Mysql主从三种复制模式(异步复制,半同步复制,组复制)
目录
- MySQL异步复制
- 半同步复制
- 组复制
- MGR的解决方案现在具备的特性
- MGR的解决方案目前的影响
MySQL异步复制
MySQL异步复制是主从复制过程中默认的复制模式。主从复制涉及三个线程,master I/O线程、slave I/O线程、slave sql线程。因为是异步复制,所以master事务的提交,不需要经过slave的确认,即master I/O线程提交事务后,不需要等待slave I/O线程的回复确认,master并不保证binlog一定写入到了relay log中;而slave I/O把binlog写入relay log后,由slave sql线程异步执行应用到slave mysql中,slave I/O也不需要slave sql的回复确认,并不保证relay log日志完整写入到了mysql中。

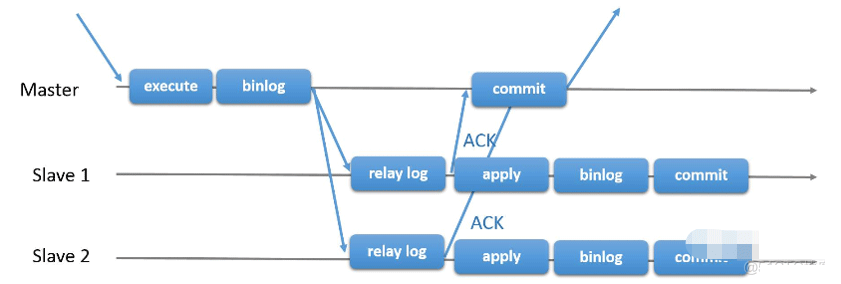
半同步复制
基于传统异步存在的缺陷,mysql在5.5版本推出半同步复制,是对传统异步复制的改进。在master事务commit前,必须确保binlog日志已经写入slave 的relay log日志中,收到slave给master的响应后,才能进行事务的commit。但是后半部分的relay log到sql线程仍然属于异步执行。
组复制
基于传统异步复制和半同步复制的缺陷——数据的一致性问题无法保证,MySQL官方在5.7.17版本正式推出组复制(MySQL Group Replication,简称MGR)。
由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点(N / 2 + 1)决议并通过,才能得以提交。如上图所示,由3个节点组成一个复制组,Consensus层为一致性协议层,在事务提交过程中,发生组间通讯,由2个节点决议(certify)通过这个事务,事务才能够最终得以提交并响应。
引入组复制,主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。组复制依靠分布式一致性协议(Paxos协议的变体),实现了分布式下数据的最终一致性,提供了真正的数据高可用方案(是否真正高可用还有待商榷)。其提供的多写方案,给我们实现多活方案带来了希望。
MGR环境下,服务器数量必须是3台以上,并且是单数,实现2/n+1的算法。
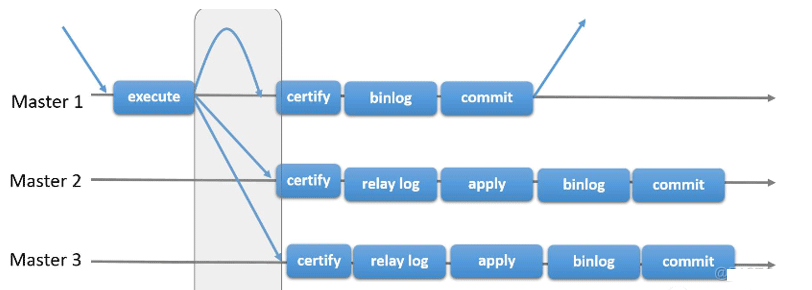
一个复制组由若干个节点(数据库实例)组成,组内各个节点维护各自的数据副本(Share Nothing),通过一致性协议实现原子消息和全局有序消息,来实现组内实例数据的一致。
MGR的解决方案现在具备的特性
数据一致性保障:确保集群中大部分节点收到日志
多节点写入支持:多写模式下支持集群中的所有节点都可以写入(但是考虑1到高并发场景下,保证数据高度一致性,生产并没有选择多主写入,使用单主集群)
Fault Tolerance: 确保系统发生故障(包括脑裂)依然可用,双写对系统无影响
MGR的解决方案目前的影响
- 仅支持InnoDB表,并且每张表一定要有一个主键,用于做write set的冲突检测;
- 必须打开GTID特性,二进制日志格式必须设置为ROW,用于选主与write set
- COMMIT可能会导致失败,类似于快照事务隔离级别的失败场景
- 目前一个MGR集群最多支持9个节点
- 不支持外键于save point特性,无法做全局间的约束检测与部分部分回滚
- 二进制日志不支持binlog event checksum
到此这篇关于Mysql主从三种复制模式(异步复制,半同步复制,组复制)的文章就介绍到这了,更多相关Mysql主从复制内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解MySQL的半同步
前言 年后在进行腾讯二面的时候,写完算法的后问的第一个问题就是,MySQL的半同步是什么?我当时直接懵了,我以为是问的MySQL的两阶段提交的问题呢?结果确认了一下后不是两阶段提交,然后面试官看我连问的是啥都不知道,就直接跳过这个问题,直接聊下一个问题了.所以这次总结一下这部分的知识内容,文字内容比较多,可能会有些枯燥,但对于这方面感兴趣的人来说还是比较有意思的. MySQL的主从复制 我们的一般在大规模的项目上,都是使用MySQL的复制功能来创建MySQL的主从集群的.主要是可以通过为服务器配
