如何计算 tensorflow 和 pytorch 模型的浮点运算数
目录
- 1. 引言
- 2. 模型结构
- 3. 计算模型的 FLOPs
- 3.1. tensorflow 1.12.0
- 3.2. tensorflow 2.3.1
- 3.3. pytorch 1.10.1+cu102
- 3.4. 结果对比
- 4. 总结
本文主要讨论如何计算 tensorflow 和 pytorch 模型的 FLOPs。如有表述不当之处欢迎批评指正。欢迎任何形式的转载,但请务必注明出处。
1. 引言
FLOPs 是 floating point operations 的缩写,指浮点运算数,可以用来衡量模型/算法的计算复杂度。本文主要讨论如何在 tensorflow 1.x, tensorflow 2.x 以及 pytorch 中利用相关工具计算对应模型的 FLOPs。
2. 模型结构
为了说明方便,先搭建一个简单的神经网络模型,其模型结构以及主要参数如表1 所示。
表 1 模型结构及主要参数
| Layers | channels | Kernels | Strides | Units | Activation |
|---|---|---|---|---|---|
| Conv2D | 32 | (4,4) | (1,2) | \ | relu |
| GRU | \ | \ | \ | 96 | \ |
| Dense | \ | \ | \ | 256 | sigmoid |
用 tensorflow(实际使用 tensorflow 中的 keras 模块)实现该模型的代码为:
from tensorflow.keras.layers import *
from tensorflow.keras.models import load_model, Model
def test_model_tf(Input_shape):
# shape: [B, C, T, F]
main_input = Input(batch_shape=Input_shape, name='main_inputs')
conv = Conv2D(32, kernel_size=(4, 4), strides=(1, 2), activation='relu', data_format='channels_first', name='conv')(main_input)
# shape: [B, T, FC]
gru = Reshape((conv.shape[2], conv.shape[1] * conv.shape[3]))(conv)
gru = GRU(units=96, reset_after=True, return_sequences=True, name='gru')(gru)
output = Dense(256, activation='sigmoid', name='output')(gru)
model = Model(inputs=[main_input], outputs=[output])
return model
用 pytorch 实现该模型的代码为:
import torch
import torch.nn as nn
class test_model_torch(nn.Module):
def __init__(self):
super(test_model_torch, self).__init__()
self.conv2d = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(4,4), stride=(1,2))
self.relu = nn.ReLU()
self.gru = nn.GRU(input_size=4064, hidden_size=96)
self.fc = nn.Linear(96, 256)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
# shape: [B, C, T, F]
out = self.conv2d(inputs)
out = self.relu(out)
# shape: [B, T, FC]
batch, channel, frame, freq = out.size()
out = torch.reshape(out, (batch, frame, freq*channel))
out, _ = self.gru(out)
out = self.fc(out)
out = self.sigmoid(out)
return out
3. 计算模型的 FLOPs
本节讨论的版本具体为:tensorflow 1.12.0, tensorflow 2.3.1 以及 pytorch 1.10.1+cu102。
3.1. tensorflow 1.12.0
在 tensorflow 1.12.0 环境中,可以使用以下代码计算模型的 FLOPs:
import tensorflow as tf
import tensorflow.keras.backend as K
def get_flops(model):
run_meta = tf.RunMetadata()
opts = tf.profiler.ProfileOptionBuilder.float_operation()
flops = tf.profiler.profile(graph=K.get_session().graph,
run_meta=run_meta, cmd='op', options=opts)
return flops.total_float_ops
if __name__ == "__main__":
x = K.random_normal(shape=(1, 1, 100, 256))
model = test_model_tf(x.shape)
print('FLOPs of tensorflow 1.12.0:', get_flops(model))
3.2. tensorflow 2.3.1
在 tensorflow 2.3.1 环境中,可以使用以下代码计算模型的 FLOPs :
import tensorflow.compat.v1 as tf
import tensorflow.compat.v1.keras.backend as K
