Python构建简单线性回归模型
目录
- 线性回归模型
- 1.加载数据
- 2.划分训练集和测试集
- 3.训练模型
- 4.预测数据
- 5.画图展示线性拟合情况
- 6.预测数据测试
- 评估模型精度
- 1.计算回归模型精度
- 模型持久化
前言:
本文介绍如何构建简单线性回归模型及计算其准确率,最后介绍如何持久化模型。
线性回归模型
线性回归表示发现函数使用线性组合表示输入变量。简单线性回归很容易理解,使用了基本的回归技术,一旦理解了这些基本概念,可以更好地学习其他类型的回归模型。
回归用于发现输入变量和输出变量之间的关系,一般变量为实数。我们的目标是估计映射从输入到输出的映射核函数。
下面从一个简单示例开始:
1 --> 2 3 --> 6 4.3 --> 8.6 1.1 --> 14.2
看到上面数据,估计你已经看出它们之间的关系:f(x) = 2x
但是现实数据不会这么直接。下面示例数据来自Vehicles.txt文件。每行数据使用逗号分割,第一个数据为输入数据,第二个为输出数据,我们的目标是发现线性回归关系:基于汽车登记量估计省份人口数量。
示例数据如下:
145263, 127329
204477, 312027
361034, 573694
616716, 891181
885665, 1059114
773600, 1221218
850513, 1326513
996733, 1543752
827967, 1571053
1011436,1658138
1222738,1970521
2404651,3744398
2259795,4077166
2844588,4404246
2774071,4448146
3011089,4915123
3169307,5074261
3346791,5850850
3702114,5888472
5923476,10008349
1.加载数据
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
import sklearn.metrics as sm
import pickle
filename = "data/vehicles.txt"
x = []
y = []
with open(filename, 'r') as lines:
for line in lines:
xt, yt = [float(i) for i in line.split(',')]
x.append(xt)
y.append(yt)
上面代码加载文件至x,y变量中,x是自变量,y是响应变量。在循环内读取每一行,然后基于逗号分裂为两个变量并转为浮点型。
2.划分训练集和测试集
构建机器学习模型,需要划分训练集和测试集,训练集用于构建模型,测试集用于验证模型并检查模型是否满足要求。
num_training = int(0.8 * len(x)) num_test = len(x) - num_training # 训练数据占80% x_train = np.array(x[: num_training]).reshape((num_training, 1)) y_train = np.array(y[: num_training]) # 测试数据占20% x_test = np.array(x[num_training:]).reshape((num_test, 1)) y_test = np.array(y[num_training:])
首先取80%数据作为训练集,剩余的作为测试集。这时我们构造了四个数组:x_train,x_test,y_train,y_test。
3.训练模型
现在准备训练模型,需要使用regressor对象。
# Create linear regression object linear_regressor = linear_model.LinearRegression() # Train the model using the training sets linear_regressor.fit(x_train, y_train)
首先从sklearn库中导入linear_model方法,用于实现线性回归,里面包括目标值:输入变量的线性组合。然后使用LinearRegression() 函数执行最小二乘法执行线性回归。最后fit函数用于拟合线性模型,需要传入两个参数:x_train,y_train。
4.预测数据
上面基于训练集拟合线性模型,使用fit方法接收训练数据训练模型。为了查看拟合程度,我们可以使用训练数据进行预测:
y_train_pred = linear_regressor.predict(X_train)
5.画图展示线性拟合情况
plt.figure()
plt.scatter(x_train, y_train, color='green')
plt.plot(x_train, y_train_pred, color='black', linewidth=4)
