Python有关Unicode UTF-8 GBK编码问题详解
目录
- 1.统一码(Unicode)
- 2.UTF-8编码
- 总结
1.统一码(Unicode)
Unicode也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。对于世界上所有的语言文字再unicode中都可以查看到。【汉】字的编码解释官网https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=6C49
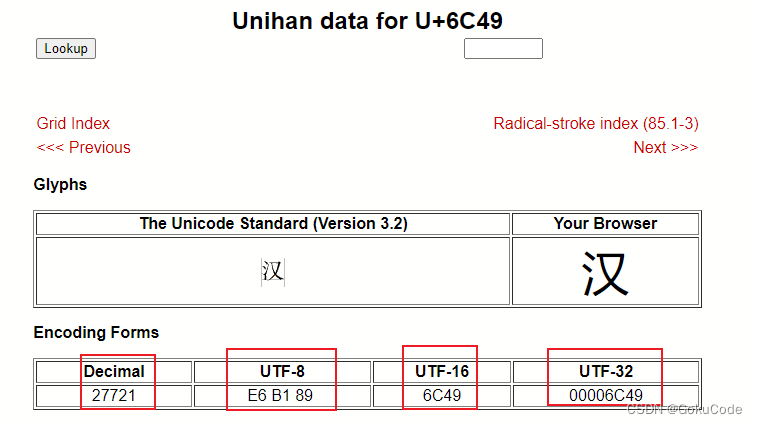
unicode编码就是为了统一世界上的编码,有一个统一的规范。但是它还存在一些问题。
Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题
- 第一个:如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 第二个:我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
- 出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。
- unicode在很长一段时间内无法推广,直到互联网的出现。
2.UTF-8编码
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------±--------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Python代码举例:
a = '\u6c49' # 汉的unicode编码
print(a)
a = '汉'
print("汉字utf8格式:",a.encode('utf8'))
print('汉字unicode格式:',a.encode('unicode_escape'))
print('汉字gbk格式:',a.encode('gbk'))
print('汉字gb2312格式:',a.encode('gb2312'))
# 输出结果
汉
汉字utf8格式: b'\xe6\xb1\x89'
汉字unicode格式: b'\\u6c49'
汉字gbk格式: b'\xba\xba'
汉字gb2312格式: b'\xba\xba'
可以看到以上结果,汉字的汉通过print打印时用的是unicode编码,存储时使用utf8,也即是我们保存文件时常用的编码
with open('xxx.txt','w',encoding='utf-8') as f:
f.write(xxx)
打开的时候也要指定文件编码
with open(file_path, encoding='utf-8') as f:
f.read()
当使用gbk编码保存的文件使用utf8打开时会报错,使用gbk打开即可
with open(r'gbk.txt','r',encoding='utf8') as f:
print(f.read())
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
总结
- UNICODE是一个符号集合,对全世界的语言都对应一个符号编码
- UTF-8是UNICODE在计算机中存储时的具体体现,是存储方案
- UTF-16同理
- UTF-32同理
- GB 2312 或 GB 2312-80 是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》,又稱為GB0,由中国国家标准总局发布,1981年5月1日实施。
- GBK: 汉字国标扩展码,基本上采用了原来GB2312-80所有的汉字及码位,并涵盖了原Unicode中所有的汉字20902,总共收录了883个符号, 21003个汉字及提供了1894个造字码位。
参考链接
到此这篇关于Python有关Unicode UTF-8 GBK编码问题详解 的文章就介绍到这了,更多相关Python Unicode UTF-8 GBK编码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python解决汉字编码问题:Unicode Decode Error
前言 最近由于项目需要,需要读取一个含有中文的txt文档,完了还要保存文件.文档之前是由base64编码,导致所有汉字读取显示乱码.项目组把base64废弃之后,先后出现两个错误: ascii codec can't encode characters in position ordinal not in range 128 UnicodeDecodeError: 'utf8' codec can't decode byte 0x. 如果对于ascii.unicode和utf-8还不了解的小伙伴
-
Python实现把utf-8格式的文件转换成gbk格式的文件
