Pytorch-Geometric中的Message Passing使用及说明
目录
- Pytorch-Geometric中Message Passing使用
- 具体函数说明如下
- GCN 的计算公式如下
- 实际计算工程可以分为下面几步
- 总结
Pytorch-Geometric中Message Passing使用
图中的卷积计算通常被称为邻域聚合或者消息传递 (neighborhood aggregation or message passing).
定义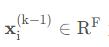 为节点i在第(k−1)层的特征,ej,i表示节点j到节点i的边特征,在GNN中消息传递可以表示为
为节点i在第(k−1)层的特征,ej,i表示节点j到节点i的边特征,在GNN中消息传递可以表示为
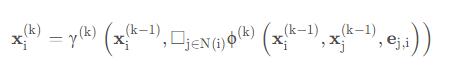
其中 □ 表示具有置换不变性并且可微的函数,例如 sum, mean, max 等, γ 和 ϕ 表示可微函数。
在 PyTorch Gemetric 中,所有卷积算子都是由 MessagePassing 类派生而来,理解 MessagePasing 有助于我们理解 PyG 中消息传递的计算方式和编写自定义的卷积。
在自定义卷积中,用户只需定义消息传递函数 ϕ message(), 节点更新函数 γ update() 以及聚合方式 aggr='add', aggr='mean' 或则 aggr=max.
具体函数说明如下
MessagePassing(aggr='add', flow='source_to_target', node_dim=-2)定义聚合计算的方式 ('add', 'mean'ormax) 以及消息的传递方向 (source_to_targetortarget_to_source). 在 PyG 中,中心节点为目标 target,邻域节点为源 source.node_dim为消息聚合的维度MessagePassing.propagate(edge_index, size=None, **kwargs):该函数接受边信息edge_index和其他额外的数据来执行消息传递并更新节点嵌入MessagePassing.message(...):该函数的作用是计算节点消息,就是公式中的函数 ϕ \phi ϕ . 如果flow='source_to_target',那么消息将由邻域节点 j j j 传向中心节点 i i i ;如果flow='target_to_source',消息则由中心节点 i i i 传向邻域节点 j j j . 传入参数的节点类型可以通过变量名后缀来确定,例如中心节点嵌入变量一般以_i为结尾,邻域节点嵌入变量以x_j为结尾MessagePassing.update(arr_out, ...):该函数为节点嵌入的更新函数 γ \gamma γ , 输入参数为聚合函数MessagePassing.aggregate计算的结果
为了更好的理解 PyG 中 MessagePassing 的计算过程,我们来分析一下源代码。
class MessagePassing(torch.nn.Module):
special_args: Set[str] = {
'edge_index', 'adj_t', 'edge_index_i', 'edge_index_j', 'size',
'size_i', 'size_j', 'ptr', 'index', 'dim_size'
}
def __init__(self, aggr: Optional[str] = "add",
flow: str = "source_to_target", node_dim: int = -2):
super(MessagePassing, self).__init__()
self.aggr = aggr
assert self.aggr in ['add', 'mean', 'max', None]
self.flow = flow
assert self.flow in ['source_to_target', 'target_to_source']
self.node_dim = node_dim
self.inspector = Inspector(self)
self.inspector.inspect(self.message)
self.inspector.inspect(self.aggregate, pop_first=True)
self.inspector.inspect(self.message_and_aggregate, pop_first=True)
self.inspector.inspect(self.update, pop_first=True)
self.__user_args__ = self.inspector.keys(
['message', 'aggregate', 'update']).difference(self.special_args)
self.__fused_user_args__ = self.inspector.keys(
['message_and_aggregate', 'update']).difference(self.special_args)
# Support for "fused" message passing.
self.fuse = self.inspector.implements('message_and_aggregate')
# Support for GNNExplainer.
self.__explain__ = False
self.__edge_mask__ = None
在初始化函数中,MessagePassing 定义了一个 Inspector . Inspector 的中文意思是检查员的意思,这个类的作用就是检查各个函数的输入参数,并保存到 Inspector的参数列表字典中 Inspector.params中。
如果 message的输入参数为 x_i, x_j,那么Inspector.params['message']={'x_i': Parameter, 'x_j': Parameter} (注:这里仅作示意,实际 Inspector.params['message'] 类型为 OrderedDict). Inspector.implements 检查函数是否实现.
