C语言目标文件的详细讲解
目录
- 前言
- 目标文件分类
- 可重定位目标文件
- 分段的优点
- 符号和符号表
- 符号解析
- 重定位
- 可执行目标文件
- 总结
前言
一个 C 语言程序经编译器和汇编器生成可重定位目标文件,再经链接器生成可执行目标文件。那么目标文件中存放的是什么?我们的源代码在经编译以后又是怎么存储的?
文章为 《深入理解计算机系统》的读书笔记,更为详细的内容可以阅读原书。
目标文件分类
目标文件有三种形式:
- 可重定位目标文件
包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并,创建一个可执行目标文件 - 可执行目标文件
包含二进制代码和数据,其形式可以被直接复制到内存并执行 - 共享目标文件
一种特殊可重定位目标文件,可以在加载或运行时被动态地加载进内存并链接
可重定位目标文件
下图为一个典型的 ELF 可重定位目标文件的格式。
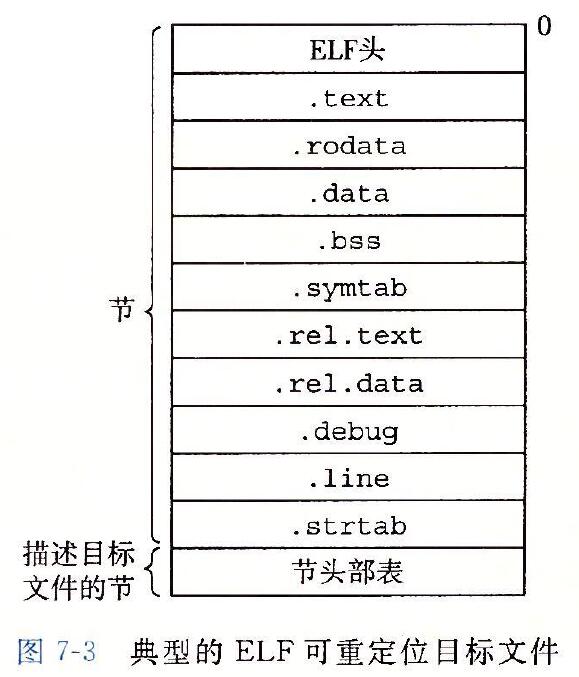
ELF 头以一个 16 字节的序列开始,这个序列包含了:生成该文件的系统的字的大小和字节顺序、目标文件的类型、机器类型、节头部表(也称段表)的文件偏移,以及节头部表中条目的大小和数量等。
节头部表是由描述文件中各个节的条目(entry)组成的数组。节头部表描述了文件中各个节在文件中的偏移位置及节的属性等,从节头部表里面可以得到每个节的所有信息。
- .text:已编译程序的机器代码
- .rodata:只读数据
- 比如 printf 语句中的格式串(%d\n)
- .data:已初始化的全局和静态 C 变量
- 局部 C 变量在运行时被保存在栈中,既不在 .data 节中,也不在 .bss 节中
- .bss:未初始化的全局和静态 C 变量,以及所有被初始化为 0 的全局或静态变量
- 目标文件格式区分已初始化和未初始化变量是为了空间效率:
- 未初始化变量不需要占据任何实际的磁盘空间,因为没有初始化,值没有意义,也就不必表示每个值
- .bss 段只是为未初始化全部变量和局部静态变量预留位置,它并没有内容,也不占据实际的空间,仅仅是个占位符
- .bss 段的大小存放在节头部表中
- 可以使用 readelf -S test 来查看 test 可执行程序节头部表
- 运行时,在内存中分配这些变量,并初始化为 0
- 目标文件格式区分已初始化和未初始化变量是为了空间效率:
- .symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息
- 包含局部静态变量
- 不包含局部非静态变量,这些符号在运行时在栈中被管理,链接器不关心这些
- .rel.text:一个 .text 节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置
- .rel.data:被模块引用或定义的所有全局变量的重定位信息
- .debug:一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的 C 源文件
- 只有在编译时加入 -g 选项才会得到这张表
- .line:原始 C 源程序中的行号和 .text 节中机器指令之间的映射
- 只有在编译时加入 -g 选项才会得到这张表
- .strtab:一个字符串表,其中包含 .symtab 和 .debug 节中的符号表,以及节头部中的节名字
- 字符串表就是以 NULL 结尾的字符串序列
分段的优点
为什么要这么麻烦,把程序的指令和数据分开存放?
