Python进阶之import导入机制原理详解
目录
- 前言
- 1. Module组成
- 1.1 Module 内置全局变量
- 2. 包package
- 2.1 实战案例
- 3.sys.modules、命名空间
- 3.1 sys.modules
- 3.2 命名空间
- 4. 导入
- 4.1 绝对导入
- 4.2 相对导入
- 4.3 单独导入包
- 5. import运行机制
- 5.1 标准import,顶部导入
- 5.2 嵌套import
前言
在Python中,一个.py文件代表一个Module。在Module中可以是任何的符合Python文件格式的Python脚本。了解Module导入机制大有用处。
1. Module组成
一个.py文件就是一个module。Module中包括attribute, function等。 这里说的attribute其实是module的global variable。
我们创建1个test1.py文件,代码如下
# 定义1个全局变量a
a = 1
# 声明一个全局变量moduleName
global moduleName
# 定义一个函数printModuleName
def printModuleName():
print(a + 2)
print(__name__)
print(moduleName)
print(dir())
这里我们定义了3个全局变量a、moduleName、printModuleName,除了我们自己定义的以外还有module内置的全局变量
1.1 Module 内置全局变量
上面我们说到了,每一个模块都有内置的全局变量,我们可以使用dir()函数,用于查看模块内容,例如上面的例子中,使用dir()查看结果如下:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'moduleName', 'printModuleName']
其中a, moduleName, printModuleName 是由用户自定义的。其他的全是内置的。下面介绍几个常用的内置全局变量
1.1.1 __name__
指的是当前模块的名称,比如上面的test1.py,模块的名称默认就是test1,如果一个module是程序的入口,那么__name__=__'main'__,这也是我们经常看到用到的
1.1.2 __builtins__
它就是内置模块builtins的引用。可以通过如下代码测试:
import builtins print(builtins == __builtins__)
打印结果为True,在Python代码里,不需要我们导入就能直接使用的函数、类等,都是在这个内置模块里的。例如:range、dir
1.1.3 __doc__
它就是module的文档说明,具体是文件头之后、代码(包含import)之前的第一个多行注释,测试如下
"""
模块导入机制测试
"""
import builtins
# 定义1个全局变量a
a = 1
# 声明一个全局变量moduleName
global moduleName
# 定义一个函数printModuleName
def printModuleName():
print(a + 2)
print(__name__)
print(moduleName)
print(__doc__)
最后打印结果为
模块导入机制测试
当然如果你想查看某个方法的说明,也可以这么使用

1.1.4 __file__
当前module所在的文件的绝对路径
1.1.5 __package__
当前module所在的包名。如果没有,为None。
2. 包package
为避免模块名冲突,Python引入了按目录组织模块的方法,称之为包(package)。包是含有Python模块的文件夹。
当一个文件夹下有init.py时,意为该文件夹是一个包(package),其下的多个模块(module)构成一个整体,而这些模块(module)都可通过同一个包(package)导入其他代码中。
其中init.py文件用于组织包(package),方便管理各个模块之间的引用、控制着包的导入行为。
该文件可以什么内容都不写,即为空文件,存在即可,相当于一个标记。
但若想使用from pacakge_1 import *这种形式的写法,需在init.py中加上:__all__ = ['file_a', 'file_b'],并且package_1下有file_a.py和file_b.py,在导入时init.py文件将被执行。
但不建议在init.py中写模块,以保证该文件简单。不过可在init.py导入我们需要的模块,以便避免一个个导入、方便使用。
