Golang WorkerPool线程池并发模式示例详解
目录
- 正文
- 处理CVS文件记录
- 获取测试数据
- 线程池耗时差异
正文
Worker Pools 线程池是一种并发模式。该模式中维护了固定数量的多个工作器,这些工作器等待着管理者分配可并发执行的任务。该模式避免了短时间任务创建和销毁线程的代价。
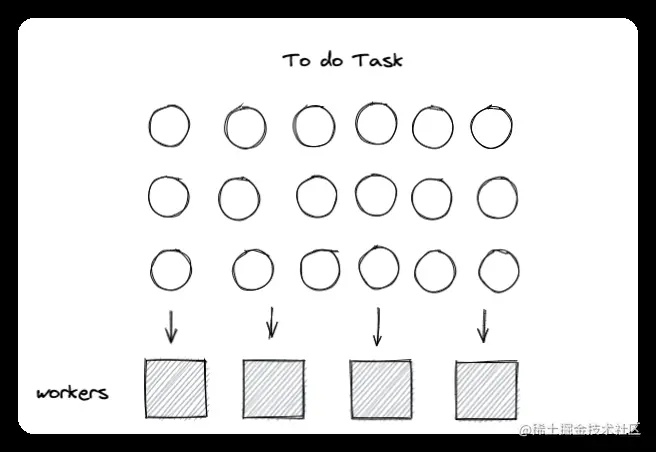
在 golang 中,我们使用 goroutine 和 channel 来构建这种模式。工作器 worker 由一个 goroutine 定义,该 goroutine 通过 channel 获取数据。
处理CVS文件记录
接下来让我们通过一个例子,来进一步理解该模式。假设您需要处理来自 CVS 文件的记录数据,我们需要将该文件中的经纬度保存到数据库中。代码如下。
package main
import (
"encoding/csv"
"fmt"
"os"
"time"
)
type city struct {
name string
location string
}
func createCity(record city) {
time.Sleep(10 * time.Millisecond)
}
func main() {
startTime := time.Now()
csvFile, err := os.Open("cities.csv")
if err != nil {
fmt.Println(err)
}
fmt.Println("Successfully Opened CSV file")
defer csvFile.Close()
csvLines, err := csv.NewReader(csvFile).ReadAll()
if err != nil {
fmt.Println(err)
}
counter := 0
for _, line := range csvLines {
counter++
createCity(city{
name: line[0],
location: line[1],
})
}
fmt.Println("records saved:", counter)
fmt.Println("total time:", time.Since(startTime))
}
获取测试数据

输出:
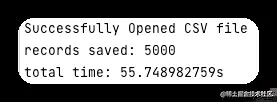
正如我们所看到的,保存 CSV 中所有记录需要 55 秒,这是很长的时间,可能会导致很多性能问题。用户如果想要上传 CSV 文件,那体验感一定很差。
如何解决这个问题?那我们就使用线程池的方法试试看。
线程池耗时差异
在如下示例中,我们将解决相同的需求,但通过线程池,耗时方面,我们能够看到巨大的差异。来吧!
代码如下
package main
import (
"encoding/csv"
"fmt"
"os"
"time"
)
type city struct {
name string
location string
}
func createCity(record city) {
time.Sleep(10 * time.Millisecond)
}
func readData(cityChn chan []city) {
var cities []city
csvFile, err := os.Open("cities.csv")
if err != nil {
fmt.Println(err)
}
fmt.Println("Successfully Opened CSV file")
defer csvFile.Close()
csvLines, err := csv.NewReader(csvFile).ReadAll()
if err != nil {
fmt.Println(err)
}
for _, line := range csvLines {
cities = append(cities, city{
name: line[0],
location: line[1],
})
}
cityChn <- cities
}
func worker(cityChn chan city) {
for val := range cityChn {
createCity(val)
}
}
func main() {
startTime := time.Now()
cities := make(chan []city)
go readData(cities)
const workers = 5
jobs := make(chan city, 1000)
for w := 1; w <= workers; w++ {
go worker(jobs)
}
counter := 0
for _, val := range <-cities {
counter++
jobs <- val
}
fmt.Println("records saved:", counter)
fmt.Println("total time:", time.Since(startTime))
}
输出:

你看到很大的不同了吗?现在同样的过程只需要 8 秒。正如您所见,当我们需要处理大量数据时,线程池非常有用。
使用线程池,我们必须定义一个函数,在示例中该函数为 worker,该函数用于定义工作进程,您可以看到它接收一个 Channel 通道来处理数据。 另外,我们必须在数据传递到通道之前启动 goroutines 协程,当 Channel 通道获取到值时,goroutines 工作者开始处理它们。
现在您知道如何实现线程池了!
以上就是Golang WorkerPool线程池并发模式示例详解的详细内容,更多关于Golang WorkerPool线程池并发的资料请关注我们其它相关文章!
