时候,一定要注意,防止并行操作遭到抑制,给性能带来影响.
SQL优化是一个艰难而又反复的过程,即便如此,也乐在其中。
面对繁复SQL,不但要有过硬的技术,也要有足够的耐心,才能看清事物的本质。
对并行的理解还不够充分,有不对的地方希望各位看官指出,谢谢。
以上所述是小编给大家介绍的SQL Server并行操作优化避免并行操作被抑制而影响SQL的执行效率,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
sql语句优化之SQL Server(详细整理)
MS SQL Server查询优化方法 查询速度慢的原因很多,常见如下几种 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 5.网络速度慢 6.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量) 7.锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷) 8.sp_lock,sp_who,活动的用户查看,原因是读写竞争资源. 9.返回了不必要的行和列 10.查询语句不好,
-
SQL Server优化50法汇总
查询速度慢的原因很多,常见如下几种:1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2.I/O吞吐量小,形成了瓶颈效应.3.没有创建计算列导致查询不优化.4.内存不足5.网络速度慢6.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)7.锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8.sp_lock, sp_who, 活动的用户查看,原因是读写竞争资源.9.返回了不必要的行和列 10.查询语句不好,没有优化可以通过如下方法来优化查询 :1.把数据.日
-
优化 SQL Server 索引的小技巧
在本文中,我将说明如何用SQL Server的工具来优化数据库索引的使用,本文还涉及到有关索引的一般性知识. 关于索引的常识 影响到数据库性能的最大因素就是索引.由于该问题的复杂性,我只可能简单的谈谈这个问题,不过关于这方面的问题,目前有好几本不错的书籍可供你参阅.我在这里只讨论两种SQL Server索引,即clustered索引和nonclustered索引.当考察建立什么类型的索引时,你应当考虑数据类型和保存这些数据的column.同样,你也必须考虑数据库可能用到的查询类型以及使用的最为频
-
SqlServer 索引自动优化工具
鉴于人手严重不足(当时算两个半人的资源),打消了逐个库手动去改的念头.当前的程序结构不允许搞革命的做法,只能搞搞改良,所以准备搞个自动化工具去处理.原型刚开发完,开会的时候以拿出来就遭到运维DBA团队强烈抵制,具体原因不详.最后无限延期.这里把思路分享下.欢迎拍砖. 整个思路是这样的,索引都是为查询和更新服务的,但是不合适的索引又会对插入和更新带来负面影响.面对表上现有的索引想识别那些是有效的不太可能.那么根据现有的数据使用情况重建所有的新索引不就解决了嘛.根据查询生成全新索引,然后和现有对比,
-
SQL Server中的SQL语句优化与效率问题
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhangsan' and tID > 10000 和执行: select * from table1 where tID > 10000 and name='zhangsan' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那
-

SQL Server游标的使用/关闭/释放/优化小结
游标是邪恶的! 在关系数据库中,我们对于查询的思考是面向集合的.而游标打破了这一规则,游标使得我们思考方式变为逐行进行.对于类C的开发人员来着,这样的思考方式会更加舒服. 正常面向集合的思维方式是: 而对于游标来说: 这也是为什么游标是邪恶的,它会使开发人员变懒,懒得去想用面向集合的查询方式实现某些功能. 同样的,在性能上,游标会吃更多的内存,减少可用的并发,占用宽带,锁定资源,当然还有更多的代码量-- 从游标对数据库的读取方式来说,不难看出游标为什么占用更多的资源,打个比方: 当你从ATM取钱
-
人工智能自动sql优化工具--SQLTuning for SQL Server
针对这种情况,人工智能自动SQL优化工具应运而生.现在我就向大家介绍这样一款工具:SQLTuning for SQL Server. 1. SQL Tuning 简介 SQL Turning是Quest公司出品的Quest Central软件中的一个工具. QuestCentral(图1)是一款集成化.图形化.跨平台的数据库管理解决方案,可以同时管理Oracle.DB2 和 SQL server 数据库.它包含了如下的多个工具: 数据库管理(DBA) 数据库监控(Monitoring Pack
-
SQL Server并行操作优化避免并行操作被抑制而影响SQL的执行效率
为什么我也要说SQL Server的并行: 这几天园子里写关于SQL Server并行的文章很多,不管怎么样,都让人对并行操作有了更深刻的认识. 我想说的是:尽管并行操作可能(并不是一定)存在这样或者那样的问题,但是我们不能否认并行,仍然要利用好并行. 但是,实际开发中,某些SQL语句的写法会导致用不到并行,从而影响到SQL的执行效率 所以,本文要表达的是:我们要利用好并行,不要让一些SQL的写法问题"抑制"了并行,让我们享受不了并行带来的快感 关于SQL Server的并行: 所谓的
-
sql server 性能优化之nolock
伴随着时间的增长,公司的数据库会越来越多,查询速度也会越来越慢.打开数据库看到几十万条的数据,查询起来难免不废时间. 要提升SQL的查询效能,一般来说大家会以建立索引(index)为第一考虑.其实除了index的建立之外,当我们在下SQL Command时,在语法中加一段WITH (NOLOCK)可以改善在线大量查询的环境中数据集被LOCK的现象藉此改善查询的效能. 不过有一点千万要注意的就是,WITH (NOLOCK)的SQL SELECT有可能会造成Dirty Read,就是读到无效的数据.