plt.title('Training data')
plt.show()
生成图示如下:
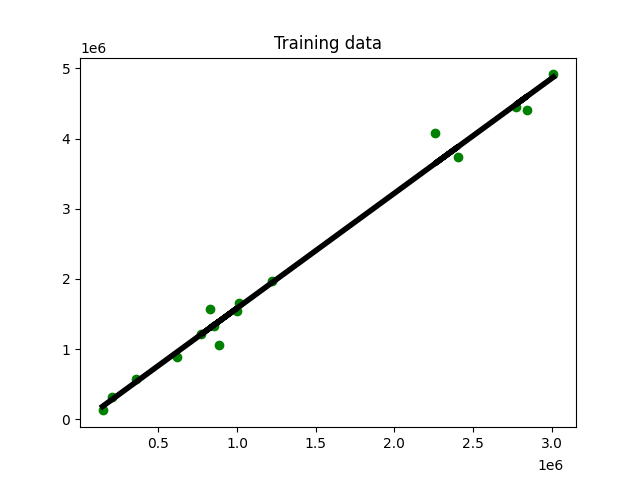
前面使用训练模型预测训练数据。对于未知数据不能确定模型性能,我们需要基于测试数据进行测试。
6.预测数据测试
下面基于测试数据进行预测并画图展示:
y_test_pred = linear_regressor.predict(x_test)
plt.figure()
plt.scatter(x_test, y_test, color='green')
plt.plot(x_test, y_test_pred, color='black', linewidth=4)
plt.title('Test data')
plt.show()
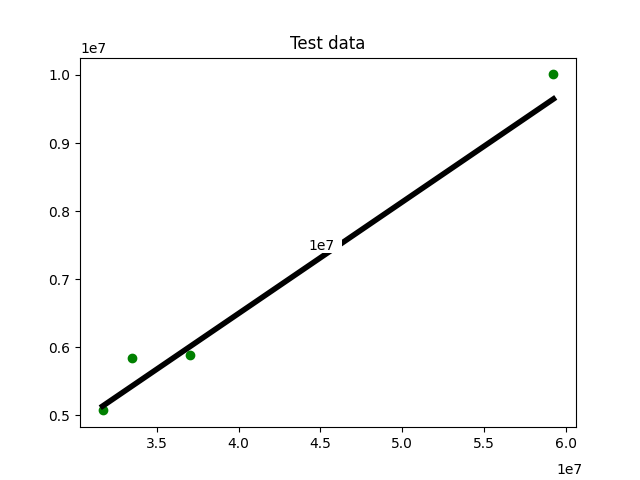
与我们预想的一致,省人口与汽车注册量成正相关。
评估模型精度
上面构建了回归模型,但我们需要评估模型的质量。这里我们定义错误为实际值与预测值之间的差异,下面我们看如何计算回归模型的精度。
1.计算回归模型精度
print("MAE =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("MSE =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =",
round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =",
round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
输出结果:
MAE = 241907.27
MSE = 81974851872.13
Median absolute error = 240861.94
Explain variance score = 0.98
R2 score = 0.98
R2得分接近1表示模型预测效果非常好。计算每个指标会很麻烦,一般选择一两个指标来评估模型。一个好的做法是MSE较低,解释方差得分较高。
- Mean absolute error: 所有数据集的平均绝对值误差
- Mean squared error: 所有数据集的平均误差平方,是最常用的指标之一。
- Median absolute error: 所有数据集的误差中位数,该指标主要用于消除异常值影响
- Explained variance score: 模型在多大程度上能够解释数据集中的变化。1.0的分数表明我们的模型是完美的。
- R2 score: 这被读作r²,是决定系数。表示模型对未知样本的预测程度。最好的分数是1.0,但也可以是负值。
模型持久化
训练完模型,可以保存至文件中,下次需要模型预测可直接从文件加载。
下面看如何持久化模型。需要使用pickle模块,实现存储Python对象,它是Python标准库的一部分。
# 写入文件
output_model_file = "3_model_linear_regr.pkl"
with open(output_model_file, ' wb') as f:
pickle.dump(linear_regressor, f)
# 加载使用
with open(output_model_file, ' rb') as f:
model_linregr = pickle.load(f)
y_test_pred_new = model_linregr.predict(x_test)
print("New mean absolute error =",
round(sm.mean_absolute_error(y_test, y_test_pred_new), 2))
输出结果:
New mean absolute error = 241907.27
这里从文件加载数据至model_linregr变量,预测结果与上面一致。
到此这篇关于Python构建简单线性回归模型的文章就介绍到这了,更多相关Python线性回归内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 机器学习之线性回归详解分析
为了检验自己前期对机器学习中线性回归部分的掌握程度并找出自己在学习中存在的问题,我使用C语言简单实现了单变量简单线性回归. 本文对自己使用C语言实现单变量线性回归过程中遇到的问题和心得做出总结. 线性回归 线性回归是机器学习和统计学中最基础和最广泛应用的模型,是一种对自变量和因变量之间关系进行建模的回归分析. 代码概述 本次实现的线性回归为单变量的简单线性回归,模型中含有两个参数:变量系数w.偏置q. 训练数据为自己使用随机数生成的100个随机数据并将其保存在数组中.采用批量梯度下降法训练模型,
-
人工智能—Python实现线性回归
