vue3调度器effect的scheduler功能实现详解
目录
- 一、调度执行
- 二、单元测试
- 三、代码实现
- 四、回归实现
- 五、结语
一、调度执行
说到scheduler,也就是vue3的调度器,可能大家还不是特别明白调度器的是什么,先大概介绍一下。
可调度性是响应式系统非常重要的特性。首先我们要明确什么是可调度性。所谓可调度性,指的是当trigger 动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式。
有了调度函数,我们在trigger函数中触发副作用函数重新执行时,就可以直接调用用户传递的调度器函数,从而把控制权交给用户。
举个栗子:
const obj = reactive({ foo: 1 });
effect(() => {
console.log(obj.foo);
})
obj.foo++;
obj.foo++;
首先在副作用函数中打印obj.foo的值,接着连续对其执行两次自增操作,输出如下:
1
2
3
由输出结果可知,obj.foo的值一定会从1自增到3,2只是它的过渡状态。如果我们只关心最终结果而不关心过程,那么执行三次打印操作是多余的,我们期望的打印结果是:
1
3
那么就考虑传入调度器函数去帮助我们实现此功能,那由此需求,我们先来实现一下scheduler功能。
二、单元测试
首先还是藉由单测来梳理一下功能,这是直接从vue3源码中粘贴过来对scheduler的单测,里面很详细的描述了scheduler的功能。
it('scheduler', () => {
let dummy;
let run: any;
const scheduler = jest.fn(() => {
run = runner;
});
const obj = reactive({ foo: 1 });
const runner = effect(
() => {
dummy = obj.foo;
},
{ scheduler },
);
expect(scheduler).not.toHaveBeenCalled();
expect(dummy).toBe(1);
// should be called on first trigger
obj.foo++;
expect(scheduler).toHaveBeenCalledTimes(1);
// should not run yet
expect(dummy).toBe(1);
// manually run
run();
// should have run
expect(dummy).toBe(2);
});
大概介绍一下这个单测的流程:
- 通过
effect的第二个参数给定的一个对象{ scheduler: () => {} }, 属性是scheduler, 值是一个函数; effect第一次执行的时候, 还是会执行fn;- 当响应式对象被
set,也就是数据update时, 如果scheduler存在, 则不会执行fn, 而是执行scheduler; - 当再次执行
runner的时候, 才会再次的执行fn.
三、代码实现
那接下来就直接开始代码实现功能,这里直接贴出完整代码了,// + 会标注出新增加的代码。
class ReactiveEffect {
private _fn: any;
// + 接收scheduler
// + 在构造函数的参数上使用public等同于创建了同名的成员变量
constructor(fn, public scheduler?) {
this._fn = fn;
}
run() {
activeEffect = this;
return this._fn();