MessagePasing 中最核心的是 propgate 函数,假设邻接矩阵 edge_index 的类型为 Torch.LongTensor,消息由 edge_index[0] 传向 edge_index[1] ,代码实现如下
def propagate(self, edge_index: Adj, size: Size = None, **kwargs):
# 为了简化问题,这里不讨论 edge_index 为 SparseTensor 的情况,感兴趣的可阅读 PyG 原始代码
size = self.__check_input__(edge_index, size)
coll_dict = self.__collect__(self.__user_args__, edge_index, size,
kwargs)
msg_kwargs = self.inspector.distribute('message', coll_dict)
out = self.message(**msg_kwargs)
aggr_kwargs = self.inspector.distribute('aggregate', coll_dict)
out = self.aggregate(out, **aggr_kwargs)
update_kwargs = self.inspector.distribute('update', coll_dict)
return self.update(out, **update_kwargs)
在这段代码中,首先是检查节点数量和用户自定义的输入变量,然后依次执行 message, aggregate 和 update 函数。
如果是自定义图卷积,一般会重写 message 和 update,这一点随后再以 GCN 为例解释,这里首先来看一下 aggregate 的实现
def aggregate(self, inputs: Tensor, index: Tensor,
ptr: Optional[Tensor] = None,
dim_size: Optional[int] = None) -> Tensor:
if ptr is not None:
ptr = expand_left(ptr, dim=self.node_dim, dims=inputs.dim())
return segment_csr(inputs, ptr, reduce=self.aggr)
else:
return scatter(inputs, index, dim=self.node_dim, dim_size=dim_size,
reduce=self.aggr)
ptr 变量是针对邻接矩阵 edge_index 为 SparseTensor的情况,此处暂且不论
inputs为 message计算得到的消息, index 就是待更新节点的索引,实际上就是 edge_index_i. 聚合计算通过 scatter 函数实现。scatter 具体实现参考链接
下面以 GCN 为例,我们来看一下 MessagePassing 的计算过程。
GCN 的计算公式如下
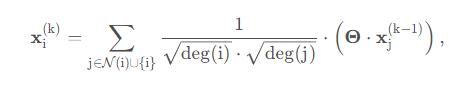
实际计算工程可以分为下面几步
- 1.在邻接矩阵中增加自循环,即把邻接矩阵的对角线上的元素设为1
- 2.对节点特征矩阵做线性变换
- 3.计算节点的归一化系数,也就是节点度乘积的开方
- 4.对节点特征做归一化处理
- 5.聚合(求和)节点特征得到新的节点嵌入
代码如下
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add') # "Add" aggregation (Step 5).
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x)
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
return self.propagate(edge_index, x=x, norm=norm)
def message(self, x_j, norm):
# x_j has shape [E, out_channels]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j
在 forward 函数中,首先是给节点边增加自循环。设输入变量如下
edge_index = torch.tensor([[0, 0, 2], [1, 2, 3]], dtype=torch.long) x = torch.rand((4, 3)) conv = GCNConv(3, 8)
注意到默认消息传递方向为 source_to_target,此时edge_index[0]=x_j 为 source, edge_index[1]=x_i 为 target.
在 GCN 中,第一步是增加节点的自循环,add_self_loops 计算前后变化如下
# before add_self_loops
# edge_index=
tensor([[0, 0, 2],
[1, 2, 3]])
# after add_self_loops
# edge_index=
tensor([[0, 0, 2, 0, 1, 2, 3],
[1, 2, 3, 0, 1, 2, 3]])
# norm=
tensor([0.7071, 0.7071, 0.5000, 1.0000, 0.5000, 0.5000, 0.5000]
此处的 propagate 的输出参数由 edge_index, x, norm , edge_index 是 propagete 必须输入的参数,x, norm 为用户自定义参数。
在 __collect__ 会根据变量名称来收集 message 需要的输入参数。
在 GCN 中,norm 保持不变,x 将被映射到 x_j ,并且经过 __lift__ 函数,其值也会发生变化。__lift__ 函数如下
def __lift__(self, src, edge_index, dim):
if isinstance(edge_index, Tensor):
index = edge_index[dim]
return src.index_select(self.node_dim, index)
在本例中,输入的特征 shape=[4, 8],经过 __lift__ 后,节点特征 shape=[7, 8] . 经过 message 计算后,就可以执行 aggregate 和 update 了。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pytorch .pth权重文件的使用解析
pytorch最后的权重文件是.pth格式的. 经常遇到的问题: 进行finutune时,改配置文件中的学习率,发现程序跑起来后竟然保持了以前的学习率, 并没有使用新的学习率. 原因: 首先查看.pth文件中的内容,我们发现它其实是一个字典格式的文件 其中保存了optimizer和scheduler,所以再次加载此文件时会使用之前的学习率. 我们只需要权重,也就是model部分,将其导出就可以了 import torch original = torch.load('path/to/your/c
-

Python深度学习pyTorch权重衰减与L2范数正则化解析
