用python写的一个wordpress的采集程序
在学习python的过程中,经过不断的尝试及努力,终于完成了第一个像样的python程序,虽然还有很多需要优化的地方,但是目前基本上实现了我所要求的功能,先贴一下程序代码:
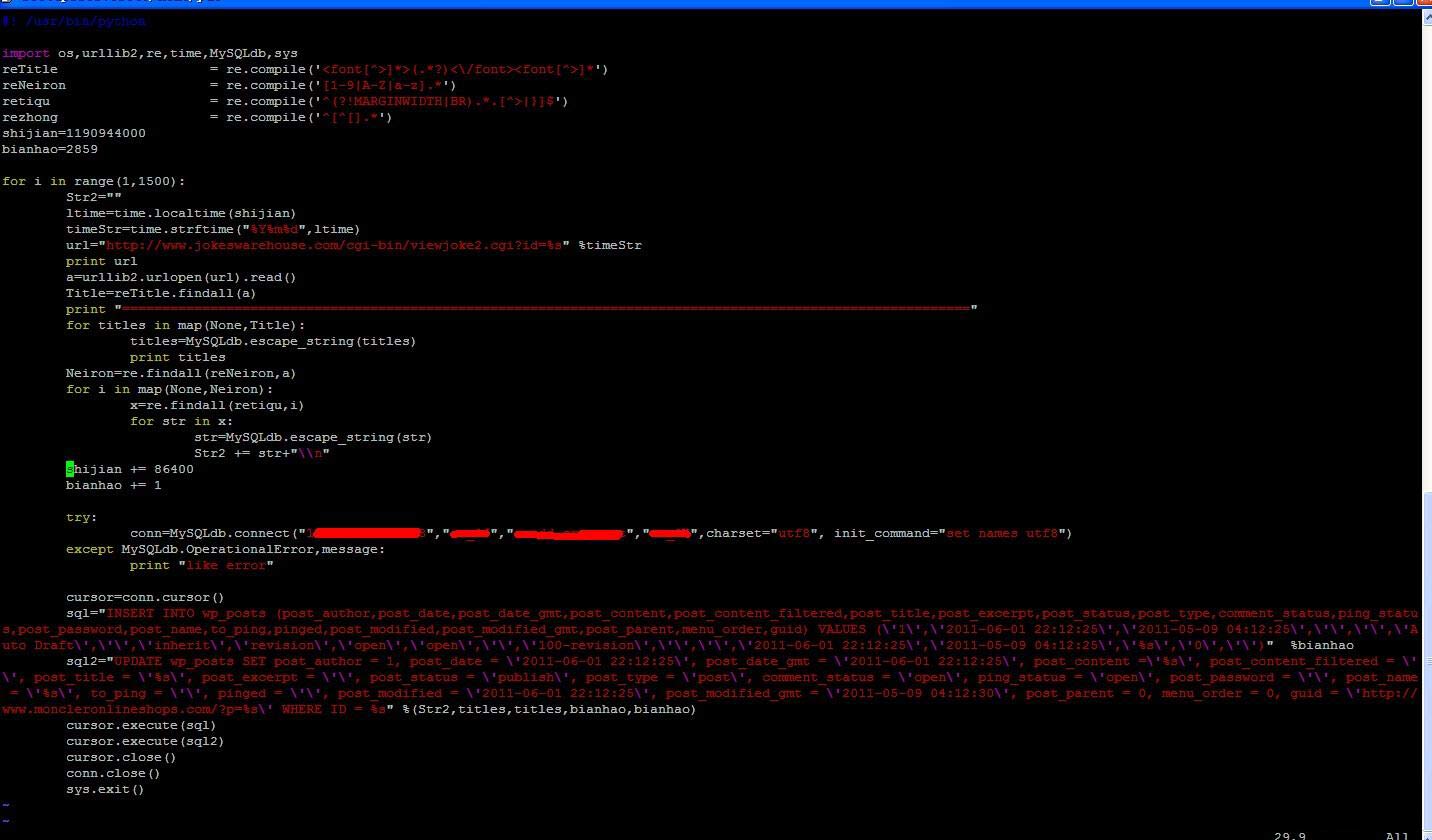
具体代码如下:
#! /usr/bin/python
import os,urllib2,re,time,MySQLdb,sys
reTitle = re.compile('<font[^>]*>(.*?)<\/font><font[^>]*')
reNeiron = re.compile('[1-9|A-Z|a-z].*')
retiqu = re.compile('^(?!MARGINWIDTH|BR).*.[^>|}]$')
rezhong = re.compile('^[^[].*')
shijian=1190944000
Str1="\\n---------------- BLOG OF YAO"
bianhao=2859
for i in range(1,1500):
Str2=""
ltime=time.localtime(shijian)
timeStr=time.strftime("%Y%m%d",ltime)
url="http://www.jokeswarehouse.com/cgi-bin/viewjoke2.cgi?id=%s" %timeStr
print url
a=urllib2.urlopen(url).read()
Title=reTitle.findall(a)
print "=========================================================================================================="
for titles in map(None,Title):
titles=MySQLdb.escape_string(titles)
print titles
Neiron=re.findall(reNeiron,a)
for i in map(None,Neiron):
x=re.findall(retiqu,i)
for str in x:
str=MySQLdb.escape_string(str)
Str2 += str+"\\n"
shijian += 86400
bianhao += 1
try:
conn=MySQLdb.connect("XXXX.XXXX.XXXX.XXXX","user","passwd","dbname",charset="utf8", init_command="set names utf8")
except MySQLdb.OperationalError,message:
print "like error"
cursor=conn.cursor()
sql="INSERT INTO wp_posts (post_author,post_date,post_date_gmt,post_content,post_content_filtered,post_title,post_excerpt,post_status,post_type,comment_status,ping_status,post_password,post_name,to_ping,pinged,post_modified,post_modified_gmt,post_parent,menu_order,guid) VALUES (\'1\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'\',\'\',\'Auto Draft\',\'\',\'inherit\',\'revision\',\'open\',\'open\',\'\',\'100-revision\',\'\',\'\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'%s\',\'0\',\'\')" %bianhao
