从一个爬虫开始ChatGPT的编程秀
目录
- 思考问题域
- 用ChatGPT写一个爬虫
- 1. 先写一个框架
- 2. 在这个框架上,开发爬虫
- 3. 回到任务1的问题域
- 4. 最后回到具体的爬虫代码
- 回顾一下,我们做了什么,得到了什么?
思考问题域
我要写一个爬虫,把ChatGPT上我的数据都爬下来,首先想想我们的问题域,我想到几个问题:
- 不能用HTTP请求去爬,如果我直接
- 用HTTP请求去抓的话,一个我要花太多精力在登录上了,而我的数据又不多,另一个,现在都是单页引用,你HTTP爬下来的根本就不对啊。
- 所以最好是自动化测试的那种方式,启动浏览器去爬。
- 但是我又不能保证一次把代码写成功,反复登录的话,会被网站封号,就几个数据,不值当的。
所以总的来说我需要一个这样的流程:
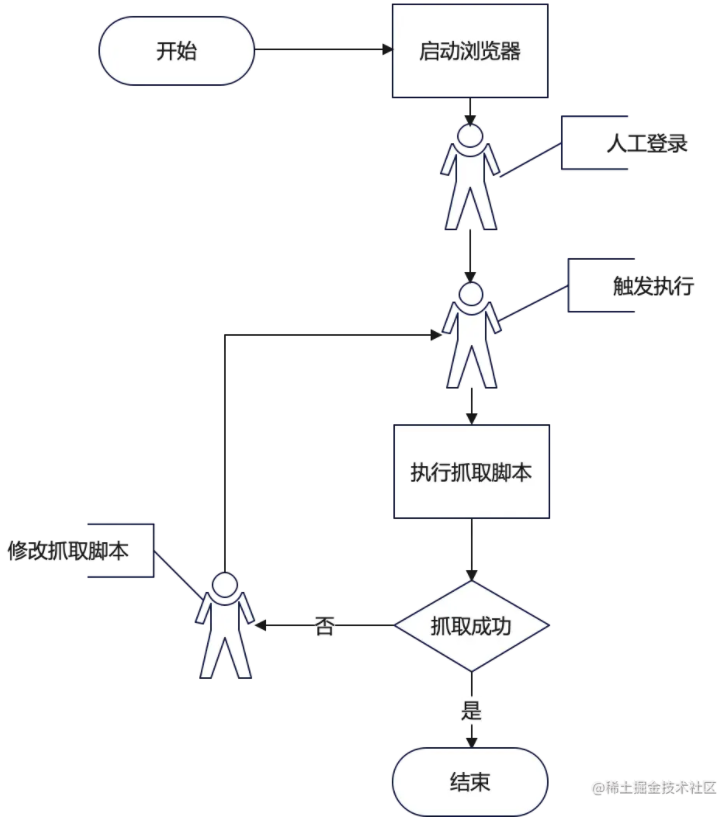
从流程上我们是不是可以看出,这个流程跟我们用WebConsole试验一段代码的过程很像?
