Python 读取 Word 文档操作
目录
- 前言
- Python 读取 Word 文档
- 安装 python-docx库
前言
Word 文档 (.docx) 是另一种主要用于存储文本的常见文档。它们通常由 Microsoft Office 创建和编辑,但也可以使用其他工具生成兼容文件。它们通常是共享可编辑文件的最常见格式,同时在分发文档时也非常常见。
Python 读取 Word 文档
安装 python-docx库
在本节中,我们将学习如何使用 Python 从 Word 文档中提取文本信息。我们主要使用 python-docx 库来读取和处理 Word 文档,其安装方法与其它第三方库完全相同:
$ pip install python-docx
首先,导入 python-docx 库:
>>> import docx
打开 document_1.docx 文件:
>>> doc = docx.Document('document_1.docx')
检查存储在 core_properties 中的元数据属性,需要访问 core_properties 属性。这些属性是为 Word 定义的文档元数据属性,例如作者或创建日期。但并非所有文档都具有这些元数据信息,因为许多生成 Word 文档的工具不一定会填充这些属性:
>>> doc.core_properties.title 'Research Overview of Adversarial Attacks and Defenses on Graphs' >>> doc.core_properties.keywords 'Abstract' >>> doc.core_properties.modified datetime.datetime(2020, 8, 1, 3, 11)
Word 文档中最重要的特点是数据以段落(而不是页)的形式结构化。字体大小、段落缩进和其他因素都可能会使页数发生变化。检查段落数:
>>> len(doc.paragraphs) 28
浏览段落以检测包含文本的段落,大多数段落通常是空的,或者只包含换行符、制表符或其他空白字符,检查段落时我们通常跳过这些空段落:
>>> for index, paragraph in enumerate(doc.paragraphs): ... if paragraph.text: ... print(index, paragraph.text)= ... 0 图对抗攻防综述 1 摘 要: 3 关键字: 5 Research Overview of Adversarial Attacks and Defenses on Graphs 6 Abstract 7 Deep neural networks (DNNs) have been widely applied to various applications, including image classification, ... 8 ... ... 27 参考文献
可以利用 paragraphs 属性获取文档段落列表并提取原始格式的文本,这些文本不包括样式信息,通常是自动处理数据时最常用的属性。获取第 5 段和第 6 段的文本,分别对应第一页的标题和副标题:
>>> doc.paragraphs[5].text 'Research Overview of Adversarial Attacks and Defenses on Graphs' >>> doc.paragraphs[6].text 'Abstract '
每个段落都有一个 runs 属性,这是具有不同样式属性的文本分割列表。检查不同文本段落是否为粗体或斜体:
>>> doc.paragraphs[5].runs[0].bold True >>> doc.paragraphs[5].runs[0].italic >>> doc.paragraphs[6].runs[0].bold >>> doc.paragraphs[6].runs[0].italic True
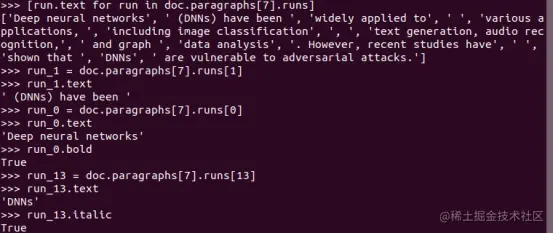
在示例 Word 文档中,大多数段落只有一个 run (即每个段落使用相同的样式),但我们在第 7 段中文本具有许多不同的样式。例如,Deep neural networks 使用粗体样式,DNNs 使用斜体样式:
>>> run_0 = doc.paragraphs[7].runs[0] >>> run_0.text 'Deep neural networks' >>> run_0.bold True >>> run_13 = doc.paragraphs[7].runs[13] >>> run_13.text 'DNNs' >>> run_13.italic True
到此这篇关于Python 读取 Word 文档操作的文章就介绍到这了,更多相关Python 读取 Word 文档内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python读取word文档的方法
本文实例讲述了python读取word文档的方法.分享给大家供大家参考.具体如下: 首先下载安装win32com from win32com import client as wc word = wc.Dispatch('Word.Application') doc = word.Documents.Open('c:/test') doc.SaveAs('c:/test.text', 2) doc.Close() word.Quit() 这种方式产生的text文档,不能用python用普通的r方
-
使用python批量读取word文档并整理关键信息到excel表格的实例