}
}
// * ============================== ↓ 依赖收集 track ↓ ============================== * //
// * targetMap: target -> key
const targetMap = new WeakMap();
// * target -> key -> dep
export function track(target, key) {
// * depsMap: key -> dep
let depsMap = targetMap.get(target);
if (!depsMap) {
targetMap.set(target, (depsMap = new Map()));
}
// * dep
let dep = depsMap.get(key);
if (!dep) {
depsMap.set(key, (dep = new Set()));
}
dep.add(activeEffect);
}
// * ============================== ↓ 触发依赖 trigger ↓ ============================== * //
export function trigger(target, key) {
let depsMap = targetMap.get(target);
let dep = depsMap.get(key);
for (const effect of dep) {
// + 判断是否有scheduler, 有则执行,无则执行fn
if (effect.scheduler) {
effect.scheduler();
} else {
effect.run();
}
}
}
let activeEffect;
export function effect(fn, options: any = {}) {
// + 直接将scheduler挂载到依赖上
const _effect = new ReactiveEffect(fn, options.scheduler);
_effect.run();
return _effect.run.bind(_effect);
}
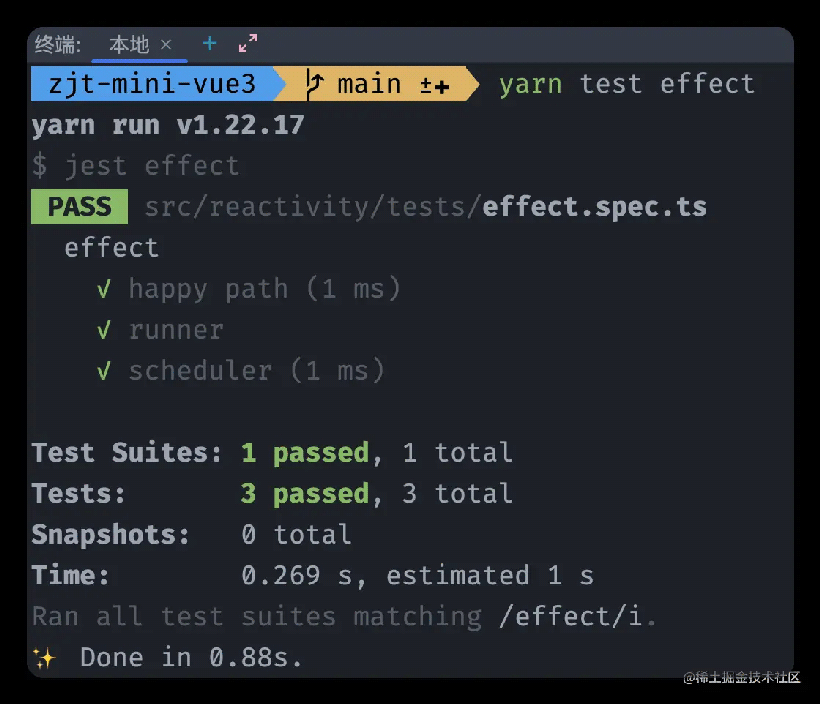
代码实现完成,那接下来看一下单测结果。
四、回归实现
好,现在我们再回到最初的栗子,在上面scheduler基础上,完成现有需求,继续看一下对此需求的单测。
it('job queue', () => {
// 定义一个任务队列
const jobQueue = new Set();
// 使用 Promise.resolve() 创建一个 Promise 实例,我们用它将一个任务添加到微任务队列
const p = Promise.resolve();
// 一个标志代表是否正在刷新队列
let isFlushing = false;
function flushJob() {
// 如果队列正在刷新,则什么都不做
if (isFlushing) return;
// 设置为true,代表正在刷新
isFlushing = true;
// 在微任务队列中刷新 jobQueue 队列
p.then(() => {
jobQueue.forEach((job: any) => job());
}).finally(() => {
// 结束后重置 isFlushing
isFlushing = false;
// 虽然scheduler执行两次,但是由于是Set,所以只有一项
expect(jobQueue.size).toBe(1);