相关推荐
-

Golang监听日志文件并发送到kafka中
目录 前言 涉及的golang库和可视化工具: 工作的流程 环境准备 代码分层 关键的代码 main.go kafka.go tail.go 前言 日志收集项目的准备中,本文主要讲的是利用golang的tail库,监听日志文件的变动,将日志信息发送到kafka中. 涉及的golang库和可视化工具: go-ini,sarama,tail其中: go-ini:用于读取配置文件,统一管理配置项,有利于后其的维护 sarama:是一个go操作kafka的客户端.目前我用于向kefka发送消息 tail
-
示例剖析golang中的CSP并发模型
目录 1. 相关概念: 2. CSP (通信顺序进程) 3. channel:同步&传递消息 4. goroutine:实际并发执行的实体 5. golang调度器 1. 相关概念: 用户态:当一个进程在执行用户自己的代码时处于用户运行态(用户态) 内核态:当一个进程因为系统调用陷入内核代码中执行时处于内核运行态(内核态),引入内核态防止用户态的程序随意的操作内核地址空间,具有一定的安全保护作用.这种保护模式是通过内存页表操作等机制,保证进程间的地址空间不会相互冲突,一个进程的操作不会修改另一个
-
解析golang中的并发安全和锁问题
1. 并发安全 package main import ( "fmt" "sync" ) var ( sum int wg sync.WaitGroup ) func test() { for i := 0; i < 5000000; i++ { sum += 1 } wg.Done() } func main() { // 并发和安全锁 wg.Add(2) go test() go test() wg.Wait() fmt.Println(sum) } 上面
-
解决Golang并发工具Singleflight的问题
目录 前言 定义 用途 简单Demo 源码分析 结构 对外暴露的方法 重点方法分析 Do 流程图 Forget doCall 实际使用 弊端与解决方案 参考文章 前言 前段时间在一个项目里使用到了分布式锁进行共享资源的访问限制,后来了解到Golang里还能够使用singleflight对共享资源的访问做限制,于是利用空余时间了解,将知识沉淀下来,并做分享 文章尽量用通俗的语言表达自己的理解,从入门demo开始,结合源码分析singleflight的重点方法,最后分享singleflight的实际
-
Go实现线程池(工作池)的两种方式实例详解
worker pool简介 worker pool其实就是线程池thread pool.对于go来说,直接使用的是goroutine而非线程,不过这里仍然以线程来解释线程池. 在线程池模型中,有2个队列一个池子:任务队列.已完成任务队列和线程池.其中已完成任务队列可能存在也可能不存在,依据实际需求而定. 只要有任务进来,就会放进任务队列中.只要线程执行完了一个任务,就将任务放进已完成任务队列,有时候还会将任务的处理结果也放进已完成队列中. worker pool中包含了一堆的线程(worker,
-
Golang并发读取文件数据并写入数据库的项目实践
目录 需求 项目结构 获取data目录下的文件 按行读取文本数据 数据类型定义 并发读取文件 将数据写入数据库 完整main.go代码 测试运行 需求 最近接到一个任务,要把一批文件中的十几万条JSON格式数据写入到Oracle数据库中,Oracle是企业级别的数据库向来以高性能著称,所以尽可能地利用这一特性.当时第一时间想到的就是用多线程并发读文件并操作数据库,而Golang是为并发而生的,用Golang进行并发编程非常方便,因此这里选用Golang并发读取文件并用Gorm操作数据库.然而Go
-
Golang WorkerPool线程池并发模式示例详解
目录 正文 处理CVS文件记录 获取测试数据 线程池耗时差异 正文 Worker Pools 线程池是一种并发模式.该模式中维护了固定数量的多个工作器,这些工作器等待着管理者分配可并发执行的任务.该模式避免了短时间任务创建和销毁线程的代价. 在 golang 中,我们使用 goroutine 和 channel 来构建这种模式.工作器 worker 由一个 goroutine 定义,该 goroutine 通过 channel 获取数据. 处理CVS文件记录 接下来让我们通过一个例子,来进一步理
-
Java中四种线程池的使用示例详解
在什么情况下使用线程池? 1.单个任务处理的时间比较短 2.将需处理的任务的数量大 使用线程池的好处: 1.减少在创建和销毁线程上所花的时间以及系统资源的开销 2.如不使用线程池,有可能造成系统创建大量线程而导致消耗完系统内存以及"过度切换". 本文详细的给大家介绍了关于Java中四种线程池的使用,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍: FixedThreadPool 由Executors的newFixedThreadPool方法创建.它是一种线程数量固定的线程