sql2="UPDATE wp_posts SET post_author = 1, post_date = \'2011-06-01 22:12:25\', post_date_gmt = \'2011-06-01 22:12:25\', post_content =\'%s\', post_content_filtered = \'\', post_title = \'%s\', post_excerpt = \'\', post_status = \'publish\', post_type = \'post\', comment_status = \'open\', ping_status = \'open\', post_password = \'\', post_name = \'%s\', to_ping = \'\', pinged = \'\', post_modified = \'2011-06-01 22:12:25\', post_modified_gmt = \'2011-05-09 04:12:30\', post_parent = 0, menu_order = 0, guid = \'http://www.moncleronlineshops.com/?p=%s\' WHERE ID = %s" %(Str2,titles,titles,bianhao,bianhao)
cursor.execute(sql)
cursor.execute(sql2)
cursor.close()
conn.close()
sys.exit()
下面,我们来给代码加些注释,让读者能看的更明白一些,如下:
具体代码如下
#! /usr/bin/python
import os,urllib2,re,time,MySQLdb,sys #加载本程序需要调用的相模块
reTitle = re.compile('<font[^>]*>(.*?)<\/font> <font[^>]*') # 定义一下取文章标题的正则
reNeiron = re.compile('[1-9|A-Z|a-z].*')
#定义一个取提取文章内容的正则(注:这里提取出来的不是很精细,需要在下面的正则里,再进行提取,这里只是取一个大概)
retiqu = re.compile('^(?!MARGINWIDTH|BR).*.[^>|}]$')
#这里定义一个正则,将上面reNeiron提取出来的字符,再进行细化。
shijian=1190944000 #这里字义了一个时间戳,
Str1="\\n---------------- BLOG OF YAO" #这个没用,开始是准备加到文章里的,后来没加进去。
bianhao=2859 #这里是wordpress 的文章编号,直接查看wp-posts表的id 字段的最后一个数字。
for i in range(1,1500): #循环1500遍,也就是采集1500篇文章。
Str2="" #先赋值给Str2 空值
ltime=time.localtime(shijian)
timeStr=time.strftime("%Y%m%d",ltime) #这两句将上面的时间戳改为时间,样式为19700101这样的格式
url="http://www.jokeswarehouse.com/cgi-bin/viewjoke2.cgi?id=%s" %timeStr #定义要采集的网站,将转化后的时间放在这个url的最后。
a=urllib2.urlopen(url).read() #将这个网页的源代码读出来,赋值给a;
Title=reTitle.findall(a)
#使用 reTitle这个正则提取出标题
print "=========================================================================================================="
for titles in map(None,Title): #上面提取出来的标题前后都有一个 []
所以我们要写个for循环把前后的[]去掉,并转义成能直接插入mysql库的格式。
titles=MySQLdb.escape_string(titles)
Neiron=re.findall(reNeiron,a) #先用reNeiron,取个大概的内容模型出来。这些都是以逗号分隔的数组。
for i in map(None,Neiron): # 我们来循环读出Neiron这个数组里的每个值。
x=re.findall(retiqu,i)#并用 retiqu这个正则提出精细出的内容。
for str in x:
str=MySQLdb.escape_string(str)
Str2 += str+"\\n"
#利用这个循环,我们把内容加到一起,并赋值给Str2这个变量,这个 Str2这个变量就是所有的文章内容。