// 期望最终结果拿数组存储后进行断言
expect(logArr).toEqual([1, 3]);
});
}
const obj = reactive({ foo: 1 });
let logArr: number[] = [];
effect(
() => {
logArr.push(obj.foo);
},
{
scheduler(fn) {
// 每次调度时,将副作用函数添加到 jobQueue 队列中
jobQueue.add(fn);
// 调用 flushJob 刷新队列
flushJob();
},
},
);
obj.foo++;
obj.foo++;
expect(obj.foo).toBe(3);
});
在分析上段代码之前,为了辅助完成上述功能,我们需要回到trigger中,调整一下遍历执行,为了让我们的scheduler能拿到原始依赖。
for (const effect of dep) {
// + 判断是否有scheduler, 有则执行,无则执行fn
if (effect.scheduler) {
effect.scheduler(effect._fn);
} else {
effect.run();
}
}
再观察上面的单测代码,首先,我们定义了一个任务队列jobQueue,它是一个Set数据结构,目的是利用Set数据结构的自动去重功能。
接着我们看调度器scheduler的实现,在每次调度执行时,先将当前副作用函数添加到jobQueue队列中,再调用flushJob函数刷新队列。
然后我们把目光转向flushJob函数,该函数通过isFlushing标志判断是否需要执行,只有当其为false 时才需要执行,而一旦flushJob函数开始执行,isFlushing标志就会设置为true,意思是无论调用多少次flushJob函数,在一个周期内都只会执行一次。
需要注意的是,在flushJob内通过p.then将一个函数添加到微任务队列,在微任务队列内完成对jobQueue的遍历执行。
整段代码的效果是,连续对obj.foo执行两次自增操作,会同步且连续地执行两次scheduler调度函数,这意味着同一个副作用函数会被jobQueue.add(fn)添加两次,但由于Set数据结构的去重能力,最终jobQueue中只会有一项,即当前副作用函数。
类似地,flushJob也会同步且连续执行两次,但由于isFlushing标志的存在,实际上flushJob函数在一个事件循环内只会执行一次,即在微任务队列内执行一次。
当微任务队列开始执行时,就会遍历jobQueue并执行里面存储的副作用函数。由于此时jobQueue队列内只有一个副作用函数,所以只会执行一次,并且当它执行时,字段obj.foo的值已经是3了,这样我们就实现了期望的输出。
再跑一遍完整流程,来看一下单测结果,确保新增代码不影响以往功能。
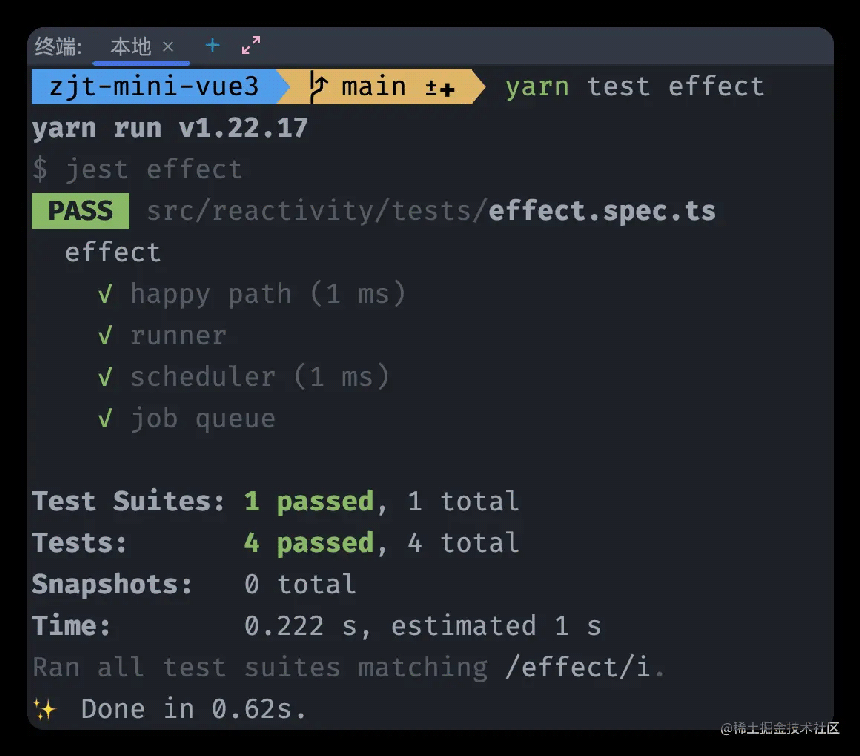
测试结束完以后,由于job queue是一个实际案例单测,所以我们将其抽离到examples下面的testCase里,建立jobQueue.spec.ts。
五、结语
可能你已经注意到了,这个功能点类似于在Vue.js中连续多次修改响应式数据但只会触发一次更新,实际上Vue.js内部实现了一个更加完善的调度器,思路与上文介绍的相同。
此外,综合前面的这些内容,我们就可以实现Vue.js中一个非常重要且非常有特色的能力:computed计算属性,这个就后面再慢慢实现吧...
以上就是vue3调度器effect的scheduler功能实现详解的详细内容,更多关于vue3调度器effect scheduler的资料请关注我们其它相关文章!