其中,__all__是一个重要的变量,用来指定此包(package)被import *时,哪些模块(module)会被import进【当前作用域中】。不在__all__列表中的模块不会被其他程序引用。可以重写__all__,如__all__= ['当前所属包模块1名字', '模块1名字'],如果写了这个,则会按列表中的模块名进行导入
在模糊导入时,形如from package import *,*是由__all__定义的。
当我们在导入一个包(package)时(会先加载__init__.py定义的引入模块,然后再运行其他代码),实际上是导入的它的__init__.py文件(导入时,该文件自动运行,助我们一下导入该包中的多个模块)。我们可以在 init.py中再导入其他的包(package)或模块或自定义类。
2.1 实战案例
首先我们创建3个包,分别是test、test2、test3test包下创建test1.py用来执行测试
test2包下创建file_a.py、file_b.py,用来测试包的导入
test3包下创建file_c.py,辅助测试
具体结构如下:

核心代码在test2/__init__.py中如下
__all__ = ['file_a', 'file_b', 'file_c', 'test_d']
from test3 import file_c
def test_d():
return "test_d"
解释下,当我们在test/test1.py中写了from test2 import *这句代码,程序不是直接导入test2下的所有模块,而是导入__init__.py文件并自动运行,由于我们写了__all__ = ['file_a', 'file_b', 'file_c', 'test_d'],file_a和file_b是当下包中的模块,file_c是我们从test3包中导入的,test_d是__init__.py下我们定义的函数。
所以from test2 import *就是把__all__中指定的模块和函数导入进来了,接着我们查看test1.py下的代码
from test2 import * print(file_a.a()) print(file_b.b()) print(file_c.c()) print(test_d())
如果打印有结果,则证明了导入成功,并且导入的是__all__下的模块和函数
3.sys.modules、命名空间
3.1 sys.modules
sys.modules是一个将模块名称映射到已加载的模块的字典。可用来强制重新加载modules。Python一启动,它将被加载在内存中。
当我们导入新modules,sys.modules将自动记录下该module;当第二次再导入该module时,Python将直接到字典中查找,加快运行速度。
它是1个字典,故拥有字典的一切方法,如sys.modules.keys()、sys.modules.values()、sys.modules['os']。但请不要轻易替换字典、或从字典中删除某元素,将可能导致Python运行失败。
3.2 命名空间
命名空间就像一个dict,key是变量名字,value是变量的值。
- 每个函数function都有自己的命名空间,称local namespace,记录函数的变量。
- 每个模块module都有自己的命名空间,称global namespace,记录模块的变量,包括functions、classes、导入的modules、module级别的变量和常量。
- build-in命名空间,它包含build-in function和exceptions,可被任意模块访问。
假设你要访问某段Python代码中的变量x时,Python会在所有的命名空间中查找该变量,顺序是:
- local namespace 即当前函数或类方法。若找到,则停止搜索;
- global namespace 即当前模块。若找到,则停止搜索;
- build-in namespace Python会假设变量x是build-in的内置函数或变量。若变量x不是build-in的内置函数或变量,Python将报错NameError。
- 对于闭包,若在local namespace找不到该变量,则下一个查找目标是父函数的local namespace。
我们可以看一个小例子
# test_namespace.py
def func(a=1):
b = 2
print(locals()) # 打印当前函数的局部命名空间
'''
locs = locals() # 只读,不可写,会报错
locs['c'] = 3
print(c)
'''
return a + b
func()
glos = globals()
glos['d'] = 4
print(d)
print(globals())