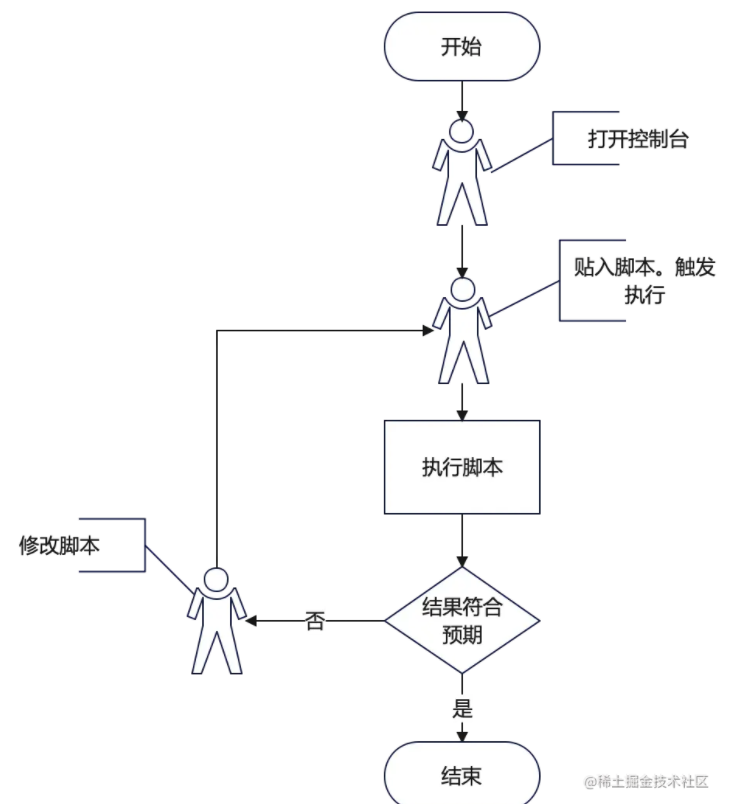
从这种相似性可以看出,我需要一个类似WebConsole的东西来实现我要的效果,这个东西学名叫REPL(Read–eval–print loop),不过你不知道这个名字也无所谓,不影响。
而且还不止,我需要从文件读入我的代码,毕竟没有代码高亮,我可写不好程序。从文件读入的话,我就可以用vscode给我提供代码高亮,这岂不是美滋滋。
想到这,如果是以前,我已经一个头两个大了,我只是想抓点东西,你让我搞个REPL,这玩意听着就不科学,我一天就晚上有一个小时的时间写点代码,这玩意太复杂了,乍一看也不是我业余时间能写出来的。
但是现在,我们有了ChatGPT,那么我接下来可以用ChatGPT开始写,简单做一个任务分解:
- 写一个框架,可以最大限度的帮我们提高开发效率
- 在这个框架上,一个场景一个场景的开发爬虫
用ChatGPT写一个爬虫
1. 先写一个框架
首先,我可能不知道这个东西叫REPL,但是我知道控制台,那我就这么问:
如何用nodejs做一个命令行交互控制台,执行输入的js代码
然后我就得到了下面的代码:
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '>> '
});
rl.prompt();
rl.on('line', (line) => {
try {
const result = eval(line);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('close', () => {
console.log('Exiting...');
process.exit(0);
});
但是这个代码还不够我用的,我需要文件输入,所以我可以问:
如果是读入文件作为输入呢?
然后我得到了下面的代码:
const fs = require('fs');
const fileName = 'path/to/file.js';
const fileContent = fs.readFileSync(fileName, 'utf8');
try {
const result = eval(fileContent);
console.log(result);
} catch (err) {
console.error(err);
}
第一反应,这个不是async/await模式调用的呀,我后面代码写起来会很麻烦,于是我就说:
我要用fs/promises库实现上面逻辑怎么写呢?
然后我就得到了下面的代码:
const fs = require('fs').promises;
const fileName = 'path/to/file.js';
const fileContent = await fs.readFile(fileName, 'utf8');
try {
const result = eval(fileContent);
console.log(result);
} catch (err) {
console.error(err);
}
这个点算是令我满意了,但马上我又意识到不对劲,我需要执行完之后 hang 在那里等待下一次输入的,他这执行完就退出了,于是我又改进了的问题:
我要实现的效果是,启动后在命令行里打印一个“>”然后等待输入,我敲击回车,程序就会读入代码中写死的目标文件,并执行其中的js,然后重新打印一个“>“等待下一次输入,无限循环。
然后我得到了下面的代码:
const readline = require('readline');
const fs = require('fs').promises;
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '> '
});
let filePath = 'path/to/target/file.js';
rl.prompt();
rl.on('line', async () => {
try {
const fileContent = await fs.readFile(filePath, 'utf8');
const result = eval(fileContent);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('SIGINT', () => {
console.log('Exiting...');
rl.close();
process.exit(0);
});
注意,我再第一次的时候忘记了写”无限循环“,所以他写的代码就只执行两次,仔细一看,确实这样实现也符合我说的逻辑,他没有猜测我要无限循环,所以在使用的时候要注意,有时候没得到你想要的结果可能是你没说清楚。
那么看起来到此为止就差不多了,没想到也不复杂。那我测试一下。
- 我建立了一个下面的工程结构:
.