- 程序被装载进内存后,数据和指令分别被映射到两个虚拟区域
- 由于数据是可读写的,指令是只读的,权限可以分别设置成可读写和只读
- 可以防止程序指令被改写
- 对现代 CPU 而言缓存是极其重要的
- 数据区和指令区分离有利于提高程序的局部性,从而提高缓存命中率
- 启动多个相同进程时
- 可以共享一份指令,节省内存
符号和符号表
每个可重定位目标模块 m 都有一个符号表,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
- 由模块 m 定义并能被其他模块引用的全局符号
- 全局链接器符号对应于非静态的 C 函数和全局变量
- 由其他模块定义并被模块 m 引用的全局符号
- 这些符号称为外部符号,对应于在其他模块中定义的非静态 C 函数和全局变量
- 只被模块 m 定义和引用的符号
- 它们对应于带 static 属性的 C 函数和全局变量,这些符号在模块 m 中任何位置都可见,但是不能被其他模块引用
符号表是由汇编器用编译器输出到汇编语言 .s 文件中的符号构造的。.symtab 节中包含 ELF 符号表,这张符号表包含一个条目的数组。下面是 ELF 符号表条目格式:
typedef struct {
int name; // String table offset
char type:4, // Function or data (4 bits)
binding:4;// Local or global (4 bits)
char reserved; // Unused
short section; // Section header index
long value; // Section offset or absolute address
long size; // Object size in bytes
} Elf64_Symbol;
name 是字符串表中的字节偏移,指向符号的字符串名字。value 是符号的位置。对于可重定位目标文件,value 是距定义目标的起始位置的偏移。对于可执行目标文件,该值是一个绝对运行时地址。size 是目标的大小(以字节为单位)。
每个符号都被分配到目标文件的某个节,由 section 字段表示,该字段是一个到节头部表的索引。有三个特殊的的伪节,它们在节头部表中是没有条目的:
- ABS:代表不该被重定位的符号
- UNDEF:代表未定义的符号,也就是在本目标模块中引用,但定义在其他地方的符号
- COMMON:表示还未被分配位置的未初始化的数据目标
- 对于该类型符号,value 字段给出对齐要求,size 给出最小的大小
只有可重定位目标文件中才有伪节,可执行目标文件中是没有的。
GCC 将可重定位目标文件中的符号分配到 COMMON 和 .bss 的规则:
- COMMON:未初始化的全局变量
- .bss:未初始化的静态变量,以及初始化为 0 的全局或静态变量
符号解析
对于局部符号的解析是非常简单的,因为编译器只允许每个模块中每个局部符号有一个定义。不过,对全局符号的引用解析就麻烦的多。当编译器遇到一个不是在当前模块中定义的符号(变量或函数名)时,会假设该符号是在其他某个模块中定义的,生成一个链接器符号表条目,并把它交给链接器处理。
如果多个模块定义同名的全局符号,会发生什么呢?下面是 Linux 编译系统采用的方法。
在编译时,编译器向汇编器输出每个全局符号,或者是强或者是弱,汇编器把这个信息编码在可重定位目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Linux 链接器使用如下规则来处理多重定义的符号名:
- 不允许有多个同名强符号
- 如果有一个强符号和多个弱符号同名,选择强符号
- 如果有多个弱符号同名,从弱符号中任意选择一个
重定位