-
SQL Server 数据库优化
在开发工具.数据库设计.应用程序的结构.查询设计.接口选择等方面有多种选择,这取决于特定的应用需求以及开发队伍的技能.本文以SQL Server为例,从后台数据库的角度讨论应用程序性能优化技巧,并且给出了一些有益的建议.1 数据库设计 要在良好的SQL Server方案中实现最优的性能,最关键的是要有1个很好的数据库设计方案.在实际工作中,许多SQL Server方案往往是由于数据库设计得不好导致性能很差.所以,要实现良好的数据库设计就必须考虑这些问题. 1.1 逻辑库规范化问题 一般来说,逻辑
-
SQL Server误区30日谈 第13天 在SQL Server 2000兼容模式下不能使用DMV
误区 #13.在SQL Server 2000兼容模式下不能使用DMV 错误 对于兼容模式已经存在了很多误解.80的兼容模式的数据库是否意味着能够附加或恢复到SQL Server 2000数据库?当然不是.这只是意味着一些T-SQL的语法,查询计划的行为以及一些其它方面和SQL Server 2000中行为一样(当然,如果你设置成90兼容模式则和SQL Server 2005中一样). 在SQL Server 2008中,你可以使用ALTER DATABASE SET COMPATI
-
SQL SERVER的优化建议与方法
在实际的工作中,尤其是在生产环境里边,SQL语句的优化问题十分的重要,它对数据库的性能的提升也起着显著的作用.我们总是在抱怨机器的性能问题,总是在抱怨并发访问所带来的琐问题,但是如果我们对没一条SQL语句进行优化,尽管不能说可以解决全部问题,但是至少可以解决大部分问题. 1.Top排序问题. 我们经常要对表某个字段进行排序,然后取前N名.所以我们会写如下的SQL语句: select top 100 * from 表 order by Score desc 如果表非常大的话,那么这样的操作是非常消
-
谈谈Tempdb对SQL Server性能优化有何影响
先给大家巩固tempdb的基础知识 简介: tempdb是SQLServer的系统数据库一直都是SQLServer的重要组成部分,用来存储临时对象.可以简单理解tempdb是SQLServer的速写板.应用程序与数据库都可以使用tempdb作为临时的数据存储区.一个实例的所有用户都共享一个Tempdb.很明显,这样的设计不是很好.当多个应用程序的数据库部署在同一台服务器上的时候,应用程序共享tempdb,如果开发人员不注意对Tempdb的使用就会造成这些数据库相互影响从而影响应用程序. 特性:
-
SQL SERVER性能优化综述(很好的总结,不要错过哦)第1/3页
一.分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性.可用性.可靠性.安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求.响应时间的需求.硬件的配置等.最好能有各种需求的量化的指标. 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统). 二.设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎
-
SQL Server 索引结构及其使用(二) 改善SQL语句第1/3页
比如: select * from table1 where name=''zhangsan'' and tID > 10000 和执行: select * from table1 where tID > 10000 and name=''zhangsan'' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那么后一句仅仅从表的10000条以后的记录中查找就行了:而前一句则要先从全表中查找看有几个name=''zhan
-
浅析SQL Server 聚焦索引对非聚集索引的影响
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一个思考的过程,无论是独立思考也好还是查资料也罢都是思考而非走马观花,要不然过一段时间又会健忘.简短的内容,深入的理解. 话题 非聚集索引定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.你真的理解了吗??你能举出例子吗?
-
推荐SQL Server 重新恢复自动编号列的序号的sql代码
在sql server中经常有这样的问题: 一个表采用了自动编号的列之后,由于测试了好多数据,自动编号已累计了上万个.现在正是要用这个表了,测试数据已经删了,遗留下来的问题 就是 在录入新的数据,编号只会继续增加,已使用过的但已删除的编号就不能用了, 谁知道如何解决此问题? truncate命令不但会清除所有的数据,还会将IDENTITY的SEED的值恢复到原是值. 而DBCC CHECKIDENT则更加方便一些,可以在不删除数据的情况下指定SEED的值. 1. truncat