1.概述 (1)人工智能学习 (2)机器学习 (3)有监督学习 (4)线性回归 2.线性回归 (1)实现步骤 根据随机初始化的 w x b 和 y 来计算 loss 根据当前的 w x b 和 y 的值来计算梯度 更新梯度,循环将新的 w′ 和 b′ 复赋给 w 和 b ,最终得到一个最优的 w′ 和 b′ 作为方程最终的 (2)数学表达式 3.代码实现(Python) (1)机器学习库(sklearn.linear_model) 代码: from sklearn import linear_m
-
python机器学习基础线性回归与岭回归算法详解
目录 一.什么是线性回归 1.线性回归简述 2.数组和矩阵 数组 矩阵 3.线性回归的算法 二.权重的求解 1.正规方程 2.梯度下降 三.线性回归案例 1.案例概述 2.数据获取 3.数据分割 4.数据标准化 5.模型训练 6.回归性能评估 7.梯度下降与正规方程区别 四.岭回归Ridge 1.过拟合与欠拟合 2.正则化 一.什么是线性回归 1.线性回归简述 线性回归,是一种趋势,通过这个趋势,我们能预测所需要得到的大致目标值.线性关系在二维中是直线关系,三维中是平面关系. 我们可以使用如下模
-
Python线性回归图文实例详解
目录 前言: 1.简单线性回归模型 2.多元线性回归模型 2.1 应用F检验法完成模型的显著性检验 2.2应用t检验法完成回归系数的显著性检验 3.基于回归模型识别异常点 4.含有离散变量的回归模型 1.删除无意义的变量 2.哑变量转换 3.将数据拆分为两部分 4.构建多元线性回归模型 5.未知年龄的预测 总结 前言: 线性回归模型属于经典的统计学模型,该模型的应用场景是根据已知的变量(即自变量)来预测某个连续的数值变量(即因变量).例如餐厅根据媒体的营业数据(包括菜谱价格.就餐人数.预订人数.
-
python数据分析之线性回归选择基金
目录 1 前言 2 基金趋势分析 3 数据抓取与分析 3.1 基金数据抓取 3.2 数据分析 4 总结 1 前言 在前面的章节中我们牛刀小试,一直在使用python爬虫去抓取数据,然后把数据信息存放在数据库中,至此已经完成了基本的基本信息的处理,接下来就来处理高级一点儿的内容,今天就从基金的趋势分析开始. 2 基金趋势分析 基金的趋势,就是选择一些表现强势的基金,什么样的才是强势呢?那就是要稳定的,逐步的一路北上.通常情况下,基金都会沿着一条趋势线向上或者向下,基金的趋势形成比股票的趋势更加确定
-
python实现线性回归的示例代码
目录 1线性回归 1.1简单线性回归 1.2多元线性回归 1.3使用sklearn中的线性回归模型 1线性回归 1.1简单线性回归 在简单线性回归中,通过调整a和b的参数值,来拟合从x到y的线性关系.下图为进行拟合所需要优化的目标,也即是MES(Mean Squared Error),只不过省略了平均的部分(除以m). 对于简单线性回归,只有两个参数a和b,通过对MSE优化目标求极值(最小二乘法),即可求得最优a和b如下,所以在训练简单线性回归模型时,也只需要根据数据求解这两个参数值即可. 下面
-
Python数学建模StatsModels统计回归之线性回归示例详解
目录 1.背景知识 1.1 插值.拟合.回归和预测 1.2 线性回归 2.Statsmodels 进行线性回归 2.1 导入工具包 2.2 导入样本数据 2.3 建模与拟合 2.4 拟合和统计结果的输出 3.一元线性回归 3.1 一元线性回归 Python 程序: 3.2 一元线性回归 程序运行结果: 4.多元线性回归 4.1 多元线性回归 Python 程序: 4.2 多元线性回归 程序运行结果: 5.附录:回归结果详细说明 1.背景知识 1.1 插值.拟合.回归和预测 插值.拟合.回归和预测
-
Python构建简单线性回归模型
目录 线性回归模型 1.加载数据 2.划分训练集和测试集 3.训练模型 4.预测数据 5.画图展示线性拟合情况 6.预测数据测试 评估模型精度 1.计算回归模型精度 模型持久化 前言: 本文介绍如何构建简单线性回归模型及计算其准确率,最后介绍如何持久化模型. 线性回归模型 线性回归表示发现函数使用线性组合表示输入变量.简单线性回归很容易理解,使用了基本的回归技术,一旦理解了这些基本概念,可以更好地学习其他类型的回归模型. 回归用于发现输入变量和输出变量之间的关系,一般变量为实数.我们的目标是估计
-
使用Keras实现简单线性回归模型操作
神经网络可以用来模拟回归问题 (regression),实质上是单输入单输出神经网络模型,例如给下面一组数据,用一条线来对数据进行拟合,并可以预测新输入 x 的输出值. 一.详细解读 我们通过这个简单的例子来熟悉Keras构建神经网络的步骤: 1.导入模块并生成数据 首先导入本例子需要的模块,numpy.Matplotlib.和keras.models.keras.layers模块.Sequential是多个网络层的线性堆叠,可以通过向Sequential模型传递一个layer的list来构造该
-
使用TensorFlow实现简单线性回归模型