执行func()会打印函数func的局部命名空间,结果如下:
{'a': 1, 'b': 2}
执行print(globals())会打印模块test_namespace的全局命名空间,结果如下:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fde2605c730>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/jkc/PycharmProjects/pythonProject1/test_namespace.py', '__cached__': None, 'func': <function func at 0x7fde246b9310>, 'glos': {...}, 'd': 4}
内置函数locals()、globals()都会返回一个字典。区别:前者只读、后者可写。
命名空间在from module_name import、import module_name中的体现:from关键词是导入模块或包中的某个部分。
from module_A import X:会将该模块的函数/变量导入到当前模块的命名空间中,无须用module_A.X访问了。
import module_A:modules_A本身被导入,但保存它原有的命名空间,故得用module_A.X方式访问其函数或变量。
接下来我们测试一下:
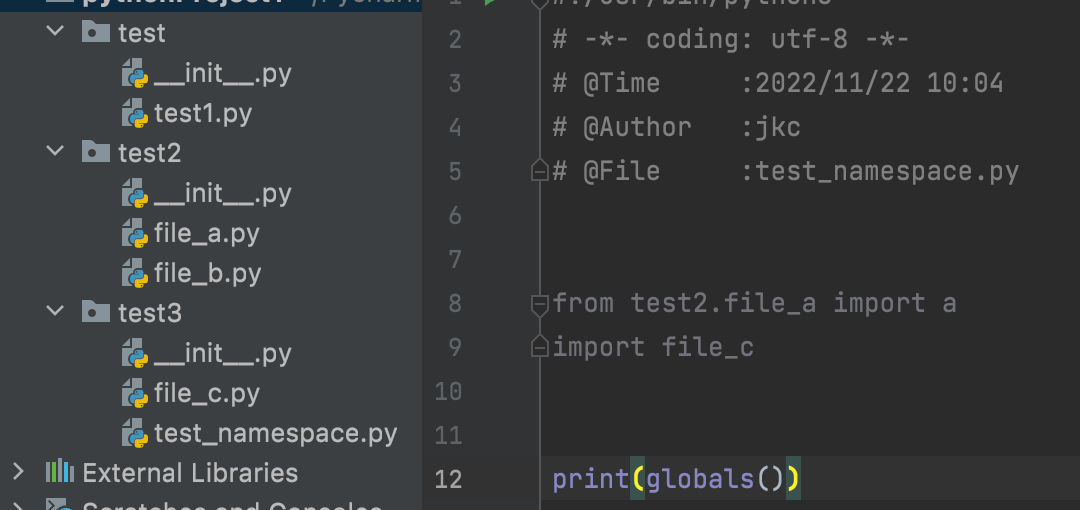
可以看到我们导入了函数a和模块file_c,接着我们打印了全局变量,结果如下:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fab9585c730>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/jkc/PycharmProjects/pythonProject1/test3/test_namespace.py', '__cached__': None, 'a': <function a at 0x7fab95b04040>, 'file_c': <module 'file_c' from '/Users/jkc/PycharmProjects/pythonProject1/test3/file_c.py'>}
可以很清楚的看到全局变量中有函数a和模块file_c,接着我们尝试能否调用者2个
from test2.file_a import a import file_c print(globals()) file_c.c() a()
最后也是可以成功调用
4. 导入
准备工作如下:

4.1 绝对导入
所有的模块import都从“根节点”开始。根节点的位置由sys.path中的路径决定,项目的根目录一般自动在sys.path中。如果希望程序能处处执行,需手动修改sys.path。
例1:c.py中导入B包/B1子包/b1.py模块
import os import sys BASE_DIR = os.path.dirname(os.path.abspath(__file__)) sys.path.append(BASE_DIR) # 导入B包中的子包B1中的模块b1 from B.B1 import b1
例2:b1.py中导入b2.py模块
# 从B包中的子包B1中导入模块b2 from B.B1 import b2
4.2 相对导入
只关心相对自己当前目录的模块位置就好。不能在包(package)的内部直接执行(会报错)。不管根节点在哪儿,包内的模块相对位置都是正确的。
b1.py代码如下:
# from . import b2 # 这种导入方式会报错 import b2 # 正确 b2.print_b2()
b2.py代码如下:
def print_b2():
print('b2')
最后运行b1.py,打印b2。
4.3 单独导入包
单独import某个包名称时,不会导入该包中所包含的所有子模块。
c.py导入同级目录B包的子包B1包的b2模块,执行b2模块的print_b2()方法:
c.py代码
import B B.B1.b2.print_b2()
运行c.py会以下错误
AttributeError: module 'B' has no attribute 'B1'
因为import B并不会自动将B下的子模块导入进去,需要手动添加,解决办法如下
在B/init.py代码下添加如下代码
from . import B1
在B/B1/init.py代码下添加如下代码
from . import b2
此时,执行c.py,成功打印b2。
5. import运行机制
我们要理解Python在执行import语句时,进行了啥操作?