需求:将utf-8格式的文件转换成gbk格式的文件 实现代码如下: 复制代码 代码如下: def ReadFile(filePath,encoding="utf-8"): with codecs.open(filePath,"r",encoding) as f: return f.read() def WriteFile(filePath,u,encoding="gbk"): with codecs.open(
-

Python UnicodedecodeError编码问题解决方法汇总
目录 1.情景一 2.情景二 3.情景三 4. chardet模块detect()函数 今天真的被编码问题一直困扰着,午休都没进行.也真的见识到了各种编码.例如:gbk,unicode.utf-8.ansi.gb2312等.如果脚本程序中编码与文件编码不一致,就会报出UnicodedecodeError的错误. 1.情景一 读文件时常需要将内容转为utf8,文字可正常显示,但是如果原文件内容编码格式不是utf8就会报错UnicodedecodeError.如下: 问题: try: fileObj
-
Python中的字符串操作和编码Unicode详解
本文主要给大家介绍了关于 Python中的字符串操作和编码Unicode的一些知识,下面话不多说,需要的朋友们下面来一起学习吧. 字符串类型 str:Unicode字符串.采用''或者r''构造的字符串均为str,单引号可以用双引号或者三引号来代替.无论用哪种方式进行制定,在Python内部存储时没有区别. bytes:二进制字符串.由于jpg等其他格式的文件不能用str进行显示,所以才用bytes来表示,bytes的每个字节为一个0-255的数字.如果打印的时候,Python会把能够用ASCI
-
python3的url编码和解码,自定义gbk、utf-8的例子
因为很多时候要涉及到url的编码和解码工作,所以自己制作了一个类,废话不多说 码上见! # coding:utf-8 import urllib.parse class Urlchuli(): """Url处理类,需要传入两个实参:Urlchuli('实参','编码类型'),默认utf-8 url编码方法:url_bm() url解码方法:url_jm()""" def __init__(self,can,mazhi='utf-8'): self
-
浅谈Python2之汉字编码为unicode的问题(即类似\xc3\xa4)
Python2中编码相关的问题很是让人蛋疼,特别是中文字符. 比如本文所述的中文网页GBK编码的诡异问题. 现象 例如:盲录職氓聭聵,其实网页里面正常的应该是会员 分析 接着上面的例子,会员这部分乱码通过repr()函数求值得到如下结果 \xc3\xa4\xc2\xbc\xc2\x9a\xc3\xa5\xc2\x91\xc2\x98 使用type()函数求值得到的结果为unicode eval(repr())出来值为 盲录職氓聭聵 通过查表上述6个汉字对应 c3a4 c2bc c29a c3a5
-
python实现unicode转中文及转换默认编码的方法
本文实例讲述了python实现unicode转中文及转换默认编码的方法.分享给大家供大家参考,具体如下: 一.在爬虫抓取网页信息时常需要将类似"\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8"转换为中文,实际上这是unicode的中文编码.可用以下方法转换: 1. >>> s = u'\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8' >>> print s 人生苦短,
-
Python有关Unicode UTF-8 GBK编码问题详解
目录 1.统一码(Unicode) 2.UTF-8编码 总结 1.统一码(Unicode) Unicode也叫万国码.单一码,是计算机科学领域里的一项业界标准,包括字符集.编码方案等.对于世界上所有的语言文字再unicode中都可以查看到.[汉]字的编码解释官网https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=6C49 unicode编码就是为了统一世界上的编码,有一个统一的规范.但是它还存在一些问题. Unicode的问题 需
-
解决Python print 输出文本显示 gbk 编码错误问题
前阵子想爬点东西,结果一直提示错误UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position,在网上一查,发现是 Windows 的控制台的问题.控制台的编码是 GBK,Python 是 UTF-8,造成了冲突.下面给出三种解决方法. 第一种方法:直接替换出错的内容 import requests url = 'https://blog.csdn.net/jianhong1990/article/detail
-
python源文件的字符编码知识点详解