本文使用TensorFlow实现最简单的线性回归模型,供大家参考,具体内容如下 线性拟合y=2.7x+0.6,代码如下: import tensorflow as tf import numpy as np import matplotlib.pyplot as plt n = 201 # x点数 X = np.linspace(-1, 1, n)[:,np.newaxis] # 等差数列构建X,[:,np.newaxis]这个是shape,这一行构建了一个n维列向量([1,n]的矩阵) noi
-
用tensorflow构建线性回归模型的示例代码
用tensorflow构建简单的线性回归模型是tensorflow的一个基础样例,但是原有的样例存在一些问题,我在实际调试的过程中做了一点自己的改进,并且有一些体会. 首先总结一下tf构建模型的总体套路 1.先定义模型的整体图结构,未知的部分,比如输入就用placeholder来代替. 2.再定义最后与目标的误差函数. 3.最后选择优化方法. 另外几个值得注意的地方是: 1.tensorflow构建模型第一步是先用代码搭建图模型,此时图模型是静止的,是不产生任何运算结果的,必须使用Session
-
python实现简单的单变量线性回归方法
线性回归是机器学习中的基础算法之一,属于监督学习中的回归问题,算法的关键在于如何最小化代价函数,通常使用梯度下降或者正规方程(最小二乘法),在这里对算法原理不过多赘述,建议看吴恩达发布在斯坦福大学上的课程进行入门学习. 这里主要使用python的sklearn实现一个简单的单变量线性回归. sklearn对机器学习方法封装的十分好,基本使用fit,predict,score,来训练,预测,评价模型, 一个简单的事例如下: from pandas import DataFrame from pan
-
Python api构建tensorrt加速模型的步骤详解
目录 一.创建TensorRT有以下几个步骤: 二.Python api和C++ api在实现网络加速有什么区别? 三.构建TensorRT加速模型 3.1 加载tensorRT 3.2 创建网络 3.3 ONNX构建engine 一.创建TensorRT有以下几个步骤: 1.用TensorRT中network模块定义网络模型 2.调用TensorRT构建器从网络创建优化的运行时引擎 3.采用序列化和反序列化操作以便在运行时快速重建 4.将数据喂入engine中进行推理 二.Python api
-
Python实现的简单线性回归算法实例分析
本文实例讲述了Python实现的简单线性回归算法.分享给大家供大家参考,具体如下: 用python实现R的线性模型(lm)中一元线性回归的简单方法,使用R的women示例数据,R的运行结果: > summary(fit) Call: lm(formula = weight ~ height, data = women) Residuals: Min 1Q Median 3Q Max -1.7333 -1.1333 -0.3833 0.7417 3.116
-
Python人工智能构建简单聊天机器人示例详解
目录 引言 什么是聊天机器人? 准备工作 创建聊天机器人 导入必要的库 定义响应集合 创建聊天机器人 运行聊天机器人 完整代码 结论 展望 引言 人工智能是计算机科学中一个非常热门的领域,近年来得到了越来越多的关注.它通过模拟人类思考过程和智能行为来实现对复杂任务的自主处理和学习,已经被广泛应用于许多领域,包括语音识别.自然语言处理.机器人技术.图像识别和推荐系统等. 本文将介绍如何使用Python构建一个简单的聊天机器人,以展示人工智能的基本原理和应用.我们将使用Python语言和自然语言处理
-
Python scikit-learn 做线性回归的示例代码
一.概述 机器学习算法在近几年大数据点燃的热火熏陶下已经变得被人所"熟知",就算不懂得其中各算法理论,叫你喊上一两个著名算法的名字,你也能昂首挺胸脱口而出.当然了,算法之林虽大,但能者还是有限,能适应某些环境并取得较好效果的算法会脱颖而出,而表现平平者则被历史所淡忘.随着机器学习社区的发展和实践验证,这群脱颖而出者也逐渐被人所认可和青睐,同时获得了更多社区力量的支持.改进和推广. 以最广泛的分类算法为例,大致可以分为线性和非线性两大派别.线性算法有著名的逻辑回归.朴素贝叶斯.最大熵等,
-
python构建深度神经网络(续)
这篇文章在前一篇文章:python构建深度神经网络(DNN)的基础上,添加了一下几个内容: 1) 正则化项 2) 调出中间损失函数的输出 3) 构建了交叉损失函数 4) 将训练好的网络进行保存,并调用用来测试新数据 1 数据预处理 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017-03-12 15:11 # @Author : CC # @File : net_load_data.py from numpy import