shijian += 86400 #每循环一次,就把shijian这个变量加上一天。
bianhao += 1 #每循环一次,就把bianhao这个变量加上一
try:
#下面是用mysqldb连接数据库,并尝试连接是否成功。 conn=MySQLdb.connect("XXXX.XXXX.XXXX.XXXX","user","passwd","dbname",charset="utf8", init_command="set names utf8")
except MySQLdb.OperationalError,message:
print "like error"
cursor=conn.cursor()
#下面是插入wordpress数据库的两条语句,我是从mysqlbinlog里面导出来的,测试是可以插入数据库,并能正常把内容显示在网页的。变量都写在这两条语句里。
sql="INSERT INTO wp_posts (post_author,post_date,post_date_gmt,post_content,post_content_filtered,post_title,post_excerpt,post_status,post_type,comment_status,ping_status,post_password,post_name,to_ping,pinged,post_modified,post_modified_gmt,post_parent,menu_order,guid) VALUES (\'1\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'\',\'\',\'Auto Draft\',\'\',\'inherit\',\'revision\',\'open\',\'open\',\'\',\'100-revision\',\'\',\'\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'%s\',\'0\',\'\')" %bianhao
sql2="UPDATE wp_posts SET post_author = 1, post_date = \'2011-06-01 22:12:25\', post_date_gmt = \'2011-06-01 22:12:25\', post_content =\'%s\', post_content_filtered = \'\', post_title = \'%s\', post_excerpt = \'\', post_status = \'publish\', post_type = \'post\', comment_status = \'open\', ping_status = \'open\', post_password = \'\', post_name = \'%s\', to_ping = \'\', pinged = \'\', post_modified = \'2011-06-01 22:12:25\', post_modified_gmt = \'2011-05-09 04:12:30\', post_parent = 0, menu_order = 0, guid = \'http://www.moncleronlineshops.com/?p=%s\' WHERE ID = %s" %(Str2,titles,titles,bianhao,bianhao)
cursor.execute(sql)
cursor.execute(sql2) #连接数据库并执行这两条语句。
cursor.close()
conn.close() #关闭数据库。
sys.exit()
上面是程序的代码,采集的是:www.jokeswarehouse.com 的一个笑话网站。通过 python 的 re 模块,也就是正则匹配模块,运行相应的正则表达式,进行过滤出我们所需要的标题和文章内容,再运用 python 的mysqldb 模块,进行连接数据库,利用相应的插入语句,进行插入数据库。
相关推荐
-
Python+Wordpress制作小说站