下面进行一个高维线性实验 假设我们的真实方程是: 假设feature数200,训练样本和测试样本各20个 模拟数据集 num_train,num_test = 10,10 num_features = 200 true_w = torch.ones((num_features,1),dtype=torch.float32) * 0.01 true_b = torch.tensor(0.5) samples = torch.normal(0,1,(num_train+num_test,num_fe
-
Pytorch反向传播中的细节-计算梯度时的默认累加操作
Pytorch反向传播计算梯度默认累加 今天学习pytorch实现简单的线性回归,发现了pytorch的反向传播时计算梯度采用的累加机制, 于是百度来一下,好多博客都说了累加机制,但是好多都没有说明这个累加机制到底会有啥影响, 所以我趁着自己练习的一个例子正好直观的看一下以及如何解决: pytorch实现线性回归 先附上试验代码来感受一下: torch.manual_seed(6) lr = 0.01 # 学习率 result = [] # 创建训练数据 x = torch.rand(20, 1
-
Pytorch-Geometric中的Message Passing使用及说明
目录 Pytorch-Geometric中Message Passing使用 具体函数说明如下 GCN 的计算公式如下 实际计算工程可以分为下面几步 总结 Pytorch-Geometric中Message Passing使用 图中的卷积计算通常被称为邻域聚合或者消息传递 (neighborhood aggregation or message passing). 定义为节点i在第(k−1)层的特征,ej,i表示节点j到节点i的边特征,在GNN中消息传递可以表示为 其中 □ 表示具有置换不变性并
-
关于Pytorch MaxUnpool2d中size操作方式
下图所示为最大值的去池化操作,主要包括三个参数,kernel_size: 卷积核大小(一般为3,即3x3的卷积核), stride:步,还有一个新的size. 从图中可以看出,它将维度4x4的去池化结果变为5x5.主要通过排序的方法,将4x4里面的元素按行展开为(0,0,0,0,0,6,0,8,0,0,0,0,0,14...),然后按照次序放到5x5的矩阵里面. 以上这篇关于Pytorch MaxUnpool2d中size操作方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多
-
pytorch 图像中的数据预处理和批标准化实例
目前数据预处理最常见的方法就是中心化和标准化. 中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征. 标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间 批标准化:BN 在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好.但是对于很深的网路结构,网路的非线性层会使得输出的结
-
可视化pytorch 模型中不同BN层的running mean曲线实例
加载模型字典 逐一判断每一层,如果该层是bn 的 running mean,就取出参数并取平均作为该层的代表 对保存的每个BN层的数值进行曲线可视化 from functools import partial import pickle import torch import matplotlib.pyplot as plt pth_path = 'checkpoint.pth' pickle.load = partial(pickle.load, encoding="latin1")
-
Pytorch 卷积中的 Input Shape用法
先看Pytorch中的卷积 class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) 二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)的计算方式 这里比较奇怪的是这个卷积层居然没有定义input shape,输入尺寸明明是:(N, C_in, H,W),但是定义中却只需
-
解决pytorch 损失函数中输入输出不匹配的问题
一.pytorch 损失函数中输入输出不匹配问题 File "C:\Users\Rain\AppData\Local\Programs\Python\Anaconda.3.5.1\envs\python35\python35\lib\site-packages\torch\nn\modules\module.py", line 491, in __call__ result = self.forward(*input, **kwargs) File "C:\Users\Ra
-
pytorch::Dataloader中的迭代器和生成器应用详解
在使用pytorch训练模型,经常需要加载大量图片数据,因此pytorch提供了好用的数据加载工具Dataloader. 为了实现小批量循环读取大型数据集,在Dataloader类具体实现中,使用了迭代器和生成器. 这一应用场景正是python中迭代器模式的意义所在,因此本文对Dataloader中代码进行解读,可以更好的理解python中迭代器和生成器的概念. 本文的内容主要有: 解释python中的迭代器和生成器概念 解读pytorch中Dataloader代码,如何使用迭代器和生成器实现数
-
Pytorch模型中的parameter与buffer用法
Parameter 和 buffer If you have parameters in your model, which should be saved and restored in the state_dict, but not trained by the optimizer, you should register them as buffers.Buffers won't be returned in model.parameters(), so that the optimize
-
GCN 图神经网络使用详解 可视化 Pytorch
目录 手动尝试GCN图神经网络 现在让我们更详细地看一下底层图 现在让我们更详细地检查edge_index的属性 嵌入 Karate Club Network 训练 Karate Club Network 总结 手动尝试GCN图神经网络 最近,图上的深度学习已经成为深度学习社区中最热门的研究领域之一. 在这里,图神经网络(GNN)旨在将经典的深度学习概念推广到不规则的结构化数据(与图像或文本形成对比),并使神经网络能够推理出对象及其关系. 本内容介绍一些关于通过基于PyTorch几何(PyG)库
-
pytorch 中forward 的用法与解释说明
前言 最近在使用pytorch的时候,模型训练时,不需要使用forward,只要在实例化一个对象中传入对应的参数就可以自动调用 forward 函数 即: forward 的使用 class Module(nn.Module): def __init__(self): super(Module, self).__init__() # ...... def forward(self, x): # ...... return x data = ..... #输入数据 # 实例化一个对象 module