-
浅谈MySQL8.0 异步复制的三种方式
本实验中分别针对空库.脱机.联机三种方式,配置一主两从的mysql标准异步复制.只做整服务器级别的复制,不考虑对个别库表或使用过滤复制的情况. 实验环境 [root@slave2 ~]# cat /etc/hosts 192.168.2.138 master 192.168.2.192 slave1 192.168.2.130 slave2 mysql> select version(); +-----------+ | version() | +-----------+ | 8.0.16 |
-
简述mysql监控组复制
原文:https://dev.mysql.com/doc/refman/8.0/en/group-replication-monitoring.html 译者:kun 最近在翻译MySQL8.0官方文档 本文是第18.3"监控组复制"部分. 1.监控组复制 假设MySQL已经在启用了性能模式的情况下编译,使用Perfomance Schema表监控组复制.组复制添加以下表: performance_schema.replication_group_member_stats perfor
-
MYSQL 完全备份、主从复制、级联复制、半同步小结
mysql 完全备份 1,启用二进制日志,并于数据库分离,单独存放 vim /etc/my.cnf 添加 log_bin=/data/bin/mysql-bin 创建/data/bin文件夹并授权 chown mysql.mysql /data/bin 2,完成备份数据库 mysqldump -A --single-transaction --master-data=2 | xz > /data/all.sql.xz 3,对数据库进行增删改 INSERT hellodb.students(stu
-
scrapy数据存储在mysql数据库的两种方式(同步和异步)
方法一:同步操作 1.pipelines.py文件(处理数据的python文件) import pymysql class LvyouPipeline(object): def __init__(self): # connection database self.connect = pymysql.connect(host='XXX', user='root', passwd='XXX', db='scrapy_test') # 后面三个依次是数据库连接名.数据库密码.数据库名称 # get c
-
Mysql主从三种复制模式(异步复制,半同步复制,组复制)
目录 MySQL异步复制 半同步复制 组复制 MGR的解决方案现在具备的特性 MGR的解决方案目前的影响 MySQL异步复制 MySQL异步复制是主从复制过程中默认的复制模式.主从复制涉及三个线程,master I/O线程.slave I/O线程.slave sql线程.因为是异步复制,所以master事务的提交,不需要经过slave的确认,即master I/O线程提交事务后,不需要等待slave I/O线程的回复确认,master并不保证binlog一定写入到了relay log中:而sla
-
SQL Server数据库的三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式
如何图形界面下修改恢复模式 找到你想修改的数据库 右键 > 属性 > 左侧 选项既可看到 1.Simple 简单恢复模式, Simple模式的旧称叫"Checkpoint with truncate log",其实这个名字更形象,在Simple模式下,SQL Server会在每次checkpoint或backup之后自动截断log,也就是丢弃所有的inactive log records,仅保留用于实例启动时自动发生的instance recovery所需的少量log,这
-
浅谈Tomcat三种运行模式
tomcat的运行模式有3种 一.bio(blocking I/O) 即阻塞式I/O操作,表示Tomcat使用的是传统的Java I/O操作(即java.io包及其子包).是基于JAVA的HTTP/1.1连接器,Tomcat7以下版本在默认情况下是以bio模式运行的.一般而言,bio模式是三种运行模式中性能最低的一种.我们可以通过Tomcat Manager来查看服务器的当前状态.(Tomcat7 或以下,在 Linux 系统中默认使用这种方式) 二.nio(new I/O) 是Java SE