我用Python和Wordpress建了一个小说站. 下面主要讲一讲搭建过程中所用的技术.主要分为以下几个部分: Wordpress主题的选取 小说内容的完善 站点的部署 微信公众平台的搭建 1.Wordpress主题的选取 由于自己对php代码编写不是非常熟悉,直接编写网站很可能会遇到各种安全漏洞.对比目前比较流行的博客框架wordpress.joomla.drupal,最终还是选择受众比较广的wordpress.之后选取了一套小说模板,就这么上马啦~~ 2.小说内容的完善 2.1 数据的抓取
-

编写Python脚本抓取网络小说来制作自己的阅读器
你是否苦恼于网上无法下载的"小说在线阅读"内容?或是某些文章的内容让你很有收藏的冲动,却找不到一个下载的链接?是不是有种自己写个程序把全部搞定的冲动?是不是学了 python,想要找点东西大展拳脚,告诉别人"哥可是很牛逼的!"?那就让我们开始吧! 哈哈~ 好吧,我就是最近写 Yii 写多了,想找点东西调剂一下.... = = 本项目以研究为目的,所有版权问题我们都是站在作者的一边,以看盗版小说为目的的读者们请自行面壁! 说了这么多,我们要做的就是把小
-
Python制作爬虫采集小说
开发工具:python3.4 操作系统:win8 主要功能:去指定小说网页爬小说目录,按章节保存到本地,并将爬过的网页保存到本地配置文件. 被爬网站:http://www.cishuge.com/ 小说名称:灵棺夜行 代码出处:本人亲自码的 import urllib.request import http.cookiejar import socket import time import re timeout = 20 socket.setdefaulttimeout(timeout) sl
-
Python实现爬取逐浪小说的方法
本文实例讲述了Python实现爬取逐浪小说的方法.分享给大家供大家参考.具体分析如下: 本人喜欢在网上看小说,一直使用的是小说下载阅读器,可以自动从网上下载想看的小说到本地,比较方便.最近在学习Python的爬虫,受此启发,突然就想到写一个爬取小说内容的脚本玩玩.于是,通过在逐浪上面分析源代码,找出结构特点之后,写了一个可以爬取逐浪上小说内容的脚本. 具体实现功能如下:输入小说目录页的url之后,脚本会自动分析目录页,提取小说的章节名和章节链接地址.然后再从章节链接地址逐个提取章节内容.现阶段只
-
Python实现的飞速中文网小说下载脚本
1.JavaScript 加密什么的最讨厌了 :-( 1).eval 一个不依赖外部变量的函数立即调用很天真,看我 nodejs 来干掉你! 2).HTTP 请求的验证首先尝试 Referer,「小甜饼」没有想像中的那么重要. 3).curl 和各命令行工具处理起文本很顺手呢 4).但是 Python 也没多几行呢 2.Requests效率比 lxml 自己那个好太多 3.progressbar太先进了,我还是自个儿写吧-- 4.argparse写 Python 命令行程序必备啊- 5.stri
-
用python写的一个wordpress的采集程序
在学习python的过程中,经过不断的尝试及努力,终于完成了第一个像样的python程序,虽然还有很多需要优化的地方,但是目前基本上实现了我所要求的功能,先贴一下程序代码: 具体代码如下: #! /usr/bin/python import os,urllib2,re,time,MySQLdb,sys reTitle = re.compile('<font[^>]*>(.*?)<\/font><font[^>]*') reNeiron = re.compile('
-
Python写的一个定时重跑获取数据库数据
做大数据的童鞋经常会写定时任务跑数据,由于任务之间的依赖(一般都是下游依赖上游的数据产出),所以经常会导致数据获取失败,因为很多人发现数据失败后 都会去查看日志,然后手动去执行自己的任务.下面我实现了一个自动重复执行去数据库取数,如果失败后自动重新去获取,直到把数据获取到. 建数据表: CREATE TABLE `testtable` ( 2 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 3 `name` varchar(20) NOT NULL,
-
利用Python写了一个水果忍者小游戏
目录 前言: 一.需要导入的包 二.窗口界面设置 三.随机生成水果位置 四.绘制字体 五.玩家生命的提示 六.游戏开始与结束的画面 七.游戏主循环 最后 前言: 水果忍者到家都玩过吧,但是Python写的水果忍者你肯定没有玩过.今天就给你表演一个新的,用Python写一个水果忍者.水果忍者的玩法很简单,尽可能的切开抛出的水果就行. 今天就用python简单的模拟一下这个游戏.在这个简单的项目中,我们用鼠标选择水果来切割,同时炸弹也会隐藏在水果中,如果切开了三次炸弹,玩家就会失败. 一.需要导入的
