R语言在散点图中添加lm线性回归公式的问题
目录
- 1. 简单的线性回归
- 2. 使用ggplot2展示
1. 简单的线性回归
函数自带的例子(R 中键入?lm),lm(y ~ x)回归y=kx + b, lm( y ~ x -1 )省略b,不对截距进行估计:
require(graphics)
## Annette Dobson (1990) "An Introduction to Generalized Linear Models".
## Page 9: Plant Weight Data.
ctl <- c(4.17,5.58,5.18,6.11,4.50,4.61,5.17,4.53,5.33,5.14)
trt <- c(4.81,4.17,4.41,3.59,5.87,3.83,6.03,4.89,4.32,4.69)
group <- gl(2, 10, 20, labels = c("Ctl","Trt"))
weight <- c(ctl, trt)
lm.D9 <- lm(weight ~ group)
lm.D90 <- lm(weight ~ group - 1) # omitting intercept
anova(lm.D9)
summary(lm.D90)
opar <- par(mfrow = c(2,2), oma = c(0, 0, 1.1, 0))
plot(lm.D9, las = 1) # Residuals, Fitted, ...
par(opar)
使用R中自带的mtcars数据,可以得到截距和斜率,也可以得到解释率R-square:
require(ggplot2)
library(dplyr) #加载dplyr包
library(ggpmisc) #加载ggpmisc包
library(ggpubr)
require(gridExtra)
model=lm(mtcars$wt ~ mtcars$mpg)
model
## 输出:
Call:
lm(formula = mtcars$wt ~ mtcars$mpg)
Coefficients:
(Intercept) mtcars$mpg
6.047 -0.141
```
```handlebars
summary(model)
## 输出:
Call:
lm(formula = mtcars$wt ~ mtcars$mpg)
Residuals:
Min 1Q Median 3Q Max
-0.652 -0.349 -0.138 0.319 1.368
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.0473 0.3087 19.59 < 2e-16 ***
mtcars$mpg -0.1409 0.0147 -9.56 1.3e-10 ***
---
Signif. codes: 0 ‘***' 0.001 ‘**' 0.01 ‘*' 0.05 ‘.' 0.1 ‘ ' 1
Residual standard error: 0.494 on 30 degrees of freedom
Multiple R-squared: 0.753, Adjusted R-squared: 0.745
F-statistic: 91.4 on 1 and 30 DF, p-value: 1.29e-10
提取回归R-square值:
通过summary提取: ## 上面的例子 ## mtcars例子 model=lm(mtcars$wt ~ mtcars$mpg) res=summary(model) str(res) ## 提取各个值: res$r.squared res$coefficients res$adj.r.squared ## df 矫正后的结果 res$coefficients[1,1] res$coefficients[2,1]
使用默认的plot绘制回归散点:
plot(mtcars$mpg, mtcars$wt, pch=20,cex=2) abline(model,col="red",lwd=2)
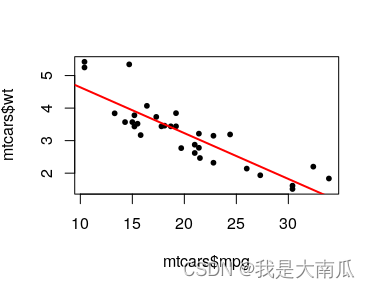
计算Confidence interval(95%):
test=mtcars[c("mpg","wt")]
head(test)
colnames(test)=c("x","y")
model = lm(y ~ x, test)
test$predicted = predict(
object = model,
newdata = test)
test$CI = predict(
object = model,
newdata = test,
se.fit = TRUE
)$se.fit * qt(1 - (1-0.95)/2, nrow(test))
test$predicted = predict(
object = model,
newdata = test)
test$CI_u=test$predicted+test$CI
test$CI_l=test$predicted-test$CI
plot(mtcars$mpg, mtcars$wt, pch=20,cex=1) ## have replicated x values
abline(model,col="red",lwd=2)