├── index.js
└── input
└── input.js
- 把文件名写死为
input/input.js - 执行
node index.js
彩蛋:其中有一次执行的代码在后续执行发现错误,
发现下面错误:
```
/Volumes/MyLab/chatgpt-show/crawler/workspace/v1/index.js:15
const input = await new Promise(resolve => rl.question('', resolve));
^^^^^
SyntaxError: await is only valid in async functions and the top level bodies of modules
at internalCompileFunction (node:internal/vm:73:18)
at wrapSafe (node:internal/modules/cjs/loader:1149:20)
at Module._compile (node:internal/modules/cjs/loader:1190:27)
at Module._extensions..js (node:internal/modules/cjs/loader:1280:10)
at Module.load (node:internal/modules/cjs/loader:1089:32)
at Module._load (node:internal/modules/cjs/loader:930:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:81:12)
at node:internal/main/run_main_module:23:47
```
原来是await用错了,不过没关系,直接拷给他:
上面的代码执行报错: SyntaxError: await is only valid in async functions and the top level bodies of modules
于是得到了修改后的代码
2. 在这个框架上,开发爬虫
那么接下来,我可以试着抓取一下列表了,这部分GPT3.5就不能胜任了,我切换到GPT4,然后问:
我用puppeteer打开一个网页,可以直接用document DOM API操作,然后返回数据,请抓取这个网页的列表,HTML如下:
.....
下面省略是openAI的页面代码,但是呢,因为他太大了,我不得不手动做了点删减,比如我列表很长,我就减到只剩3个元素,其他无关的元素的代码我都删掉。
经过几次询问,他给出了我代码:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('你的网址'); // 将'你的网址'替换为您要打开的页面的实际URL
const list = await page.evaluate(() => {
const anchors = document.querySelectorAll('a');
const items = [];
for (const anchor of anchors) {
const itemText = anchor.querySelector('div.flex-1.text-ellipsis.max-h-5.overflow-hidden.break-all.relative');
if (itemText) {
const itemTitle = itemText.textContent.trim();
const itemLink = anchor.href;
items.push({ title: itemTitle, link: itemLink });
}
}
return items;
});
console.log(list);
await browser.close();
})();
3. 回到任务1的问题域
真到执行的时候又发现新问题,这个puppeteer我希望他一直开着,就不能在input.js里启动,我需要在REPL代码里就执行,所以我需要稍微修改下代码,我说:
我需要在控制台启动的时候用puppeteer启动一个浏览器,然后每次回车可以让文件中的代码可以通过puppeteer访问启动的这个浏览器
然后得到了代码:
async function main() {
const readline = require('readline');
const fs = require('fs').promises;
const puppeteer = require('puppeteer-core');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '> '
});
const browser = await puppeteer.launch({
executablePath: '/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome'
});
let filePath = 'path/to/target/file.js';
rl.prompt();
async function executeWithBrowser(browser) {
const fileContent = await fs.readFile(filePath, 'utf8');
return eval(`async function (browser) { ${fileContent} }`)(browser);
}
rl.on('line', async () => {
try {
const result = await executeWithBrowser(browser);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('SIGINT', async () => {
console.log('Exiting...');
await browser.close();
rl.close();
process.exit(0);
});
}
main();
这代码还是不令我满意,我又接连问了下面几个问题:
- 我需要browser是GUI可见的
- 把path/to/target/file.js 改为 input/input.js
- 我需要在进入input/input.js之前直接启动一个page,里直接访问page而不是browser
- 这行代码: return eval(
async function (page) { ${fileContent} })(page);
报错:
xxxx 能不能不用eval? - 报错: /Volumes/MyLab/chatgpt-show/crawler/workspace/v1/index.js:11
const browser = await puppeteer.launch({
^^^^^
SyntaxError: await is only valid in async functions and the top level bodies of modules
最后得到了我可以执行的代码。不过实际执行中还出现了防抓机器人的问题,经过一些列的查找解决了这个问题,为了突出重点,这里就不贴解决过程了,最终代码如下:
const readline = require('readline');
const fs = require('fs').promises;
// const puppeteer = require('puppeteer-core');
const puppeteer = require('puppeteer-extra')