tf.disable_eager_execution()
def get_flops(model):
run_meta = tf.RunMetadata()
opts = tf.profiler.ProfileOptionBuilder.float_operation()
flops = tf.profiler.profile(graph=K.get_session().graph,
run_meta=run_meta, cmd='op', options=opts)
return flops.total_float_ops
if __name__ == "__main__":
x = K.random_normal(shape=(1, 1, 100, 256))
model = test_model_tf(x.shape)
print('FLOPs of tensorflow 2.3.1:', get_flops(model))
3.3. pytorch 1.10.1+cu102
在 pytorch 1.10.1+cu102 环境中,可以使用以下代码计算模型的 FLOPs(需要安装 thop):
import thop
x = torch.randn(1, 1, 100, 256)
model = test_model_torch()
flops, _ = thop.profile(model, inputs=(x,))
print('FLOPs of pytorch 1.10.1:', flops * 2)
需要注意的是,thop 返回的是 MACs (Multiply–Accumulate Operations),其等于 2 2 2 倍的 FLOPs,所以上述代码有乘 2 2 2 操作。
3.4. 结果对比
三者计算出的 FLOPs 分别为:
tensorflow 1.12.0:

tensorflow 2.3.1:

pytorch 1.10.1:
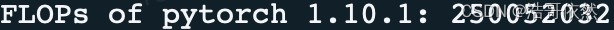
可以看到 tensorflow 1.12.0 和 tensorflow 2.3.1 的结果基本在同一个量级,而与 pytorch 1.10.1 计算出来的相差甚远。但如果将上述模型结构改为只包含第一层 Conv2D,三者计算出来的 FLOPs 却又是一致的。所以推断差异主要来自于 GRU 的 FLOPs。如读者知道其中详情,还请不吝赐教。
4. 总结
本文给出了在 tensorflow 1.x, tensorflow 2.x 以及 pytorch 中利用相关工具计算模型 FLOPs 的方法,但从本文所使用的测试模型来看, tensorflow 与 pytorch 统计出的结果相差甚远。当然,也可以根据网络层的类型及其对应的参数,推导计算出每个网络层所需的 FLOPs。
到此这篇关于计算 tensorflow 和 pytorch 模型的浮点运算数的文章就介绍到这了,更多相关tensorflow 和 pytorch浮点运算数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch使用-tensor的基本操作解读
目录 一.tensor加减乘除 二.tensor矩阵运算 四.tensor切片操作 五.tensor改变形状 六.tensor 和 numpy.array相互转换 七.tensor 转到GPU上 总结 一.tensor加减乘除 加法操作 import torch x = torch.randn(2, 3) y = torch.randn(2, 3) z = x + y print(z) z = torch.add(x, y) print(z) y.add_(x) print(y) 其他操作类似:
-

Python tensorflow与pytorch的浮点运算数如何计算
目录 1. 引言 2. 模型结构 3. 计算模型的 FLOPs 3.1. tensorflow 1.12.0 3.2. tensorflow 2.3.1 3.3. pytorch 1.10.1+cu102 3.4. 结果对比 4. 总结 1. 引言 FLOPs 是 floating point operations 的缩写,指浮点运算数,可以用来衡量模型/算法的计算复杂度.本文主要讨论如何在 tensorflow 1.x, tensorflow 2.x 以及 pytorch 中利用相关工具计算对
-
Pytorch实现List Tensor转Tensor,reshape拼接等操作
目录 一.List Tensor转Tensor (torch.cat) 高维tensor 二.List Tensor转Tensor (torch.stack) 持续更新一些常用的Tensor操作,比如List,Numpy,Tensor之间的转换,Tensor的拼接,维度的变换等操作. 其它Tensor操作如 einsum等见:待更新. 用到两个函数: torch.cat torch.stack 一.List Tensor转Tensor (torch.cat) // An highlighted
-
Pytorch如何把Tensor转化成图像可视化
目录 Pytorch把Tensor转化成图像可视化 pytorch标准化的Tensor转图像问题 总结 Pytorch把Tensor转化成图像可视化 在调试程序的时候经常想把tensor可视化成来看看,可以这样操作: from torchvision import transforms unloader = transforms.ToPILImage() image = original_tensor.cpu().clone() # clone the tensor image = image
-
Pytorch四维Tensor转图片并保存方式(维度顺序调整)
目录 Pytorch四维Tensor转图片并保存 1.维度顺序转换 2.转为numpy数组 3.根据第一维度batch_size逐个读取中间结果,并存储到磁盘中 Pytorch中Tensor介绍 torch.Tensor或torch.tensor注意事项 创建tensor的四种主要方法 总结 Pytorch四维Tensor转图片并保存 最近在复现一篇论文代码的过程中,想要输出中间图片的结果图,通过debug发现在pytorch网络中是用Tensor存储的四维张量. 1.维度顺序转换 第一维代表的
-