lines(x=test$x,y=test$CI_u,col="blue")
lines(x=test$x,y=test$CI_l,col="blue")
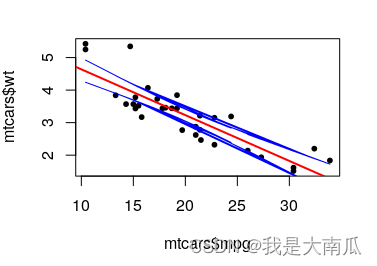
上面的图蓝线有点奇怪,简单绘制最初的plot:
plot(mtcars$mpg, mtcars$wt, pch=20,cex=1,type="b") ## have replicated x values
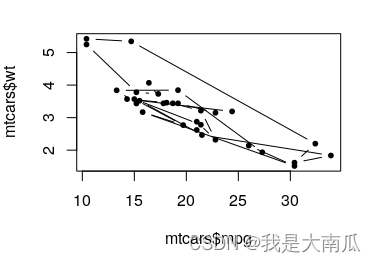
实际上面的计算方法没问题,但是数据不合适,因为数据x含有重复值,所以要考虑这个。
2. 使用ggplot2展示
ggplot2例子:
p <- ggplot(df, aes(x=yreal, y=ypred)) +
geom_point(color = "grey20",size = 1, alpha = 0.8)
#回归线
#添加回归曲线
p2 <- p + geom_smooth(formula = y ~ x, color = "red",
fill = "blue", method = "lm",se = T, level=0.95) +
theme_bw() +
stat_poly_eq(
aes(label = paste(..eq.label.., ..adj.rr.label.., sep = '~~~')),
formula = y ~ x, parse = TRUE,color="blue",
size = 5, #公式字体大小
label.x = 0.05, #位置 ,0-1之间的比例
label.y = 0.95) +
labs(title="test",x="Real Value (Huang Huaihai 1777)" , y="Predicted Value (Correlation: 0.5029)")
p2
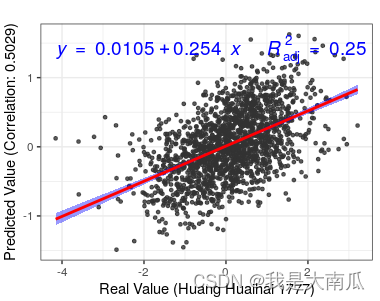
ggplot版本的手动计算:
require(ggplot2)
library(dplyr) #加载dplyr包
library(ggpmisc) #加载ggpmisc包
library(ggpubr)
require(gridExtra)
ggplot(data=df, aes(x=yreal, y=ypred)) +
geom_smooth(formula = y ~ x, color = "blue",
fill = "grey10", method = "lm") +
geom_point() +
stat_regline_equation(label.x=0.1, label.y=-1.5) +
stat_cor(aes(label=..rr.label..), label.x=0.1, label.y=-2)
test=df
head(test)
colnames(test)=c("x","y")
model = lm(y ~ x, test)
test$predicted = predict(
object = model,
newdata = test)
test$CI = predict(
object = model,
newdata = test,
se.fit = TRUE
)$se.fit * qt(1 - (1-0.95)/2, nrow(test))
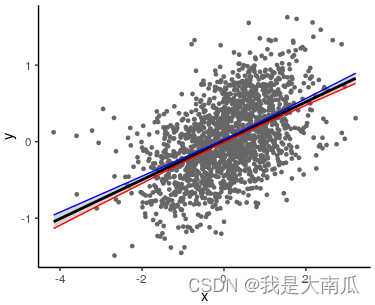
ggplot(test) +
aes(x = x, y = y) +
geom_point(size = 1,colour="grey40") +
geom_smooth(formula =y ~ x,method = "lm", fullrange = TRUE, color = "black") +
geom_line(aes(y = predicted + CI), color = "blue") + # upper
geom_line(aes(y = predicted - CI), color = "red") + # lower
theme_classic()
参考:
https://stackoverflow.com/questions/23519224/extract-r-square-value-with-r-in-linear-models (提取R2)
https://blog.csdn.net/LeaningR/article/details/118971000 (提取R2等)
https://stackoverflow.com/questions/45742987/how-is-level-used-to-generate-the-confidence-interval-in-geom-smooth (添加lm线)
https://zhuanlan.zhihu.com/p/131604431 (知乎)
到此这篇关于R语言在散点图中添加lm线性回归公式的问题的文章就介绍到这了,更多相关R语言线性回归内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言与多元线性回归分析计算案例