// add stealth plugin and use defaults (all evasion techniques)
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: '> '
});
const browser = await puppeteer.launch({
executablePath: '/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome',
headless: false,
args: ['--no-sandbox', '--disable-setuid-sandbox', '--disable-web-security']
});
const page = await browser.newPage();
let filePath = 'input/input.js';
rl.prompt();
async function executeWithPage(page) {
const fileContent = await fs.readFile(filePath, 'utf8');
const func = new Function('page', fileContent);
return func(page);
}
rl.on('line', async () => {
try {
const result = await executeWithPage(page);
console.log(result);
} catch (err) {
console.error(err);
}
rl.prompt();
});
rl.on('SIGINT', async () => {
console.log('Exiting...');
await browser.close();
rl.close();
process.exit(0);
});
})();
4. 最后回到具体的爬虫代码
而既然浏览器一直开着了,那我们需要执行的代码其实只有两个了:
- goto_chatgpt.js
(async () => {
await page.goto('https://chat.openai.com/chat/');
})();
- fetch_list.js
(async () => {
const list = await page.evaluate(() => {
const anchors = document.querySelectorAll('a');
const items = [];
for (const anchor of anchors) {
const itemText = anchor.querySelector('div.flex-1.text-ellipsis.max-h-5.overflow-hidden.break-all.relative');
if (itemText) {
const itemTitle = itemText.textContent.trim();
const itemLink = anchor.href;
items.push({ title: itemTitle, link: itemLink });
}
}
return items;
});
console.log(list);
})();
当然实际上fetch_list.js有点问题,因为openai做了防抓程序,我们可能很难搞到列表项的链接,不过这个也不难,我们用名字匹配挨个点就好了嘛,反正也不多。
比如下面这样:
(async () => {
const targetTitle = 'AI Replacing Human';
const targetSelector = await page.evaluateHandle((targetTitle) => {
const anchors = document.querySelectorAll('a');
for (const anchor of anchors) {
const itemText = anchor.querySelector('div.flex-1.text-ellipsis.max-h-5.overflow-hidden.break-all.relative');
if (itemText && itemText.textContent.trim() === targetTitle) {
return anchor;
}
}
return null;
}, targetTitle);
if (targetSelector) {
const box = await targetSelector.boundingBox();
await page.mouse.click(box.x + box.width / 2, box.y + box.height / 2);
console.log(`Clicked the link with title "${targetTitle}".`);
} else {
console.log(`No link found with title "${targetTitle}".`);
}
})();
说句题外话,上面的代码很有意思,似乎它为了防止点某个具体元素不管用,竟然点击了一个区域。
接下来如果我们想备份我们的每一个thread就可以在这个基础上,让ChatGPT继续给我们写实现完成即可,这里就不继续展开了,大家可以自己完成。
回顾一下,我们做了什么,得到了什么?
- 首先,我们对问题域做了分析,把目标网站和工作者我本人以及时间限制等约束都纳入了问题域进行了分析,得到了一个方案,然后通过类比发现我们的方案其实就是做一个有特定上下文的REPL,然后用这个REPL再去干具体的事。
- 接着,我们基于这个方案做了任务分解,粗略分成了做一个REPL和实现具体的抓取代码两部分。
- 接着我们靠ChatGPT把些任务实现,在实现的过程中,我们发现自己对问题域的细节了解不够,于是我们又迭代了我们的任务列表。可以说方案没有大的变化,实现上做了很多调整。
最终,我们就靠ChatGPT把这个REPL给做了出来,为了写一个这样的小功能,我们做了个框架,颇有点为了这点醋才包的这顿饺子的味道了。这要是在以前的时代,是一个巨大的浪费,但其实先做一个框架的思路在ChatGPT时代应该成为一种习惯,它会从两个方面带来好处:
- 可以降低输入的文本数量,避免ChatGPT犯错。因为很多人都知道,ChatGPT可以快速写出一些小程序,但是长一点的总是会出错,很多人到这里就放弃了,但其实,我们会发现如果我们能把问题分解到它恰好擅长的领域我们就可以最大限度的利用它的优势,规避它的劣势。人类历史上,蒸汽机车发明的时候,它肯定不如马耐颠,但为了充分理由他的优势,人们为它铺了铁轨。直到今天为了发挥机动车的效力,我们还是要修路铺轨,但是我们并不觉得有什么不对,从这个角度来讲,我们也不该只盯着ChatGPT的缺点看,扬长避短才是正道。
- 缩短反馈环,提高效率。从整体效率角度来讲,只有反馈环的缩短才是真正提高了效率,某一步的快速完成并不真正提高效率。所谓反馈环的缩短在我们的上下文里就是”我想到怎么编码完成任务 -> 编码 -> 测试 -> 得知代码执行失败->我又想到怎么编码完成任务"的这个循环,我们不能假设代码编写一次成功,所以这个环越短,我们的效率就越高。在这个例子里我想到了我不能一次写对,所以我就先做了REPL,这就是所谓磨刀不误砍柴工。但是道理大家都懂,在有ChatGPT之前,磨刀这个事他总是误砍柴工的,但是在今天,你可以用几个问题就得到一个趁手的工具,开始你的工作,所以不要着急冲进去工作,先做个工具可能是新时代的好习惯。
下一篇,我们将进入这样一个场景:我基于这个框架,我写了很多爬虫代码,我该怎么组织和管理这些代码呢?我需不需要一个精妙设计的内部框架和规范来组织我的代码呢?
