Python3实战之爬虫抓取网易云音乐的热门评论
前言
之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了。于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫。我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步。
废话就不多说了~下面来一起看看详细的介绍吧。
我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论。
这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论。
实现分析
首先,我们打开网易云网页版,如图:
点击排行榜,然后点击左侧云音乐热歌榜,如图:
我们先随便打开一个歌曲,找到如何抓取指定的歌曲的热门歌评的方法,如图,我选了一个最近我比较喜欢的歌曲为例:
进去后我们会看到歌评就在这个页面的下面,接下来我们就要想办法获取这些评论。
接下来打开web控制台(chrom的话打开开发者工具,如果是其他浏览器应该也是类似),chrom下按F12,如图:
选则Network,然后我们按F5刷新一下,刷新之后得到的数据如下图所示:
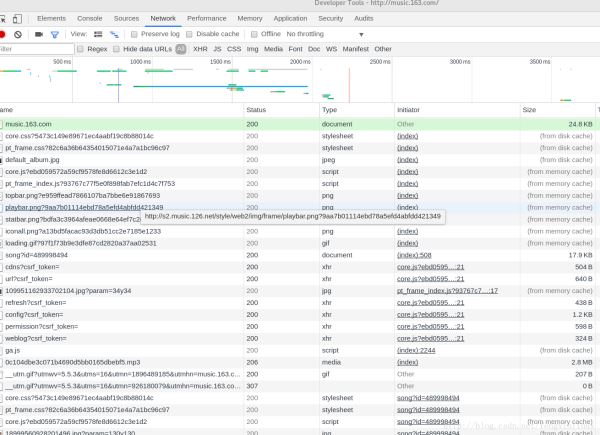
可以看到浏览器发送了非常多的信息,那么哪一个才是我们想要的呢?这里我们可以通过状态码做一个初步的判断,status code(状态码)标志了服务器请求的状态,这里状态码为200即表示请求正常,而304则表示不正常(状态码种类非常多,如果要想详细了解可以自行搜索,这里不说304具体的含义了)。所以我们一般只用看状态码为200的请求就可以了,还有就是,我们可以通过右边栏的预览来粗略观察服务器返回了什么信息(或者查看响应)。通过这两种方法结合一般我们就可以快速找到我们想要分析的请求。通过反复的查找,终于找到了含有歌评的请求,如图:

可能截图在CSDN上不是很清楚,我们在一个Name为R_SO_4_489998494?csrf_token=的POST请求中找到了包含这首歌的歌评。我们把这个分块截图发出来,这样可以看的清楚一些:
请求基本信息:

请求头部:
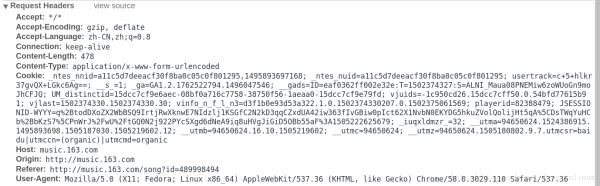
请求中的表单数据:

我们可以看到,包含这首歌歌评的请求url为http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= ,我们换了几首歌后发现,这个请求的前部分都是一样的,只是R_SO_4_后面紧跟的一串数字不一样。我们可以推测出,每一首歌都有一个指定的id,R_SO_4_后面紧跟的就是这首歌的id。
我们再看一下提交的表单数据,我们会发现表单中需要填两个数据,名称为params和encSecKey。后面紧跟的是一大串字符,换几首歌会发现,每首歌的params和encSecKey都是不一样的,因此,这两个数据可能经过一个特定的算法进行加密过的。
服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),其中hotComments就是我们要找的热门评论,总共15条,如图所示:
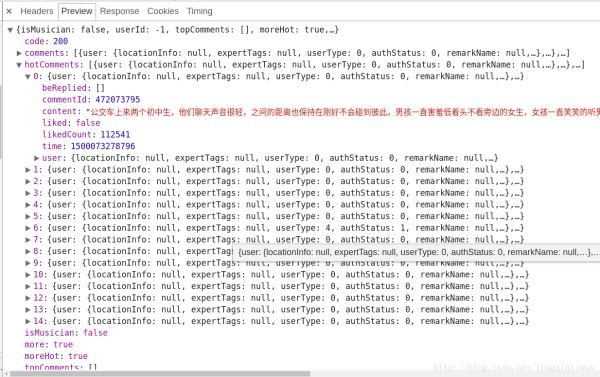
至此,我们已经确定了方向了,即只需要确定params和encSecKey这两个参数值即可。但是这两个参数是经过特定的算法进行加密的,怎么办呢?我发现了一个规律,http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= 中 R_SO_4_后面的数字就是这首歌的id值,而对于不同的歌曲的param和encSecKey值,如果把一首歌比如A的这两个参数值传给B这首歌,那么对于相同的页数,这种参数是通用的,即A的第一页的两个参数值传给其他任何一首歌的两个参数,都可以获得相应歌曲的第一页的评论,对于第二页,第三页等也是类似。
而我们其实只需要获取第一页的15条热门评论,所以我们只需要随便找一首歌,将这首歌第一页中的该请求中的params和encSecKey这两个参数值复制下来,就可以使用了。
关于这两个参数如何解密,强大的知乎上其实已经有答案的了,感兴趣的朋友可以进去看一下(https://www.zhihu.com/question/36081767),我们在这里就只需要用我们这种偷懒的办法就可以完成需求了,xixi。
到此为止,我们如何抓取网易云音乐的热门评论已经分析完了,我们再分析一下如何获取云音乐热歌榜中所有歌曲的信息。
我们需要获取云音乐热歌榜中的所有歌曲的歌曲名和对应的id值。
跟上面的分析步骤类似,我们先进入热歌榜的网址,如图:
按F12,进入WEB工作台,如图:
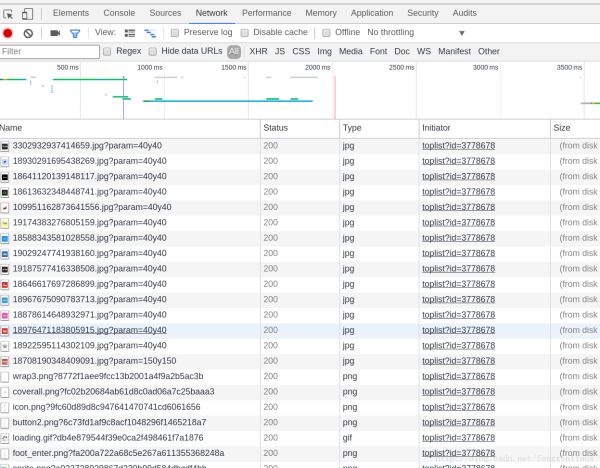
我们在一个名为toplist?id=3778678的GET请求中,找到了该榜单的所有歌曲信息。