目录 计算实例 分析 模型的进一步分析 计算实例 例 6.9 某大型牙膏制造企业为了更好地拓展产品市场,有效地管理库存,公司董事会要求销售部门根据市场调查,找出公司生产的牙膏销售量与销售价格,广告投入等之间的关系,从而预测出在不同价格和广告费用下销售量.为此,销售部门的研究人员收集了过去30个销售周期(每个销售周期为4周)公司生产的牙膏的销售量.销售价格.投入的广告费用,以及周期其他厂家生产同类牙膏的市场平均销售价格,如表6.4所示. 试根据这些数据建立一个数学模型,分析牙膏销售量与其他因素的关
-
R语言如何进行线性回归的拟合度详解
R语言进行线性回归的拟合度. 本文只是使用 R做回归计算,查看拟合度等,不讨论 R 函数的内部公式 在R中线性回归分析的函数是lm(),基本语法是 一元回归: lm(y ~ x,data) 多元回归:lm(y ~ x1+x2+x3-,data) 创建关系模型并获取系数 x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131) y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48) # 使用lm()函数
-
R语言如何实现多元线性回归
R小白几天的摸索 红色为输入,蓝色为输出 输入数据 先把数据用excel保存为csv格式放在"我的文档"文件夹 打开R软件,不用新建,直接写 回归计算 求三个平方和 置信区间(95%) 散点图(最显著的因变量) 拟合图 一元线性回归 结果:(看图) 变量系数 Estimate 变量系数标准误 Std. Error T检验值 t value T检验p值 Pr(>|t|) 均方根误差 Residual standard error 判定系数 R-squared 调整判定系
-
R语言线性回归知识点总结
回归分析是一种非常广泛使用的统计工具,用于建立两个变量之间的关系模型. 这些变量之一称为预测变量,其值通过实验收集. 另一个变量称为响应变量,其值从预测变量派生. 在线性回归中,这两个变量通过方程相关,其中这两个变量的指数(幂)为1.数学上,线性关系表示当绘制为曲线图时的直线. 任何变量的指数不等于1的非线性关系将创建一条曲线. 线性回归的一般数学方程为 y = ax + b 以下是所使用的参数的描述 y是响应变量. x是预测变量. a和b被称为系数常数. 建立回归的步骤 回归的简单例子是当人的
-
R语言实现广义线性回归模型
目录 1 与广义线性模型有关的R函数 2 正态分布族 3 二项分布族 例 R. Norell实验 广义线性模型(GLM)是常见正态线性模型的直接推广,它可以适用于连续数据和离散数据,特别是后者,如属性数据.计数数据.这在应用上,尤其是生物.医学.经济和社会数据的统计分析上,有着重要意义. 对于广义线性模型应有一下三个概念: 第一是线性自变量,它表明第i个响应变量的期望值E(yi)只能通过线性自变量βTxi而依赖于xi,其中如通常一样,β是未知参数的(p+1)x1向量,可能包含截距. 第二是连续
-
R语言实现线性回归的示例
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析. 简单对来说就是用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法. 回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析.如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析. 一元线性回归分析法的数学方程: y = ax + b
-
R语言多元线性回归实例详解
目录 一.模型简介 二.求解过程 总结 一.模型简介 一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归.当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元线性回归. 二.求解过程 这里我使用的数据是包里面自带的数据,我们导入并进行查看: 可以看到第一列是我们的数据标签(无数学含义),后面五列分别为对应的五个特征即相应的数值.我
-
R语言在散点图中添加lm线性回归公式的问题
目录 1. 简单的线性回归 2. 使用ggplot2展示 1. 简单的线性回归 函数自带的例子(R 中键入?lm),lm(y ~ x)回归y=kx + b, lm( y ~ x -1 )省略b,不对截距进行估计: require(graphics) ## Annette Dobson (1990) "An Introduction to Generalized Linear Models". ## Page 9: Plant Weight Data. ctl <- c(4.17,
-
R语言绘制散点图实例分析
散点图显示在笛卡尔平面中绘制的许多点. 每个点表示两个变量的值. 在水平轴上选择一个变量,在垂直轴上选择另一个变量. 使用plot()函数创建简单散点图. 语法 在R语言中创建散点图的基本语法是 - plot(x, y, main, xlab, ylab, xlim, ylim, axes) 以下是所使用的参数的描述 - x是其值为水平坐标的数据集. y是其值是垂直坐标的数据集. main要是图形的图块. xlab是水平轴上的标签. ylab是垂直轴上的标签. xlim是用于绘图的x的值的极限.