相关推荐
-
ChatGPT编程秀之跨越认知边界
目录 作者说 碰到了认知边界 跨越认知边界 总结一下 作者说 最近要忙了,日更的日子要到头了.后面每一篇讲的点就小一点吧,大的点等后面有空了再写.大家见谅. 碰到了认知边界 我的有的朋友跟我说,用ChatGPT编程需要你至少要跟他对等水平,因为现阶段我们还不能做到完全不需要关心它写出来的代码,当你要读懂它写的代码的时候,就必须能力对等.还有的朋友跟我说,ChatGPT的不能超过你的认知水平,你的认知水平的上限决定了它的表现,比如你认知水平不行,导致自己不能分解任务的时候,那么你用ChatGPT也
-
ChatGPT如何写好Prompt编程示例详解
目录 引言 好的 prompt 具有的设计原则 编写良好prompt的四种基础模式 编写一个合格的prompt的要点 让AI扮演角色 明确提供要执行的任务 给出完成任务的步骤 围绕任务提供上下文 陈述具体目标,给出具体要求 要求格式化输出 明确指定语言风格 让AI站在人物的角度,而非上帝视角 马上给出具体的样例 小结 引言 现在已经产生了一种新职业:Prompt Engineer(提示指令工程师),可见 Prompt 是多么重要,且编写不易. ChatGPT的产出,一半决定于它的实力,一半决定于
-
ChatGPT编程秀之最小元素的设计示例详解
目录 膨胀的野心与现实的窘境 新时代,新思路 总结一下 膨胀的野心与现实的窘境 上一节随着我能抓openai的列表之后,我的野心开始膨胀,既然我们写了一个框架,可以开始写面向各网站的爬虫了,为什么只面向ChatGPT呢?几乎所有的平台都是这么个模式,一个列表,然后逐个抓取.那我能不能把这个能力泛化呢?可不可以设计一套机制,让所有的抓取功能都变得很简单呢?我抽取一系列的基础能力,而不管抓哪个网站只需要复用这些能力就可以快速的开发出爬虫.公司内的各种平台都是这么想的对吧? 那么我们就需要进行设计建模
-
适合面向ChatGPT编程的架构示例详解
目录 新的需求 领域知识 架构设计 管道架构 分层架构 类分层神经网络的架构 总结一下 新的需求 我们前面爬虫的需求呢,有些平台说因为引起争议,所以不让发,好吧,那我们换个需求,本来那个例子也不好扩展了.最近AI画图也是比较火的,那么我们来试试做个程序帮我们生成AI画图的prompt. 首先讲一下AI话题的prompt的关键要素,大部分的AI画图都是有一个个由逗号分割的关键字,也叫subject,类似下面这样: a cute cat, smile, running, look_at_viewer
-
ChatGPT前端编程秀之别拿编程语言不当语言
目录 TDD第一步就卡住了 破门而入,针对性反馈 总结一下 TDD第一步就卡住了 写完小工具,这一篇回来我们接着写我们的程序.再看一眼我们的程序运行视图: 带着TDD思路,我进入了 ejs_and_yaml_dsl_loader 这个模块,这块因为我切的不是很好,所以这代码有点难写,不过没关系,正好我们实际工作大部分的场景都是这样的.看看我们在这里能玩出点什么来. 那么这次的需求呢是这个样子的,我们需要把ejs模版引擎渲染出的yaml转换为json,那么我们这个功能会非常复杂,所以我们没有以上来
-

Python的爬虫框架scrapy用21行代码写一个爬虫
开发说明 开发环境:Pycharm 2017.1(目前最新) 开发框架:Scrapy 1.3.3(目前最新) 目标 爬取线报网站,并把内容保存到items.json里 页面分析 根据上图我们可以发现内容都在类为post这个div里 下面放出post的代码 <div class="post"> <!-- baidu_tc block_begin: {"action": "DELETE"} --> <div class=
-
python 写的一个爬虫程序源码