请求对应的信息如图:
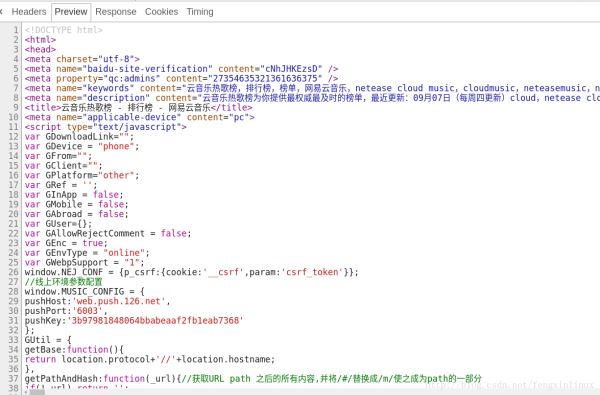
我们预览一下该请求返回的结果,如图:
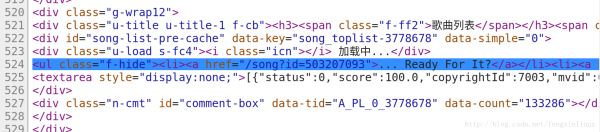
我们在代码的第524行我们找到了包含歌曲信息的代码,如图:
因此,我们只需要将该请求的代码中,将包含信息的代码筛选出来。
我们在这里使用正则表达式进行数据筛选。
通过观察特点,我们可以通过两次正则表达式的筛选,将我们需要的歌曲信息提取出来。
第一次正则表达式我们将该请求返回的所有代码中,提取出第525行代码。
第一次正则表达式如下:<ul class="f-hide"><li><a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >.*</a></li></ul>
第二次正则表达式我们将该第524行中我们需要的歌曲信息提取出来,我们需要歌曲的歌名和id,对应的正则表达式如下:
获取歌名:<li><a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>
获取歌曲的id:<li><a href="/song\?id=(\d*?)" rel="external nofollow" rel="external nofollow" >.*?</a></li>
到此,我们整个过程已经分析完了,上代码看具体细节~~
代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import urllib.request
import urllib.error
import urllib.parse
import json
def get_all_hotSong(): #获取热歌榜所有歌曲名称和id
url='http://music.163.com/discover/toplist?id=3778678' #网易云云音乐热歌榜url
html=urllib.request.urlopen(url).read().decode('utf8') #打开url
html=str(html) #转换成str
pat1=r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' #进行第一次筛选的正则表达式
result=re.compile(pat1).findall(html) #用正则表达式进行筛选
result=result[0] #获取tuple的第一个元素
pat2=r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' #进行歌名筛选的正则表达式
pat3=r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' #进行歌ID筛选的正则表达式
hot_song_name=re.compile(pat2).findall(result) #获取所有热门歌曲名称
hot_song_id=re.compile(pat3).findall(result) #获取所有热门歌曲对应的Id
return hot_song_name,hot_song_id
def get_hotComments(hot_song_name,hot_song_id):
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' #歌评url
header={ #请求头部
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#post请求表单数据
data={'params':'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ','encSecKey':'4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
postdata=urllib.parse.urlencode(data).encode('utf8') #进行编码
request=urllib.request.Request(url,headers=header,data=postdata)
reponse=urllib.request.urlopen(request).read().decode('utf8')
json_dict=json.loads(reponse) #获取json
hot_commit=json_dict['hotComments'] #获取json中的热门评论
num=0
fhandle=open('./song_comments','a') #写入文件
fhandle.write(hot_song_name+':'+'\n')
for item in hot_commit:
num+=1