当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置位置的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。代码的重定位条目放在 .rel.text 中,已初始化数据的重定位条目放在 .rel.data 中。
下图为 ELF 重定位条目的格式:

符号解析完成后,代码中的每个符号引用和正好一个符号定义关联起来。此时,就可以开始重定位了。在重定位中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
- 重定位节和符号定义
- 链接器将所有相同类型的节合并为同一类型的新的聚合节
- 链接器将运行时内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号
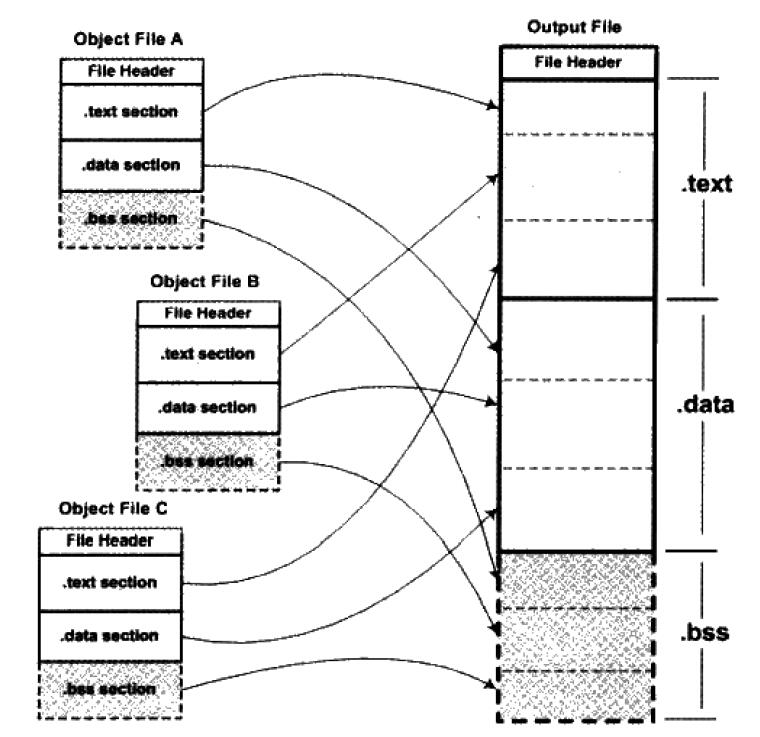
- 重定位节中的符号引用
- 链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址
可执行目标文件
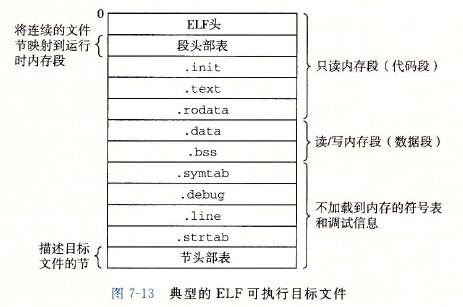
下图为一个典型的 ELF 可执行文件:
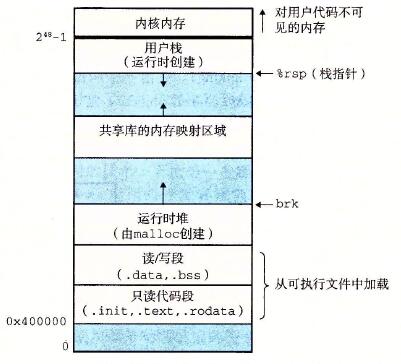
可执行文件加载到内存:
总结
到此这篇关于C语言目标文件的文章就介绍到这了,更多相关C语言目标文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言目标文件的详细讲解
目录 前言 目标文件分类 可重定位目标文件 分段的优点 符号和符号表 符号解析 重定位 可执行目标文件 总结 前言 一个 C 语言程序经编译器和汇编器生成可重定位目标文件,再经链接器生成可执行目标文件.那么目标文件中存放的是什么?我们的源代码在经编译以后又是怎么存储的? 文章为 <深入理解计算机系统>的读书笔记,更为详细的内容可以阅读原书. 目标文件分类 目标文件有三种形式: 可重定位目标文件包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并,创建一个可执行目标文件 可执行目标
-

C语言结构体超详细讲解
目录 前言 1.结构体的声明 1.1 结构的基础知识 1.2 结构的声明 1.3 结构成员的类型 1.4 结构体变量的定义和初始化 2.结构体成员的访问 2.1 点操作符访问 2.2 ->操作符访问 3.结构体传参 3.1 参数是结构体类型的变量 3.2 参数是结构体类型的变量的地址 3.3 结构体传参对比 总结 前言 本文开始学习结构体的知识点,主要内容包括: 结构体类型的声明 结构体初始化 结构体成员访问 结构体传参 1.结构体的声明 1.1 结构的基础知识 结构是一些值的集合,这些值称为成
-
C语言数组快速入门详细讲解
目录 1.一维数组 a.一维数组的创建 b.一维数组的初始化 c.一维数组的使用 d.一维数组在内存中的存储 2.二维数组 a.二维数组的创建 b.二维数组的初始化 c.二维数组的使用 d.二维数组在内存中的存储 3.数组越界 4.数组作为函数参数 5.数组名 1.一维数组 数组的定义: 数组是一组相同类型元素的集合 a.一维数组的创建 数组的创建格式为: 数组的类型 数组名[ 常量表达式] : 关于数组创建易错点: b.一维数组的初始化 类似于给整型变量初始化的过程: int a=2; int
-
C语言 if else 语句详细讲解
前面我们看到的代码都是顺序执行的,也就是先执行第一条语句,然后是第二条.第三条--一直到最后一条语句. 但是对于很多情况,顺序结构的代码是远远不够的,比如一个程序限制了只能成年人使用,儿童因为年龄不够,没有权限使用.这时候程序就需要做出判断,看用户是否是成年人,并给出提示. if-else语句 在C语言中,使用if和else关键字进行判断.请先看下面的代码: #include <stdio.h> int main() { int age; printf("请输入你的年龄:"