-
用Python写一段用户登录的程序代码
如下所示: #!/usr/bin/env python #coding: utf8 import getpass db = {} def newUser(): username = raw_input('username: ') if username in db: #添加打印颜色 print "\033[32;1m%s already exists![0m" % username else: #屏幕不显示密码,调用getpass.getpass() password = getpas
-
Python运行第一个PySide2的窗体程序
上一章节介绍了PySide2的安装以及如何去启动程序进行页面设计,并且将工具集成到pycharm的扩展工具中去,有2个地方写的不对,用的是pyuic工具,需要改一下,改成pyside2-uic.exe.具体改动点: pycharm扩展工具中的配置也需要调整一下: 上一篇的配置写的是pyqt5的配置,这里主要采用PySide2进行学习. 修改为正确的配置后,鼠标选中ui文件,右键选择扩展工具中的pyside2-uic就可以转换为python脚本. 先看一下我画的一个简单的GUI页面: 保存页面文件
-
Python写的一个简单监控系统
市面上有很多开源的监控系统:Cacti.nagios.zabbix.感觉都不符合我的需求,为什么不自己做一个呢 用Python两个小时徒手撸了一个简易的监控系统,给大家分享一下,希望能对大家有所启发 首先数据库建表 建立一个数据库"falcon",建表语句如下: CREATE TABLE `stat` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `host` varchar(256) DEFAULT NULL, `mem_free`
-
使用nodejs、Python写的一个简易HTTP静态文件服务器
日常开发过程中,我们经常需要修改一些放在 CDN 上的静态文件(如 JavaScript.CSS.HTML 文件等),这个过程中,我们希望能有一种方式将线上 CDN 的目录映射为本地硬盘上的某个目录,这样,当我们在本地修改了某个文件时,不需要发布,刷新后马上能看到效果. 比如,我们的 CDN 域名是:http://a.mycdn.com,本地对应的目录是:D:\workassets,我们希望所有对 http://a.mycdn.com/* 的访问被映射到本地的 D:\workassets\* 下
-
Python实现的一个自动售饮料程序代码分享
写这个程序的时候,我已学习Python将近有一百个小时,在CSDN上看到有人求助使用Python如何写一个自动售饮料的程序,我一想,试试写一个实用的售货程序.当然,只是实现基本功能,欢迎高手指点,新手学习参考. 运行环境:Python 2.7 # encoding=UTF-8 loop=True money=0 while loop: x = raw_input('提示:请投入金币,结束投币请按"q"键') if x=='q': if money==0:
-
python 写的一个爬虫程序源码
写爬虫是一项复杂.枯噪.反复的工作,考虑的问题包括采集效率.链路异常处理.数据质量(与站点编码规范关系很大)等.整理自己写一个爬虫程序,单台服务器可以启用1~8个实例同时采集,然后将数据入库. #-*- coding:utf-8 -*- #!/usr/local/bin/python import sys, time, os,string import mechanize import urlparse from BeautifulSoup import BeautifulSoup import
-
python写的一个squid访问日志分析的小程序
这两周组里面几位想学习python,于是我们就创建了一个这样的环境和氛围来给大家学习. 昨天在群里,贴了一个需求,就是统计squid访问日志中ip 访问数和url的访问数并排序,不少同学都大体实现了相应的功能,我把我简单实现的贴出来,欢迎拍砖: 日志格式如下: 复制代码 代码如下: %ts.%03tu %6tr %{X-Forwarded-For}>h %Ss/%03Hs %<st %rm %ru %un %Sh/%<A %mt "%{Referer}>h"