fhandle.write(str(num)+'.'+item['content']+'\n')
fhandle.write('\n==============================================\n\n')
fhandle.close()
hot_song_name,hot_song_id=get_all_hotSong() #获取热歌榜所有歌曲名称和id
num=0
while num < len(hot_song_name): #保存所有热歌榜中的热评
print('正在抓取第%d首歌曲热评...'%(num+1))
get_hotComments(hot_song_name[num],hot_song_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1
码运行结果如下:
对比一下网页上《如果我爱你》这首歌的歌评和我们保存下的歌评:
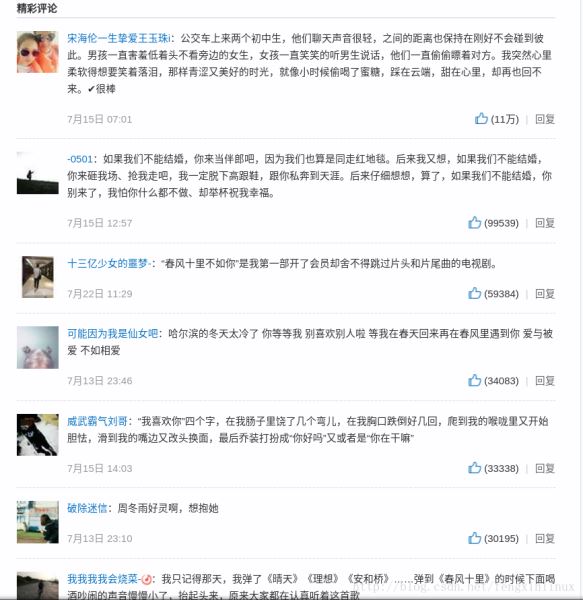

信息无误~
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
一则python3的简单爬虫代码
不得不说python的上手非常简单.在网上找了一下,大都是python2的帖子,于是随手写了个python3的.代码非常简单就不解释了,直接贴代码. 复制代码 代码如下: #test rdpimport urllib.requestimport re<br>#登录用的帐户信息data={}data['fromUrl']=''data['fromUrlTemp']=''data['loginId']='12345'data['password']='12345'user_agent='Mozil
-

Python爬取网易云音乐热门评论
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧.获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据.但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据.那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据.利用计算机的高效,我们可以轻松快速地获取数据. 那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,py
-
python3爬虫之入门基础和正则表达式
前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享:爬虫说的简单,就是去抓取网路的数据进行分析处理:这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式: 用python抓取指定页面: 代码如下: import urllib.request url= "http://www.baidu.com" data = urllib.request.urlopen(url).read()# d
-
Python正则抓取网易新闻的方法示例
本文实例讲述了Python正则抓取网易新闻的方法.分享给大家供大家参考,具体如下: 自己写了些关于抓取网易新闻的爬虫,发现其网页源代码与网页的评论根本就对不上,所以,采用了抓包工具得到了其评论的隐藏地址(每个浏览器都有自己的抓包工具,都可以用来分析网站) 如果仔细观察的话就会发现,有一个特殊的,那么这个就是自己想要的了 然后打开链接就可以找到相关的评论内容了.(下图为第一页内容) 接下来就是代码了(也照着大神的改改写写了). #coding=utf-8 import urllib2 import
-
python3制作捧腹网段子页爬虫
0x01 春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程.第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便.于是乎就自己照猫画虎,抓了点图片. 科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬点笑话比较有益于身心健康. 0x02 在我们撸起袖子开始搞之前,先来普及点理论知识. 简单地说,我们要把网页上特定位置的内容,扒拉下来,具体怎么扒拉,我们得先分析这个网页,看那块内容是我们需要的.比如,这次爬取的是捧腹网上的笑话,打
-
使用Python实现下载网易云音乐的高清MV
Python下载网易云音乐的高清MV,没有从首页进去解析,直接循环了.... downPage1.py 复制代码 代码如下: #coding=utf-8 import urllib import re import os def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getVideo(html): reg = r'hurl=(.+?\.jpg)'