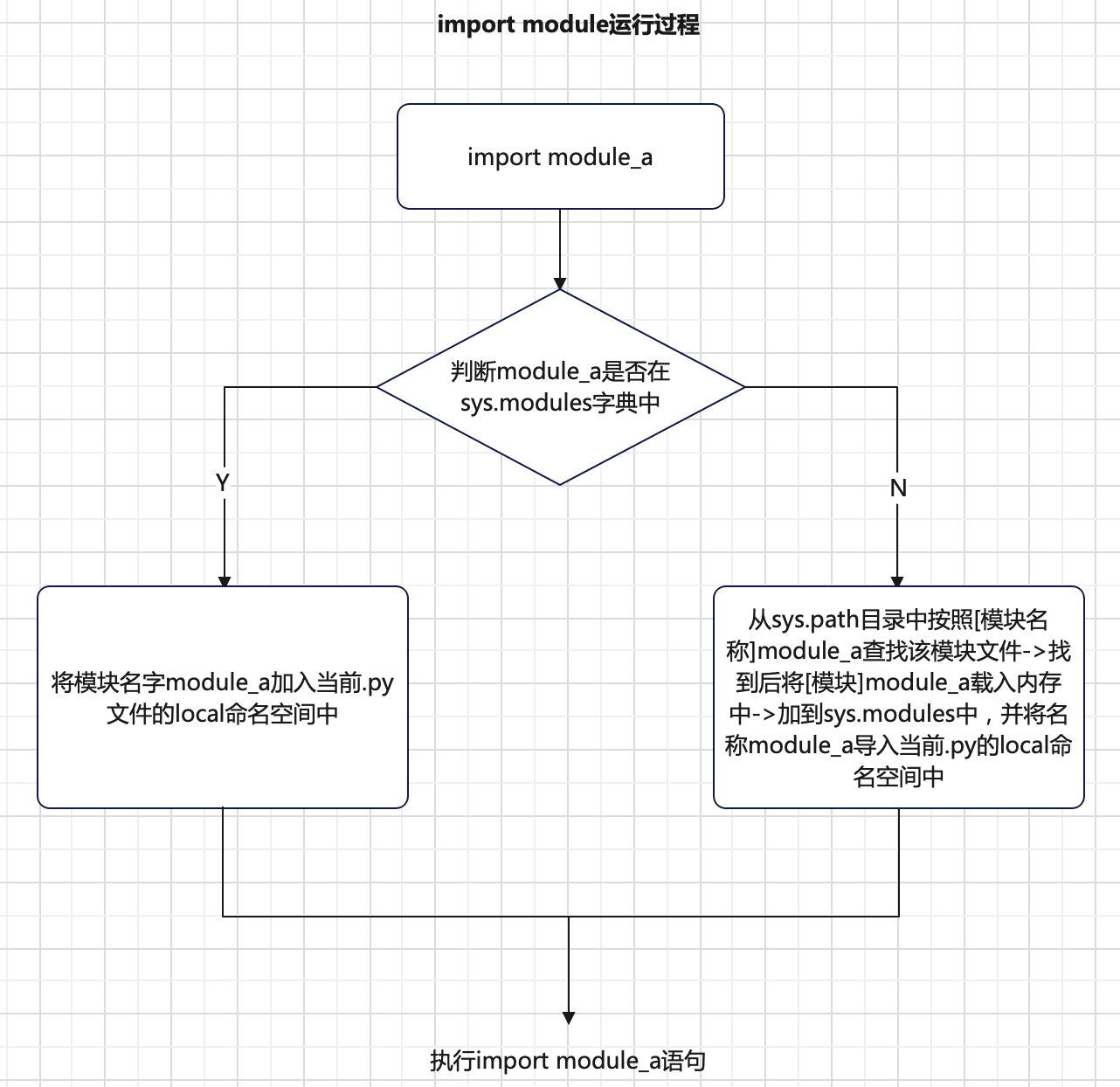
step1:创建一个新的、空的module对象(它可能包含多个module);
step2:将该module对象 插入sys.modules中;
step3:装载module的代码(如果需要,需先编译);
step4:执行新的module中对应的代码。
在执行step3时,首先需找到module程序所在的位置,如导入的module名字为mod_1,则解释器得找到mod_1.py文件,搜索顺序是:
当前路径(或当前目录指定sys.path)->PYTHONPATH->Python安装设置相关的默认路径。
对于不在sys.path中,一定要避免用import导入自定义包(package)的子模块(module),而要用from…import…的绝对导入或相对导入,且包(package)的相对导入只能用from形式。
5.1 标准import,顶部导入
5.2 嵌套import
5.2.1 顺序导入-import
- moduleB定义了变量b=2
- moduleA导入模块moduleB,当然moduleB还可以导入其他模块
- test模块导入moduleA

最后执行test.py,将打印3
5.2.2 循环导入/嵌套导入
moduleA.py
from moduleB import ClassB
class ClassA:
pass
moduleB.py
from moduleA import ClassA
class ClassB:
pass
当执行moduleA.py时会报错
ImportError: cannot import name 'ClassA' from partially initialized module 'moduleA'
报错分析:
1.在运行moduleA时,首选会执行from moduleB import ClassB代码
2.程序会判断sys.modules中是否有
3.有代表字在第一次执行时,创建的对象已经缓存在sys.modules,直接得到,不过依然是空对象,因为__dict__找不到ClassB,会报错
4.没有会为moduleB.py创建1个module对象,此时创建的module对象为空
- 4.1 然后执行moduleB.py的第一条语句
from moduleA import ClassAPS:这么做的原因是python内部创建了module对象后立马执行moduleB.py,目的是填充<module moduleB>的__dict__,当然最终未能成功填充 - 4.2 接着判断sys.modules中是否有
- 4.3 没有会为moduleA.py创建1个module对象
PS:此时创建的module对象同样为空,则需要执行moduleA.py语句from moduleB import ClassB
5.最后回到操作2的过程,这次判断有module对象,会进行操作3,最后就会报错cannot import name 'ClassA'
解决办法:组织代码(重构代码):更改代码布局,可合并或分离竞争资源。
到此这篇关于Python进阶之import导入机制原理详解的文章就介绍到这了,更多相关Python import导入机制内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python 中的 import 机制之实现远程导入模块
所谓的模块导入( import ),是指在一个模块中使用另一个模块的代码的操作,它有利于代码的复用. 在 Python 中使用 import 关键字来实现这个操作,但不是唯一的方法,还有 importlib.import_module() 和 __import__() 等. 也许你看到这个标题,会说我怎么会发这么基础的文章? 与此相反.恰恰我觉得这篇文章的内容可以算是 Python 的进阶技能,会深入地探讨并以真实案例讲解 Python import Hook 的知识点. 当然为了使文章更系统.
