基于nodejs 的多页面爬虫实例代码
前言
前端时间再回顾了一下node.js,于是顺势做了一个爬虫来加深自己对node的理解。
主要用的到是request,cheerio,async三个模块
request
用于请求地址和快速下载图片流。 https://github.com/request/request
cheerio
为服务器特别定制的,快速、灵活、实施的jQuery核心实现.
便于解析html代码。 https://www.npmjs.com/package/cheerio
async
异步调用,防止堵塞。 http://caolan.github.io/async/
核心思路
- 用request 发送一个请求。获取html代码,取得其中的img标签和a标签。
- 通过获取的a表情进行递归调用。不断获取img地址和a地址,继续递归
- 获取img地址通过request(photo).pipe(fs.createWriteStream(dir + “/” + filename));进行快速下载。
function requestall(url) {
request({
uri: url,
headers: setting.header
}, function (error, response, body) {
if (error) {
console.log(error);
} else {
console.log(response.statusCode);
if (!error && response.statusCode == 200) {
var $ = cheerio.load(body);
var photos = [];
$('img').each(function () {
// 判断地址是否存在
if ($(this).attr('src')) {
var src = $(this).attr('src');
var end = src.substr(-4, 4).toLowerCase();
if (end == '.jpg' || end == '.png' || end == '.jpeg') {
if (IsURL(src)) {
photos.push(src);
}
}
}
});
downloadImg(photos, dir, setting.download_v);
// 递归爬虫
$('a').each(function () {
var murl = $(this).attr('href');
if (IsURL(murl)) {
setTimeout(function () {
fetchre(murl);
}, timeout);
timeout += setting.ajax_timeout;
} else {
setTimeout(function () {
fetchre("http://www.ivsky.com/" + murl);
}, timeout);
timeout += setting.ajax_timeout;
}
})
}
}
});
}
防坑
1.在request通过图片地址下载时,绑定error事件防止爬虫异常的中断。
2.通过async的mapLimit限制并发。
3.加入请求报头,防止ip被屏蔽。
4.获取一些图片和超链接地址,可能是相对路径(待考虑解决是否有通过方法)。
function downloadImg(photos, dir, asyncNum) {
console.log("即将异步并发下载图片,当前并发数为:" + asyncNum);
async.mapLimit(photos, asyncNum, function (photo, callback) {
var filename = (new Date().getTime()) + photo.substr(-4, 4);
if (filename) {
console.log('正在下载' + photo);
// 默认
// fs.createWriteStream(dir + "/" + filename)
// 防止pipe错误
request(photo)
.on('error', function (err) {
console.log(err);
})
.pipe(fs.createWriteStream(dir + "/" + filename));
console.log('下载完成');
callback(null, filename);
}
}, function (err, result) {
if (err) {
console.log(err);
} else {
console.log(" all right ! ");
console.log(result);
}
})
}
测试:

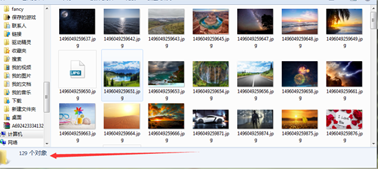
可以感觉到速度还是比较快的。
完整地址。https://github.com/hua1995116/node-crawler/
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

NodeJS制作爬虫全过程(续)
书接上回,我们需要修改程序以达到连续抓取40个页面的内容.也就是说我们需要输出每篇文章的标题.链接.第一条评论.评论用户和论坛积分. 如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户. {<1>} 在eventproxy获取评论及用户名内容后,我们需要通过用户名跳到用户界面继续抓取该用户积分 复制代码 代码如下: var $ = cheerio.load(topicHtml); //此URL为下一步抓取目标URL var
-
详解nodejs爬虫程序解决gbk等中文编码问题