相关推荐
-
Vue3系列之effect和ReactiveEffect track trigger源码解析
目录 引言 一.ReactiveEffect 1. 相关的全局变量 2. class 声明 3. cleanupEffect 二.effect 函数 1. 相关ts类型 2. 函数声明 3. stop函数 三.track 依赖收集 1. track 2. createDep 3. trackEffects 4. 小结 四.trigger 1. triggerEffect 2. triggerEffects 3. trigger 五.小结 1. 依赖收集 2. 触发更新 引言 介绍几个API的时候
-

useEffect理解React、Vue设计理念的不同
目录 引言 Vue与React的差异 useEffect会越来越复杂 总结 引言 我们知道,React发布Hooks后,带来了业界一波Hooks热.很多框架(比如Vue Composition API.Solid.js)都借鉴了Hooks的模式. 但是,即使这些框架都借鉴了Hooks,但由于框架作者的理念不同,发展方向也逐渐不同. 比如,在Vue Composition API中,对标React useEffect API的是watchEffect,在Vue文档中,有一小段内容介绍他的用法: 而
-
vue转react useEffect的全过程
目录 vue转react useEffect useEffect的第二个参数 useEffect的使用 useEffect清除 vue2转战React Hooks实践 开发思路上 代码组织结构上 vue转react useEffect useEffect用于处理组件中的effect,通常用于请求数据,事件处理,订阅等相关操作. useEffect的第二个参数 1.当useEffect没有第二个参数时 通过这个例子可以看到useEffect没有第二个参数时不停的在调用 2.当useEffect第二
-
详解Vue3中的watch侦听器和watchEffect高级侦听器
目录 1watch侦听器 2watchEffect高级侦听器 清除副作用:就是在触发监听之前会调用一个函数可以处理你的逻辑例如防抖 停止跟踪 watchEffect 返回一个函数 调用之后将停止更新 1watch侦听器 watch 需要侦听特定的数据源,并在单独的回调函数中执行副作用 watch第一个参数监听源 watch第二个参数回调函数cb(newVal,oldVal) watch第三个参数一个options配置项是一个对 { immediate:true //是否立即调用一次 deep:t
-
深入理解Vue3里的EffectScope
Vue 3.2 版本引入了新的 Effect scope API,使用 effectScope 创建一个 effect 作用域,可以捕获其中所创建的响应式副作用 (即计算属性和侦听器),这样捕获到的副作用可以一起处理.使用 getCurrentScope 返回当前活跃的 effect 作用域.使用 onScopeDispose 在当前活跃的 effect 作用域上注册一个处理回调函数.当相关的 effect 作用域停止时会调用这个回调函数. const scope = effectScope()
-
vue3中的响应式原理-effect
目录 effect的基本实现 依赖收集 触发更新 分支切换与cleanup 停止effect 调度执行 深度代理 总结 effect的基本实现 export let activeEffect = undefined;// 当前正在执行的effect class ReactiveEffect { active = true; deps = []; // 收集effect中使用到的属性 parent = undefined; constructor(public fn
-
vue3调度器effect的scheduler功能实现详解
目录 一.调度执行 二.单元测试 三.代码实现 四.回归实现 五.结语 一.调度执行 说到scheduler,也就是vue3的调度器,可能大家还不是特别明白调度器的是什么,先大概介绍一下. 可调度性是响应式系统非常重要的特性.首先我们要明确什么是可调度性.所谓可调度性,指的是当trigger 动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机.次数以及方式. 有了调度函数,我们在trigger函数中触发副作用函数重新执行时,就可以直接调用用户传递的调度器函数,从而把控制权交给用户. 举
-
vue3使用自定义指令实现el dialog拖拽功能示例详解
目录 实现el-dialog的拖拽功能 通过自定义指令实现拖拽功能 实现拖拽功能 使用方式 实现el-dialog的拖拽功能 这里指的是 element-plus 的el-dialog组件,一开始该组件并没有实现拖拽的功能,当然现在可以通过设置属性的方式实现拖拽. 自带的拖拽功能非常严谨,拖拽时判断是否拖拽出窗口,如果出去了会阻止拖拽. 如果自带的拖拽功能可以满足需求的话,可以跳过本文. 通过自定义指令实现拖拽功能 因为要自己操作dom(设置事件),所以感觉还是使用自定义指令更直接一些,而且对原