-
使用R语言绘制散点图结合边际分布图教程
目录 1. 使用ggExtra结合ggplot2 1)传统散点图 2)密度函数 3)直方图 4)箱线图(宽窄的显示会有些问题) 5)小提琴图(会有重叠,不建议使用) 6)密度函数与直方图同时展现 2. 使用cowplot与ggpubr 1)重绘另一种散点图 2)有缝拼接 3)无缝拼接 参考 主要使用ggExtra结合ggplot2两个R包进行绘制.(胜在简洁方便)使用cowplot与ggpubr进行绘制.(胜在灵活且美观) 下面的绘图我们均以iris数据集为例. 1. 使用ggExtra结合gg
-
R语言数据可视化ggplot添加左右y轴绘制天猫双十一销售图
目录 构造数据集 绘制散点 修改两坐标轴信息 本文是以天猫双十一销量与增长率为例,原始的数据可以参考上一篇文章:用 ggplot 重绘天猫双十一销售额图,这里不再作过多的介绍. 同时整个的天猫双十一的销售额数据分析可以关注:天猫双十一"数据造假"是真的吗? 老规矩,先上最终成果(两张图只是颜色的差别): 上图左边 y 轴表示增长率的刻度,右边 y 轴表示销售额的数据,我们将两者在同一张图上进行展现.其实将两个统计图在同一个坐标系中呈现不算是这个绘图的难点,其真正的难点在与刻度的变换以及
-
如何用R语言绘制散点图
散点图是将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定,每个点对应一个 X 和 Y 轴点坐标. 散点图可以使用 plot() 函数来绘制,语法格式如下: plot(x, y, type="p", main, xlab, ylab, xlim, ylim, axes) x 横坐标 x 轴的数据集合 y 纵坐标 y 轴的数据集合 type:绘图的类型,p 为点.l 为直线, o 同时绘制点和线,且线穿过点. main 图表标题. xlab.
-
R语言数据框中的负索引介绍
以R语言自带的mtcars数据框为例: 这是原始的mtcars数据: 这里只列出了前面几行数据. 然后负索引mtcars[,-2:-3],得到的结果 删除了第二列和第三列数据 所以R语言数据框中的负索引是指删除数据框中对应的列(或者行) ps:这和Python里面的规则好像不太一样,Python里的负索引好像是指倒数第几列(或者第几行),这里这两个软件区别还挺大的~~写个笔记提醒一下自己~ 补充:R语言中的负整数索引 看代码吧~ > x<-matrix(c(1,2,3,4,5,6,7,8,9)
-
R语言删除/添加数据框中的某一行/列
假如数据是这样的,这是有一个数据框 > A <- data.frame(姓名 = c("张三", "李四", "王五"), 体重 = c(50, 70, 80), 视力 = c(5.0, 4.8, 5.2)) > A 姓名 体重 视力 1 张三 50 5.0 2 李四 70 4.8 3 王五 80 5.2 删除第一行"张三"的信息 > A <- A[-1,] > A 姓名 体重 视力 2 李
-
R语言数据可视化包ggplot2画图之散点图的基本画法
目录 前言 下面以一个简单的例子引入: 首先介绍第一类常用的图像类型:散点图 给原始数据加上分类标签: 按z列分类以不同的颜色在图中画出散点图: 按z列分类以不同的形状在图中画出散点图: 多面化(将ABC三类分开展示): 自定义颜色: 添加拟合曲线: 更换主题 : 总结 前言 ggplot2的功能很强大,并因为其出色的画图能力而闻名,下面来介绍一下它的基本画图功能,本期介绍散点图的基本画法. 在ggplot2里,所有图片由6个基本要素组成: 1. 数据(Data) 2. 层次(Layers),包
-
R语言作图:坐标轴的设置方式
要绘制一张赏心悦目的统计图表,坐标轴的设置至关重要.在R语言底层作图中,对坐标轴的调整主要通过调整plot函数.axis函数和title函数的一系列参数完成. plot(x,y, ...) axis(side,at = NULL, labels = TRUE, tick = TRUE, line = NA, pos= NA, outer = FALSE, font = NA, lty = "solid", lwd = 1, lwd.ticks = lwd, col = NULL,col
-
R语言绘制频率直方图的案例
频率直方图是数据统计中经常会用到的图形展示方式,同时在生物学分析中可以更好的展示表型性状的数据分布类型:R基础做图中的hist函数对单一数据的展示很方便,但是当遇到多组数据的时候就不如ggplot2绘制来的方便. *** 1.基础做图hist函数 hist(rnorm(200),col='blue',border='yellow',main='',xlab='') 1.1 多图展示 par(mfrow=c(2,3)) for (i in 1:6) {hist(rnorm(200),border=