默认情况下,Python 源码文件以 UTF-8 编码方式处理.在这种编码方式中,世界上大多数语言的字符都可以同时用于字符串字面值.变量或函数名称以及注释中--尽管标准库中只用常规的 ASCII 字符作为变量或函数名,而且任何可移植的代码都应该遵守此约定.要正确显示这些字符,你的编辑器必须能识别 UTF-8 编码,而且必须使用能支持打开的文件中所有字符的字体. 1.如果不使用默认编码,要声明文件所使用的编码,文件的第一行要写成特殊的注释. 语法如下所示: # -*- coding: encodi
-
python 读取excel文件生成sql文件实例详解
python 读取excel文件生成sql文件实例详解 学了python这么久,总算是在工作中用到一次.这次是为了从excel文件中读取数据然后写入到数据库中.这个逻辑用java来写的话就太重了,所以这次考虑通过python脚本来实现. 在此之前需要给python添加一个xlrd模块,这个模块是专门用来操作excel文件的. 在mac中可以通过easy_install xlrd命令实现自动安装模块 import xdrlib ,sys import xlrd def open_excel(fil
-
对python:print打印时加u的含义详解
u:表示unicode字符串 不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码. 一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u:但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码. 建议所有编码方式采用utf8 print u"当前列表文件为 %d" %n 以上这篇对python:print打印时加u的含义详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python接口自动化之cookie、session应用详解
目录 一.cookie 1.cookie介绍 2.cookie原理 二.session 1.session介绍 2.session原理 1. 存储位置不同: 2. 存储容量不同: 3. 存取方式不同: 4. 隐私策略/安全性不同: 5. 有效期不同: 6. 服务器压力不同: 三.cookie和session区别 四.cookie应用 五.session应用 在上一篇Python接口自动化测试系列文章:Python接口自动化之浅析requests模块post请求,介绍了post源码,data.js
-
Python 网页请求之requests库的使用详解
目录 1.requests库简介 2.requests库方法介绍 3.代码实例 1.requests库简介 requests 是 Python 中比较常用的网页请求库,主要用来发送 HTTP 请求,在使用爬虫或测试服务器响应数据时经常会用到,使用起来十分简洁. requests 为第三方库,需要我们通过pip命令安装: pip install requests 2.requests库方法介绍 下表列出了requests库中的各种请求方法: 方法 描述 delete(url, args) 发送 D
-
Python黑帽编程 3.4 跨越VLAN详解
VLAN(Virtual Local Area Network),是基于以太网交互技术构建的虚拟网络,既可以将同一物理网络划分成多个VALN,也可以跨越物理网络障碍,将不同子网中的用户划到同一个VLAN中.图2是一个VLAN划分的例子. 图2 实现VLAN的方式有很多种,基于交换设备的VLAN划分,一般有两种: l 基于交换机的端口划分 l 基于IEEE 802.1q协议,扩展以太网帧格式 基于第二层的VLAN技术,有个Trunking的概念,Trunking是用来在不同的交换机之间进行连接,以
-
javascript url几种编码方式详解
1. escape() 不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值.比如"春节"的返回结果是%u6625%u8282,escape()不对"+"编码主要用于汉子编码,现在已经不提倡使用了. 2. encodeURI()是javascript中真正用来对URL编码的函数.编码整个URL地址,但对特殊含义的符号";/?:@&=+$,#",也不进行编码.对应的解码函数是decodeURI(). 3. encodeU
-
python中 chr unichr ord函数的实例详解
python中 chr unichr ord函数的实例详解 chr()函数用一个范围在range(256)内的(就是0-255)整数作参数,返回一个对应的字符.unichr()跟它一样,只不过返回的是Unicode字符,这个从Python 2.0才加入的unichr()的参数范围依赖于你的python是如何被编译的.如果是配置为USC2的Unicode,那么它的允许范围就是range(65536)或0x0000-0xFFFF:如果配置为UCS4,那么这个值应该是range(1114112)或0x