-
Python中import导入不同目录的模块方法详解
测试的目录如下: root ├── module_root.py ├── package_a │ ├── child │ │ ├── __init__.py │ │ └── child_a.py │ ├── module.py │ └── module_a.py └── package_b └── module_b.py 每个文件中的内容如下(__init__.py文件可以为空): print(__name
-
python import 上级目录的导入
有时候我们可能需要import另一个路径下的python文件,例如下面这个目录结构,我们想要在_train.py里import在networks目录下的_lstm.py和上级目录下的_config.py. _config.py networks _lstm.py _cnn.py pipelines _train.py 只需两步操作 (1)在networks文件夹下创建空的__init__.py文件 _config.py networks _lstm.py _cnn.py pipelines _t
-
关于python导入模块import与常见的模块详解
0.什么是python模块?干什么的用的? Java中如果使用abs()函数,则需要需要导入Math包,同样python也是封装的,因为python提供的函数太多,所以根据函数的功能将其封装在不同的module模块中.就这样的话,pthon提供的module还是海量的,所以除非使用某个模块里的某个函数时才会将其导入程序中.所以你使用某个函数前,要先知道他在哪个module里,然后将这个模块导入当前程序,然后才能调用这个模块里的函数. 当然 python的模块分为用户自定义的和系统提供的.Pyth
-
Python进阶之import导入机制原理详解
目录 前言 1. Module组成 1.1 Module 内置全局变量 2. 包package 2.1 实战案例 3.sys.modules.命名空间 3.1 sys.modules 3.2 命名空间 4. 导入 4.1 绝对导入 4.2 相对导入 4.3 单独导入包 5. import运行机制 5.1 标准import,顶部导入 5.2 嵌套import 前言 在Python中,一个.py文件代表一个Module.在Module中可以是任何的符合Python文件格式的Python脚本.了解Mo
-
Python代码块及缓存机制原理详解
这篇文章主要介绍了Python代码块及缓存机制原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.相同的字符串在Python中地址相同 s1 = 'panda' s2 = 'panda' print(s1 == s2) #True print(id(s1) == id (s2)) #True 2.代码块: 所有的代码都需要依赖代码块执行. 一个模块,一个函数,一个类,一个文件等都是一个代码块 交互式命令中, 一行就是一个代码块
-
Python进阶_关于命名空间与作用域(详解)
写在前面 如非特别说明,下文均基于Python3 命名空间与作用于跟名字的绑定相关性很大,可以结合另一篇介绍Python名字.对象及其绑定的文章. 1. 命名空间 1.1 什么是命名空间 Namespace命名空间,也称名字空间,是从名字到对象的映射.Python中,大部分的命名空间都是由字典来实现的,但是本文的不会涉及命名空间的实现.命名空间的一大作用是避免名字冲突: def fun1(): i = 1 def fun2(): i = 2 同一个模块中的两个函数中,两个同名名字i之间绝没有任何
-
python进阶collections标准库使用示例详解