-
Python爬取网易云音乐上评论火爆的歌曲
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论.但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬一爬网易云音乐上那些热评的歌曲. 结果 对过程没有兴趣的童鞋直接看这里啦. 评论数大于五万的歌曲排行榜 首先恭喜一下我最喜欢的歌手(之一)周杰伦的<晴天>成为网易云音乐第一首评论数过百万的歌曲! 通过结果发现目前评论数过十万的歌曲正好十首,通过这
-
Python3实战之爬虫抓取网易云音乐的热门评论
前言 之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了.于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫.我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步. 废话就不多说了-下面来一起看看详细的介绍吧. 我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论. 这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论. 实现分析 首先,我们打开网易云网
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-
Scrapy+Selenium自动获取cookie爬取网易云音乐个人喜爱歌单
此货很干,跟上脚步!!! Cookie cookie是什么东西? 小饼干?能吃吗? 简单来说就是你第一次用账号密码访问服务器 服务器在你本机硬盘上设置一个身份识别的会员卡(cookie) 下次再去访问的时候只要亮一下你的卡片(cookie) 服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上 需求分析 爬虫要访问一些私人的数据就需要用cookie进行伪装 想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去 但是在火狐的F12截取到的数据就是, 网易云音乐先将你的
-
python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comments(res): comments_json = json.loads(res.text) hot_comments = comments_json['hotComments'] with open("hotcmments.txt", 'w', encoding = 'utf-8') a
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-
python爬取网易云音乐排行榜实例代码
目录 网易云音乐排行榜歌曲及评论爬取 一.模拟登录 二.排行榜数据爬取 三.排行榜评论获取 总结 网易云音乐排行榜歌曲及评论爬取 主要注意问题:selenium 模拟登录.iframe标签定位.页面元素提取. 在利用selenium定位元素并取值的过程中遇到问题.比如xpath正确但无法定位,在进行翻页提取评论的过程中,利用selenium似乎不能提取不同页的数据,比如,明明定位的第三页的评论数据,而只能返回第一页的评论数据. 一.模拟登录 selenium 定位元素模拟人的操作进行登录,直接上
-
Android项目实战教程之高仿网易云音乐启动页实例代码
前言 本文主要给大家介绍了关于Android高仿网易云音乐启动页的相关内容,这一节我们来讲解启动界面,效果如下: 首次创建一个SplashActivity用来做启动界面,因为创建完项目默认是MainActivity做主界面,所以需要去掉,将启动配置到同时去掉SplashActivity,并且去掉SplashActivity的标题栏,同时还要设置为全屏. Activity启动配置 在清单文件将启动配置剪贴到SplashActivity: <activity android:name=".ac
-
利用Python网络爬虫爬取各大音乐评论的代码
python爬虫--爬取网易云音乐评论 方1:使用selenium模块,简单粗暴.但是虽然方便但是缺点也是很明显,运行慢等等等. 方2:常规思路:直接去请求服务器 1.简易看出评论是动态加载的,一定是ajax方式. 2.通过网络抓包,可以找出评论请求的的URL 得到请求的URL 3.去查看post请求所上传的数据 显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密. 4.首先去查看请求是经过那些js到达服务器的 5.设置断点:依次对所发送的内容进行观察,找到评论对应的UR