-
java并发编程_线程池的使用方法(详解)
一.任务和执行策略之间的隐性耦合 Executor可以将任务的提交和任务的执行策略解耦 只有任务是同类型的且执行时间差别不大,才能发挥最大性能,否则,如将一些耗时长的任务和耗时短的任务放在一个线程池,除非线程池很大,否则会造成死锁等问题 1.线程饥饿死锁 类似于:将两个任务提交给一个单线程池,且两个任务之间相互依赖,一个任务等待另一个任务,则会发生死锁:表现为池不够 定义:某个任务必须等待池中其他任务的运行结果,有可能发生饥饿死锁 2.线程池大小 注意:线程池的大小还受其他的限制,如其他资源池:
-
java线程池ThreadPoolExecutor类使用详解
在<阿里巴巴java开发手册>中指出了线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程,这样一方面是线程的创建更加规范,可以合理控制开辟线程的数量:另一方面线程的细节管理交给线程池处理,优化了资源的开销.而线程池不允许使用Executors去创建,而要通过ThreadPoolExecutor方式,这一方面是由于jdk中Executor框架虽然提供了如newFixedThreadPool().newSingleThreadExecutor().newCachedThreadPool(
-
Java线程池FutureTask实现原理详解
前言 线程池可以并发执行多个任务,有些时候,我们可能想要跟踪任务的执行结果,甚至在一定时间内,如果任务没有执行完成,我们可能还想要取消任务的执行,为了支持这一特性,ThreadPoolExecutor提供了 FutureTask 用于追踪任务的执行和取消.本篇介绍FutureTask的实现原理. 类视图 为了更好的理解FutureTask的实现原理,这里先提供几个重要接口和类的结构,如下图所示: RunnableAdapter ThreadPoolExecutor提供了submit接口用于提交任
-
Java 线程池全面总结与详解
目录 原理 阻塞队列 有界阻塞队列 无界阻塞队列 同步移交队列 实现类分析 使用Executors创建线程池 线程池关闭 线程池是很常用的并发框架,几乎所有需要异步和并发处理任务的程序都可用到线程池. 使用线程池的好处如下: 降低资源消耗:可重复利用已创建的线程池,降低创建和销毁带来的消耗: 提高响应速度:任务到达时,可立即执行,无需等待线程创建: 提高线程的可管理性:线程池可对线程统一分配.调优和监控. 原理 线程池的原理非常简单,这里用处理流程来概括: 线程池判断核心池里的线程是否都在执行任
-
Java设计模式之策略模式示例详解
目录 定义 结构 UML类图 UML序列图 深入理解策略模式 策略和上下文的关系 策略模式在JDK中的应用 该策略接口有四个实现类 策略模式的优点 策略模式的缺点 策略模式的本质 在讲策略模式之前,我们先看一个日常生活中的小例子: 现实生活中我们到商场买东西的时候,卖场往往根据不同的客户制定不同的报价策略,比如针对新客户不打折扣,针对老客户打9折,针对VIP客户打8折... 现在我们要做一个报价管理的模块,简要点就是要针对不同的客户,提供不同的折扣报价. 如果是有你来做,你会怎么做? 我们很有可
-
Qt线程池QThreadPool的使用详解
目录 一.目的 二.最优线程数 三.线程池的原理 四.QThreadPool线程池 五.QThreadPool简单示例 一.目的 现在所有的高性能服务器程序,几乎都会使用到线程池技术,从而更好且有效的榨干服务器性能.而创建并销毁线程的过程势必会消耗内存.而在日常开发中内存资源是及其宝贵的,所以QT 多线程之线程池QThreadPool就有很大用处了.它可以用来管理线程的优先顺序,防止创建过多的线程,起到很好的管理作用. 二.最优线程数 线程的创建和销毁是有性能开销的,当我们有少量业务需要
-
Java结构型设计模式之享元模式示例详解
目录 享元模式 概述 目的 应用场景 优缺点 主要角色 享元模式结构 内部状态和外部状态 享元模式的基本使用 创建抽象享元角色 创建具体享元角色 创建享元工厂 客户端调用 总结 享元模式实现数据库连接池 创建数据库连接池 使用数据库连接池 享元模式 概述 享元模式(Flyweight Pattern)又称为轻量级模式,是对象池的一种实现.属于结构型模式. 类似于线程池,线程池可以避免不停的创建和销毁多个对象,消耗性能.享元模式提供了减少对象数量从而改善应用所需的对象结构的方式. 享元模式尝试重用
-
Java设计模式之享元模式示例详解
目录 定义 原理类图 案例 需求 方案:享元模式 分析 总结 定义 享元模式(FlyWeight Pattern),也叫蝇量模式,运用共享技术,有效的支持大量细粒度的对象,享元模式就是池技术的重要实现方式. 原理类图 Flyweight :抽象的享元角色,他是抽象的产品类,同时他会定义出对象的内部状态和外部状态 ConcreteFlyweight :是具体的享元角色,具体的产品类,实现抽象角色,实现具体的业务逻辑 UnsharedConcreteFlyweight :不可共享的角色,这个角色也可