-
Bottle框架中的装饰器类和描述符应用详解
最近在阅读Python微型Web框架Bottle的源码,发现了Bottle中有一个既是装饰器类又是描述符的有趣实现.刚好这两个点是Python比较的难理解,又混合在一起,让代码有些晦涩难懂.但理解代码之后不由得为Python语言的简洁优美赞叹.所以把相关知识和想法稍微整理,以供分享. 正文 Bottle是Python的一个微型Web框架,所有代码都在一个bottle.py文件中,只依赖标准库实现,兼容Python 2和Python 3,而且最新的稳定版0.12代码也只有3700行左右.虽然小,但
-
Spring框架实现AOP添加日志记录功能过程详解
这篇文章主要介绍了Spring框架实现AOP添加日志记录功能过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 需求,在调用业务方法的时候,在被调用的业务方法的前面和后面添加上日志记录功能 整体架构: 日志处理类: package aop; import java.util.Arrays; import org.apache.log4j.Logger; import org.aspectj.lang.JoinPoint; //日志处理类 增
-
Java中SSM框架实现增删改查功能代码详解
记录一下自己第一次整合smm框架的步骤. 参考博客和网站有:我没有三颗心脏 How2J学习网站 1.数据库使用的是mySql,首先创建数据库ssm1,并创建表student create database ssm1; use ssm1; CREATE TABLE student( id int(11) NOT NULL AUTO_INCREMENT, student_id int(11) NOT NULL UNIQUE, name varchar(255) NOT NULL, age int(1
-
Spring Boot常用功能Profile详解
入口 相关逻辑的入口是listener类:ConfigFileApplicationListener,当容器广播器触发ApplicationEnvironmentPreparedEvent事件时,ConfigFileApplicationListener会收到广播器的通知,进而执行onApplicationEnvironmentPreparedEvent方法 入口处代码: @Override public void onApplicationEvent(ApplicationEvent even
-
Vue3 diff算法之双端diff算法详解
目录 双端Diff算法 双端比较的原理 简单Diff的不足 双端Diff介绍 Diff流程 第一次diff 第二次diff 第三次diff 第四次diff 双端Diff的优势 非理想情况的处理方式 添加新元素 移除不存在得节点 双端Diff完整代码 双端Diff算法 双端Diff在可以解决更多简单Diff算法处理不了的场景,且比简单Diff算法性能更好.本篇是以简单Diff算法的案例来展开的,不过没有了解简单Diff算法直接看双端Diff算法也是可以看明白的. 双端比较的原理 引用简单Diff算
-
Python Flask前端自动登录功能实现详解
目录 引言 1. 登录时 2. 定义全局拦截器 引言 在已有的网站中,几乎所有的网站都已经实现了 自动登录 所谓自动登录,其实就是在你登录后,然后关闭浏览器,接着再启动浏览器重新进入刚刚的网站时,无需自己再次登录.更准确的说,在一段时间内,无需自己再次登录 思路:其实所谓的自动登录,到最后的后端逻辑,和你正常的登录逻辑是一样的,也是判断用户名和密码是否正确.只是我们要省略让用户再次输入用户名和密码的步骤,那么肯定就要将用户名和密码存储在一个地方.当检测到用户再次进入时,看看是否满足可以自动登录的
-
mui上拉加载功能实例详解
最近在做移动端的项目,用到了mui的上拉加载,整理如下: 1.需要引入的css.js <link rel="stylesheet" href="common/mui/css/mui.min.css" rel="external nofollow" > <script src="js/jquery-3.2.0.min.js"></script> <script src="com
-
SQL Server 2016 Alwayson新增功能图文详解
概述 SQLServer2016发布版本到现在已有一年多的时间了,目前最新的稳定版本是SP1版本.接下来就开看看2016在Alwyson上做了哪些改进,记得之前我在写2014Alwayson的时候提到过几个需要改进的问题在2016上已经做了改进. 一.自动故障转移副本数量 在2016之前的版本自动故障转移副本最多只能配置2个副本,在2016上变成了3个. 说明:自动故障转移增加到三个副本影响并不是很大不是非常的重要,多增加一个故障转移副本也意味着你的作业也需要多维护一个副本.重要程度(一般).