-
C语言 struct结构体超详细讲解
目录 一.本章重点 二.创建结构体 三.typedef与结构体的渊源 四.匿名结构体 五.结构体大小 六.结构体指针 七.其他 一.本章重点 创建结构体 typedef与结构体的渊源 匿名结构体 结构体大小 结构体指针 其他 二.创建结构体 先来个简单的结构体创建 这就是一个比较标准的结构体 struct people { int age; int id; char address[10]; char sex[5]; };//不要少了分号. 需要注意的是不要少了分号. 那么这样创建结构体呢? s
-
C语言超详细讲解文件的操作
目录 一.为什么使用文件 二.什么是文件 1.程序文件 2.数据文件 3.文件名 三.文件指针 四.文件的打开和关闭 五.文件的顺序读写 六.文件的随机读写 fseek ftell rewind 七.文件结束判定 一.为什么使用文件 当我们写一些项目的时候,我们应该要把写的数据存储起来.只有我们自己选择删除数据的时候,数据才不复存在.这就涉及到了数据的持久化的问题,为我们一般数据持久化的方法有,把数据存在磁盘文件.存放到数据库等方式.使用文件我们可以将数据直接存放在电脑的硬盘上,做到了数据的持久
-
c语言压缩文件详细讲解
目录 c语言压缩文件 一.单文件压缩 二.多文件压缩 三.多文件异步压缩 四.压缩文件夹 c语言压缩文件 话说当今压缩市场三足鼎立,能叫上名号的有zip.rar.7z.其中zip是压缩界的鼻祖,在各大平台上的流行度最广,rar是商业软件,压缩率和效率都是很高的,对个人用户没有限制.7z是开源的,属于后起之秀,也有着不凡的压缩率,但在内存占有率的问题上,稍逊风骚.今天,主要总结下,windows平台下,zip的压缩与解压的方法,用ICSharpCode组件. 一.单文件压缩 场景,文件可能比较大,
-
C语言数组超详细讲解下篇扫雷
目录 前言 1.扫雷是什么? 2.程序框架 2.1 主函数 2.2 函数menu 2.3 函数game 2.3.1 函数init_board 2.3.2 函数show_board 2.3.3 函数set_mine 2.3.4 函数find_mine 2.3.5 函数get_mine_count 3.头文件.h 4.游戏试玩 总结 前言 本文接着复习前面所学知识,以扫雷游戏为例. 1.扫雷是什么? 百度百科:<扫雷>是一款大众类的益智小游戏,于1992年发行.游戏目标是在最短的时间内根据点击格子
-
C语言详细讲解strcpy strcat strcmp函数的模拟实现
目录 一.模拟实现strcpy函数 二.模拟实现strcat函数 三.模拟实现strcmp函数 四.小结 一.模拟实现strcpy函数 strcpy函数是字符串拷贝函数,就是将源字符串拷贝到目标空间中. char * strcpy ( char * destination, const char * source );//库函数中的声明 将源(source)指向的c字符串复制到目标(destination)指向的数组中,包括终止的空字符(并在该点停止). 为避免溢出,目标(destination
-
C语言超详细讲解字符串函数和内存函数
目录 字符串函数 长度不受限制的字符串函数 strlen strcpy strcat strcmp 长度受限制的字符串函数介绍 strncpy strncat strncmp 字符串查找以及错误报告 strstr strtok strerror 内存操作函数 memcpy memmove memcmp 字符串函数 长度不受限制的字符串函数 strlen size_t strlen ( const char * str ) 求字符串长度: 字符串以'\0' 作为结束标志,strlen函数返回的是在