写爬虫是一项复杂.枯噪.反复的工作,考虑的问题包括采集效率.链路异常处理.数据质量(与站点编码规范关系很大)等.整理自己写一个爬虫程序,单台服务器可以启用1~8个实例同时采集,然后将数据入库. #-*- coding:utf-8 -*- #!/usr/local/bin/python import sys, time, os,string import mechanize import urlparse from BeautifulSoup import BeautifulSoup import
-
一步步教你用python的scrapy编写一个爬虫
介绍 本文将介绍我是如何在python爬虫里面一步一步踩坑,然后慢慢走出来的,期间碰到的所有问题我都会详细说明,让大家以后碰到这些问题时能够快速确定问题的来源,后面的代码只是贴出了核心代码,更详细的代码暂时没有贴出来. 流程一览 首先我是想爬某个网站上面的所有文章内容,但是由于之前没有做过爬虫(也不知道到底那个语言最方便),所以这里想到了是用python来做一个爬虫(毕竟人家的名字都带有爬虫的含义
-
利用Swift实现一个响应式编程库
前言 整个2017年我完全使用 Swift 进行开发了.使用 Swift 进行开发是一个很愉快的体验,我已经完全不想再去碰 OC 了.最近想做一个响应式编程的库,所以就把它拿来分享一下. 在缺乏好的资源的情况下,学习响应式编程成为痛苦.我开始学的时候,做死地找各种教程.结果发现有用的只是极少部分,而且这少部分也只是表面上的东西,对于整个体系结构的理解也起不了多大的作用. Reactive Programing 说到响应式编程,ReactiveCocoa 和 RxSwift 可以说是目前 iOS
-
一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据.专业的解释:百度百科 分析爬虫需求 确定目标 爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称.豆瓣评分.导演.编剧.主演.类型.制片国家/地区.语言.上映日期.片长.IMDb链接等信息. 分析目标 1.借助工具分析目标网页 首先,我们打开豆瓣电影·热门电影,会发现页面总共20部
-
python爬虫项目设置一个中断重连的程序的实现
做爬虫项目时,我们需要考虑一个爬虫在爬取时会遇到各种情况(网站验证,ip封禁),导致爬虫程序中断,这时我们已经爬取过一些数据,再次爬取时这些数据就可以忽略,所以我们需要在爬虫项目中设置一个中断重连的功能,使其在重新运行时从之前断掉的位置重新爬取数据. 实现该功能有很多种做法,我自己就有好几种思路,但是真要自己写出来就要费很大的功夫,下面我就把自己好不容易拼凑出来的代码展示出来吧. 首先是来介绍代码的思路: 将要爬取的网站连接存在一个数组new_urls中,爬取一个网址就将它移入另一个数组old_
-
使用ChatGPT来自动化Python任务
目录 1.概述 2.内容 2.1 使用ChatGPT来绘制线性回归 2.2 使用Python给微信发信息 2.3 使用Python发送电子邮件 2.4 使用Python开发一个爬虫程序 3.总结 1.概述 最近,比较火热的ChatGPT很受欢迎.今天,笔者为大家来介绍一下ChatGPT能做哪些事情. 2.内容 ChatGPT是一款由OpenAI开发的专门从事对话的AI聊天机器人.它的目标是让AI系统更加自然的与之交互,但它也可以在我们编写代码的时候提供一些帮助. 2.1 使用ChatGPT来绘制
-
如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求
网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的UserAgent. 所以通过UserAgent判断请求的发起者是否是搜索引擎爬虫(蜘蛛)的方式是不靠谱的,更靠谱的方法是通过请求者的ip对应的host主机名是否是搜索引擎自己家的host的方式来判断. 要获得ip的host,在windows下可以通过nslookup