目录 前言 namedtuple namedtuple的由来 namedtuple的格式 namedtuple声明以及实例化 namedtuple的方法和属性 OrderedDict popitem(last=True) move_to_end(key, last=True) 支持reversed 相等测试敏感 defaultdict 小例子1 小例子2 小例子3 Counter对象 创建方式 elements() most_common([n]) 应用场景 deque([iterable[,
-
对Golang import 导入包语法详解
package 的导入语法 写 Go 代码的时经常用到 import 这个命令用来导入包,参考如下: import( "fmt" ) 然后在代码里面可以通过如下的方式调用: fmt.Println( "我爱北京天安门" ) fmt 是 Go 的标准库,它其实是去 GOROOT 下去加载该模块,当然 Go 的 import 还支持如下两种方式来加载自己写的模块: 相对路径 import "./model" // 当前文件同一目录的 model 目录
-

Mysql MVCC机制原理详解
什么是MVCC MVCC,全称Multi-Version Concurrency Control,即多版本并发控制.MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存. 我们知道,一般情况下我们使用mysql数据库的时候使用的是Innodb存储引擎,Innodb存储引擎是支持事务的,那么当多线程同时执行事务的时候,可能会出现并发问题.这个时候需要一个能够控制并发的方法,MVCC就起到了这个作用. Mysql的锁和事务隔离级别 在理解MVCC机制
-
Java基础学习之反射机制原理详解
目录 一.什么是反射 二.反射的原理 三.反射的优缺点 四.反射的用途 五.反射机制常用的类 六.反射的基本使用 一.什么是反射 (1)Java反射机制的核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法.本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息. (2)Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM.通过反射,可
-
Python爬虫JSON及JSONPath运行原理详解
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与后台之间的数据交互. JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java. JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML. JsonPath与XPath语法对
-
python内存管理机制原理详解
python内存管理机制: 引用计数 垃圾回收 内存池 1. 引用计数 当一个python对象被引用时 其引用计数增加 1 ; 当其不再被变量引用时 引用计数减 1 ; 当对象引用计数等于 0 时, 对象被删除(引用计数是一种非常高效的内存管理机制) 2. 垃圾回收 垃圾回收机制: ① 引用计数 , ②标记清除 , ③分带回收 引用计数 : 引用计数也是一种垃圾收集机制, 而且也是一种最直观, 最简单的垃圾收集技术.当python某个对象的引用计数降为 0 时, 说明没有任何引用指向该对象, 该
-
Python类和实例的属性机制原理详解
实例是具象化的类,它可以作为类访问所有静态绑定到类上的属性,包括类变量与方法,也可以作为实例访问动态绑定到实例上的属性. 实例1: class A: work = list("hello") kind = list("world") another = 1 def test1(self): print(self.work, self.kind, self.another) self.work[0], self.kind [0] = "t", &q