使用nodejs写了一个爬虫的demo,目的是提取网页的title部分. 遇到最大的问题就是网页的编码与nodejs默认编码不一致造成的乱码问题.nodejs支持utf8, ucs2, ascii, binary, base64, hex等编码方式,但是对于汉语言来说编码主要分为三种,utf-8,gb2312,gbk.这里面gbk是完全兼容gb2312的,因此在处理编码的时候主要就分为utf-8以及gbk两大类.(这是在没有考虑到其他国家的编码情况,比如日本的Shift_JIS编码等,同时这里这
-
nodejs制作爬虫实现批量下载图片
今天想获取一大批猫的图片,然后就在360流浪器搜索框中输入 猫 ,然后点击图片.就看到了一大波猫的图片: http://image.so.com/i?q=%E7%8... ,我在想啊,要是审查元素,一张张手动下载,多麻烦,所以打算写程序来实现.不写不知道,一写发现里面还是有很多道道的. 1. 爬取图片链接 因为之前也写过nodejs爬虫功能(参见:NodeJS制作爬虫全过程),所以觉得应该很简单,就用cheerio来处理dom啦,结果打印一下啥也没有,后来查看源代码: 发现 waterfall_
-
简单好用的nodejs 爬虫框架分享
这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了.什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓. 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用. 第一步:安装 Crawl-pet nodejs 就不用多介绍吧,用 npm 安装 crawl-pet $ npm install crawl-pet -g --production 运行,程序会引导你完成配置,首次运行,会在项目目录下生成 info.json 文件 $
-
nodejs爬虫抓取数据之编码问题
cheerio DOM化并解析的时候 1.假如使用了 .text()方法,则一般不会有html实体编码的问题出现 2.如果使用了 .html()方法,则很多情况下(多数是非英文的时候)都会出现,这时,可能就需要转义一番了 类似这些 因为需要作数据存储,所有需要转换 复制代码 代码如下: Халк крушит. Новый способ исполнен 大多数都是&#(x)?\w+的格式 所以就用正则转换一番 var body = ....//这里就是请求后获得的返回数据,或者那些 .html
-
NodeJS制作爬虫全过程
今天来学习alsotang的爬虫教程,跟着把CNode简单地爬一遍. 建立项目craelr-demo 我们首先建立一个Express项目,然后将app.js的文件内容全部删除,因为我们暂时不需要在Web端展示内容.当然我们也可以在空文件夹下直接 npm install express来使用我们需要的Express功能. 目标网站分析 如图,这是CNode首页一部分div标签,我们就是通过这一系列的id.class来定位我们需要的信息. 使用superagent获取源数据 superagent就是
-
nodejs爬虫抓取数据乱码问题总结
一.非UTF-8页面处理. 1.背景 windows-1251编码 比如俄语网站:https://vk.com/cciinniikk 可耻地发现是这种编码 所有这里主要说的是 Windows-1251(cp1251)编码与utf-8编码的问题,其他的如 gbk就先不考虑在内了~ 2.解决方案 1. 使用js原生编码转换 但是我现在还没找到办法哈.. 如果是utf-8转window-1251还可以http://stackoverflow.com/questions/2696481/encoding
-
nodeJS实现简单网页爬虫功能的实例(分享)
本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/hotrank var http = require('http'); http.get('http://tuijian.hao123.com/hotrank',function(res){ var data = ''; res.on('data',function(chunk){ data += chunk;
-
nodeJs爬虫获取数据简单实现代码
本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下 var http=require('http'); var cheerio=require('cheerio');//页面获取到的数据模块 var url='http://www.jcpeixun.com/lesson/1512/'; function filterData(html){ /*所要获取到的目标数组 var courseData=[{ chapterTitle:"", videosData:{ v
-
nodejs爬虫遇到的乱码问题汇总
上一篇文章中使用nodejs程序解析了网页编码为gbk,gb2312,以及utf-8的情况,这里面有三种特殊的乱码情况需要单独的说明一下. 1,网页编码为utf-8,但是解析为乱码,代表网站为www.guoguo-app.com. 这个问题真是个逗逼问题,查看网页源码中给出的编码方式为utf8,如下: <meta charset="UTF-8"> <title>查快递</title> 由于解析出来的始终是乱码,我就抓包看了下,报文中的编码方式为gbk
-
Nodejs爬虫进阶教程之异步并发控制
之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回答才会再加载一部分,所以说如果直接发送一个问题的请求链接,取得的页面是不完整的.还有就是我们通过发送链接下载图片的时候,是一张一张来下的,如果图片数量太多的话,真的是下到你睡完觉它还在下,而且我们用nodejs写的爬虫,却竟然没有用到nodejs最牛逼的异步并发的特性,太浪费了啊. 思路 这次的的爬虫是上次那个的升级版,不过呢,上次那个虽