Pytorch 和 Tensorflow v1 兼容的环境搭建方法
Github 上很多大牛的代码都是Tensorflow v1 写的,比较新的文章则喜欢用Pytorch,这导致我们复现实验或者对比实验的时候需要花费大量的时间在搭建不同的环境上.这篇文章是我经过反复实践总结出来的环境配置教程,亲测有效! 首先最基本的Python 环境配置如下: conda create -n py37 python=3.7 python版本不要设置得太高也不要太低,3.6~3.7最佳,适用绝大部分代码库.(Tensorflow v1 最高支持的python 版本也只有3.7)
-
如何计算 tensorflow 和 pytorch 模型的浮点运算数
目录 1. 引言 2. 模型结构 3. 计算模型的 FLOPs 3.1. tensorflow 1.12.0 3.2. tensorflow 2.3.1 3.3. pytorch 1.10.1+cu102 3.4. 结果对比 4. 总结 本文主要讨论如何计算 tensorflow 和 pytorch 模型的 FLOPs.如有表述不当之处欢迎批评指正.欢迎任何形式的转载,但请务必注明出处. 1. 引言 FLOPs 是 floating point operations 的缩写,指浮点运算数,可以用
-
pytorch_pretrained_bert如何将tensorflow模型转化为pytorch模型
pytorch_pretrained_bert将tensorflow模型转化为pytorch模型 BERT仓库里的模型是TensorFlow版本的,需要进行相应的转换才能在pytorch中使用 在Google BERT仓库里下载需要的模型,这里使用的是中文预训练模型(chinese_L-12_H-768_A_12) 下载chinese_L-12_H-768_A-12.zip后解压,里面有5个文件 chinese_L-12_H-768_A-12.zip后解压,里面有5个文件 bert_config
-
Pytorch模型转onnx模型实例
如下所示: import io import torch import torch.onnx from models.C3AEModel import PlainC3AENetCBAM device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def test(): model = PlainC3AENetCBAM() pthfile = r'/home/joy/Projects/
-
关于windows下Tensorflow和pytorch安装教程
一.Tensorflow安装 1.Tensorflow介绍 Tensorflow是广泛使用的实现机器学习以及其它涉及大量数学运算的算法库之一.Tensorflow由Google开发,是GitHub上最受欢迎的机器学习库之一.Google几乎在所有应用程序中都使用Tensorflow来实现机器学习. 例如,如果您使用到了Google照片或Google语音搜索,那么您就间接使用了Tensorflow模型.它们在大型Google硬件集群上工作,在感知任务方面功能强大. 2.Tensorflow安装(c
-
解决pytorch 模型复制的一些问题
直接使用 model2=model1 会出现当更新model2时,model1的权重也会更新,这和自己的初始目的不同. 经评论指出可以使用: model2=copy.deepcopy(model1) 来实现深拷贝,手上没有pytorch环境,具体还没测试过,谁测试过可以和我说下有没有用. 原方法: 所有要使用模型复制可以使用如下方法. torch.save(model, "net_params.pkl") model5=Cnn(3,10) model5=torch.load('net_
-
pytorch 模型可视化的例子
如下所示: 一. visualize.py from graphviz import Digraph import torch from torch.autograd import Variable def make_dot(var, params=None): """ Produces Graphviz representation of PyTorch autograd graph Blue nodes are the Variables that require gra
-
画pytorch模型图,以及参数计算的方法
刚入pytorch的坑,代码还没看太懂.之前用keras用习惯了,第一次使用pytorch还有些不适应,希望广大老司机多多指教. 首先说说,我们如何可视化模型.在keras中就一句话,keras.summary(),或者plot_model(),就可以把模型展现的淋漓尽致. 但是pytorch中好像没有这样一个api让我们直观的看到模型的样子.但是有网友提供了一段代码,可以把模型画出来,对我来说简直就是如有神助啊. 话不多说,上代码吧. import torch from torch.autog
-
将Pytorch模型从CPU转换成GPU的实现方法
最近将Pytorch程序迁移到GPU上去的一些工作和思考 环境:Ubuntu 16.04.3 Python版本:3.5.2 Pytorch版本:0.4.0 0. 序言 大家知道,在深度学习中使用GPU来对模型进行训练是可以通过并行化其计算来提高运行效率,这里就不多谈了. 最近申请到了实验室的服务器来跑程序,成功将我简陋的程序改成了"高大上"GPU版本. 看到网上总体来说少了很多介绍,这里决定将我的一些思考和工作记录下来. 1. 如何进行迁移 由于我使用的是Pytorch写的模型,网上给
-
将tensorflow的ckpt模型存储为npy的实例
实例如下所示: #coding=gbk import numpy as np import tensorflow as tf from tensorflow.python import pywrap_tensorflow checkpoint_path='model.ckpt-5000'#your ckpt path reader=pywrap_tensorflow.NewCheckpointReader(checkpoint_path) var_to_shape_map=reader.get_