目标 最近实验室里成立了一个计算机兴趣小组 倡议大家多把自己解决问题的经验记录并分享 就像在CSDN写博客一样 虽然刚刚起步 但考虑到后面此类经验记录的资料会越来越多 所以一开始就要做好模板设计(如下所示) 方便后面建立电子数据库 从而使得其他人可以迅速地搜索到相关记录 据说"人生苦短,我用python" 所以决定用python从docx文档中提取文件头的信息 然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了) 而且点击文件路径可以直接打开对应的文件(含超链接) 代码
-

Python读取HTML中的canvas并且以图片形式存入Word文档
目录 前言 创建Word文档并插入 插入到已存在的Word文档指定的位置 前言 朋友提问: 创建Word文档并插入 市面上有很多图表绘制库,例如echarts和highcharts等等.对于这种由js动态绘制的图表,我们只能控制游览器自动截图存入word, 完整代码如下: from docx import Document import os from selenium import webdriver browser = webdriver.Chrome() # 调整游览器大小达到调整图表宽度
-
python读取word文档,插入mysql数据库的示例代码
表格内容如下: 1.实现批量导入word文档,取文档标题中的数字作为编号 2.除取上面打钩的内容需要匹配出来入库入库,其他内容全部直接入库mysql # wuyanfeng # -*- coding:utf-8 -*- # 读取docx中的文本代码示例 import docx import pymysql import re import os # 创建数据库链接 conn = pymysql.connect( host='rm-bp1vu5d84dg12c6d59o.mysql.rds.ali
-
Python 读取 Word 文档操作
目录 前言 Python 读取 Word 文档 安装 python-docx库 前言 Word 文档 (.docx) 是另一种主要用于存储文本的常见文档.它们通常由 Microsoft Office 创建和编辑,但也可以使用其他工具生成兼容文件.它们通常是共享可编辑文件的最常见格式,同时在分发文档时也非常常见. Python 读取 Word 文档 安装 python-docx库 在本节中,我们将学习如何使用 Python 从 Word 文档中提取文本信息.我们主要使用 python-docx 库
-
python实现word文档批量转成自定义格式的excel文档的思路及实例代码
支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符 最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个.而且可能有几十份这样的试题. 而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档.这个如果是手动一个个粘贴到excel表格,那就头大了. 我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内
-
如何基于Python实现word文档重新排版
介绍 舍友从网上下载的word题库文档很乱,手动改了大半天才改了一点,想起python是大名鼎鼎的自动化脚本,于是乎开始了python对word的一顿瞎操作. 分析需求 对文档中的内容进行分析,只留下题目,选项,并且题号要从1开始. 编写代码 pip安装python-docx模块 读取word文档内容(如果是以.doc后缀的文件需另存为.docx文件!) from docx import Document # 打开文件 srcdocx = Document('src.docx') # 遍历所有段
-
用python将word文档合并实例代码
目录 背景: 设计思路: 脚本环境说明: 完整代码: 功能执行效果图: 总结: 背景: 由于工作需要,现在有这么一个需求,要合并大量的word文档,而且要在不同的目录下找到同一个人的word文档,进行合并,最终输出一个合并后的word文档.一般来说几个或者十几个量不多的话,就手工合并一下好了,但现在这个量是真的大.目录有十多个,每个目录又有50多个不同人的word文档,而且同一个人在不同目录下又不一定都有word文档,因此,整个合并工作就出现了人工操作的困难: 工作量多:容易疏漏
-
PHP读取word文档的方法分析【基于COM组件】
本文实例讲述了PHP读取word文档的方法.分享给大家供大家参考,具体如下: php开发 过程中可能会word文档的读取问题,这里可以利用com组件来完成此项操作 一.先开启php.ini的COM,操作如下 1. extension=php_com_dotnet.dll 2. com.allow_dcom = true 二.开启之后就可以试下如下操作 1.建立一个指向新COM组件的索引 $word = new COM("word.application") or die("C
-
易语言读取Word文档方法
Office办公软件,相信大家都已经很熟悉了.如何读取Word文档内容,相信大家也都知道.但是,笔者今天要说的是,易语言怎么读取Word文档内容呢? 1.首先,为了配合此次程序测试,我们事先准备好一个Word文件即Docx文件,为了使得软件能正确读取出其中内容,我们在Word文件中,输入"百度经验"作为测试标示.如图: 2.测试文件已就位,打开"易语言",在弹出的"新建工程文件"对话框中,选择"Windows窗口程序"并点击&
-
java读取word文档,提取标题和内容的实例
使用的工具为poi,需要导入的依赖如下 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <arti