-
分享ajax的三种解析模式
一.Ajax中的JSON格式 html代码: <html> <body> <input type="button" value="Ajax" id="btn"> <script> var btn = document.getElementById("btn"); btn.onclick = function(){ var xhr = getXhr(); xhr.open(&quo
-
Oracle数据库 DGbroker三种保护模式的切换
1.三种保护模式 – Maximum protection 在Maximum protection下, 可以保证从库和主库数据完全一样,做到zero data loss.事务同时在主从两边提交完成,才算事务完成.如果从库宕机或者网络出现问题,主从库不能通讯,主库也立即宕机.在这种方式下,具有最高的保护等级.但是这种模式对主库性能影响很大,要求高速的网络连接. – Maximum availability 在Maximum availability模式下,如果和从库的连接正常,运行方式等同Maxi
-
深入理解java三种工厂模式
适用场合: 7.3 工厂模式的适用场合 创建新对象最简单的办法是使用new关键字和具体类.只有在某些场合下,创建和维护对象工厂所带来的额外复杂性才是物有所值.本节概括了这些场合. 7.3.1 动态实现 如果需要像前面自行车的例子一样,创建一些用不同方式实现同一接口的对象,那么可以使用一个工厂方法或简单工厂对象来简化选择实现的过程.这种选择可以是明确进行的也可以是隐含的.前者如自行车那个例子,顾客可以选择需要的自行车型号:而下一节所讲的XHR工厂那个例子则属于后者,该例中所返回的连接对象的类型取决
-
[Oracle] Data Guard 之 三种保护模式介绍
Data Guard提供如下三种数据保护模式: 1)最高保护模式(Maximum Protection)这里的"最大保护"是指最大限度的保护数据不丢失,也就是至少有一个standby和primary保持实时同步,但这样做的代价很大,即当一个事务提交时,不但要写到primary段的online redo log,还有写到至少一个standby的standby redo log.这样会有一个严重的问题,就是当standby出现故障或网络故障,导致日志无法同步时,primary数据库会被sh
-
python 开发的三种运行模式详细介绍
Python 三种运行模式 Python作为一门脚本语言,使用的范围很广.有的同学用来算法开发,有的用来验证逻辑,还有的作为胶水语言,用它来粘合整个系统的流程.不管怎么说,怎么使用python既取决于你自己的业务场景,也取决于你自己的python应用能力.就我个人而言,我觉得python作为既可以用来进行业务的开发,也可以进行产品原型的开发.一般来说,python的运行主要下面这三种模式. 1.单循环模式 单循环模式使用的最多,也最简单,当然也最稳定.为什么呢,因为单循环本来代码就写的很少,出错
-
详解Java 中的三种代理模式
代理模式 代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式;即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能. 这里使用到编程中的一个思想:不要随意去修改别人已经写好的代码或者方法,如果需改修改,可以通过代理的方式来扩展该方法. 举个例子来说明代理的作用:假设我们想邀请一位明星,那么并不是直接连接明星,而是联系明星的经纪人,来达到同样的目的.明星就是一个目标对象,他只要负责活动中的节目,而其他琐碎的事情就交给他的代理
-
Java的三种代理模式简述
目录 一.代理模式是什么 二.Java的三种代理模式 1.静态代理 2.动态代理(也叫JDK代理) 3.Cglib代理 一.代理模式是什么 代理模式是一种设计模式,简单说即是在不改变源码的情况下,实现对目标对象的功能扩展. 比如有个歌手对象叫Singer,这个对象有一个唱歌方法叫sing(). 1 public class Singer{ 2 public void sing(){ 3 System.out.println("唱一首歌"); 4 } 5 } 假如你希望,通过你的某种方式