正则表达式之捕获组/非捕获组介绍
捕获组
语法:
字符 |
描述 |
示例 |
|
(pattern) |
匹配pattern并捕获结果,自动设置组号。 |
(abc)+d 匹配abcd或者abcabcd |
|
(?<name>pattern) 或 (?'name'pattern) |
匹配pattern并捕获结果,设置name为组名。 | |
|
\num |
对捕获组的反向引用。其中 num 是一个正整数。 |
(\w)(\w)\2\1 匹配abba |
|
\k< name > 或 \k' name ' |
对命名捕获组的反向引用。其中 name 是捕获组名。 |
(?<group>\w)abc\k<group> 匹配xabcx |
例如:
(\d{4})-(\d{2}-(\d{2}))
1 1 2 3 32
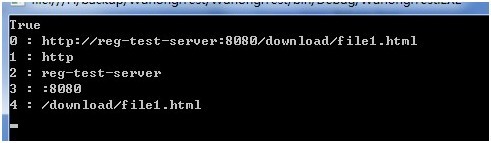
以下是用程序处理捕获组的示例,对一个Url地址进行解析,并显示所有捕获组。
可以看到按顺序设置的捕获组号。
Regex.Match方法
代码如下:
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式
string regex = @"(\w+):\/\/([^/:]+)(:\d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//匹配正则表达式
Match m = regUrl.Match(source);
Console.WriteLine(m.Success);
if (m.Success)
{
//捕获组存放在Match.Groups集合中,索引值从1开始,索引0处为匹配的整个字符串值
//按“组号 : 捕获内容”的格式显示
for (int i = 0; i < m.Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1}", i, m.Groups[i]));
}
}
Console.ReadLine();
}
}
}
也可以自己指定子表达式的组名。这样在表达式或程序中可以直接引用组名,当然也可以继续使用组号。但如果正则表达式中同时存在普通捕获组和命名捕获组,那么捕获组的编号就要特别注意,编号的规则是先对普通捕获组进行编号,再对命名捕获组进行编号。
例如:
(\d{4})-(?<date>\d{2}-(\d{2}))
1 1 3 2 23
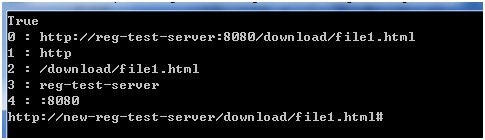
下面在程序中处理命名捕获组,显示混合规则生成的组号,并利用捕获组的内容对源字符串进行替换。
可以看到先对普通捕获组进行编号,再对命名捕获组编号。
Regex.Replace方法
代码如下:
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式,对其中两个分组命名
string regex = @"(\w+):\/\/(?<server>[^/:]+)(?<port>:\d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//匹配正则表达式
Match m = regUrl.Match(source);
Console.WriteLine(m.Success);
if (m.Success)
{
//捕获组存放在Match.Groups集合中,索引值从1开始,索引0处为匹配的整个字符串值
//按“组号 : 捕获内容”的格式显示
for (int i = 0; i < m.Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1}", i, m.Groups[i]));
}
}
//替换字符串
//“$组号”引用捕获组的内容。
//需要特别注意的是“$组号”后不能跟数字形式的字符串,如果出现此情况,需要使用命名捕获组,引用格式“${组名}”
string replacement = string.Format("$1://{0}{1}$2", "new-reg-test-server", "");
string result = regUrl.Replace(source, replacement);
Console.WriteLine(result);
Console.ReadLine();
}
}
}
非捕获组
语法:
字符 |
描述 |
示例 |
|
(?:pattern) |
匹配pattern,但不捕获匹配结果。 |
'industr(?:y|ies) 匹配'industry'或'industries'。 |
|
(?=pattern) |
零宽度正向预查,不捕获匹配结果。 |
'Windows (?=95|98|NT|2000)' 匹配 "Windows2000" 中的 "Windows" 不匹配 "Windows3.1" 中的 "Windows"。 |
|
(?!pattern) |
零宽度负向预查,不捕获匹配结果。 |
'Windows (?!95|98|NT|2000)' 匹配 "Windows3.1" 中的 "Windows" 不匹配 "Windows2000" 中的 "Windows"。 |
|
(?<=pattern) |
零宽度正向回查,不捕获匹配结果。 |
'2000 (?<=Office|Word|Excel)' 匹配 " Office2000" 中的 "2000" 不匹配 "Windows2000" 中的 "2000"。 |
|
(?<!pattern) |
零宽度负向回查,不捕获匹配结果。 |
'2000 (?<!Office|Word|Excel)' 匹配 " Windows2000" 中的 "2000" 不匹配 " Office2000" 中的 "2000"。 |
非捕获组只匹配结果,但不捕获结果,也不会分配组号,当然也不能在表达式和程序中做进一步处理。
首先(?:pattern)与(pattern)不同之处只是在于不捕获结果。
接下来的四个非捕获组用于匹配pattern(或者不匹配pattern)位置之前(或之后)的内容。匹配的结果不包括pattern。
例如:
(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内的内容。如:<div>hello</div>之中的hello,匹配结果不包括前缀<div>和后缀</div>。
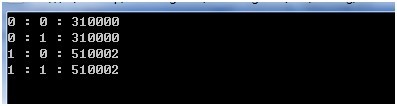
下面是程序中非捕获组的示例,用来提取邮编。
可以看到反向回查和反向预查都没有被捕获。
Regex.Matches方法
代码如下:
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "有6组数字:010001,100,21000,310000,4100011,510002,把邮编挑出来。";
//正则式
string regex = @"(?<!\d)([1-9]\d{5})(?!\d)";
Regex regUrl = new Regex(regex);
//获取所有匹配
MatchCollection mList = regUrl.Matches(source);
for (int j = 0; j < mList.Count; j++)
{
//显示每个分组,可以看到每个分组都只有组号为1的项,反向回查和反向预查没有被捕获
for (int i = 0; i < mList[j].Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1} : {2}", j, i, mList[j].Groups[i]));
}
}
Console.ReadLine();
}
}
}
注释
语法:
字符 |
描述 |
示例 |
|
(?#comment) |
comment是注释,不对正则表达式的处理产生任何影响 |
2[0-4]\d(?#200-249)|25[0-5](?#250-255)|1?\d\d?(?#0-199) 匹配0-255的整数 |
相关推荐
-
JS正则表达式之非捕获分组用法实例分析
本文实例讲述了JS正则表达式非捕获分组用法.分享给大家供大家参考,具体如下: 最近在看JsonSQL的时候,通过源码中的一段正则表达式,了解到了什么是非捕获分组以及它的使用场景.在js中,正常的捕获分组格式是(XX),非捕获分组格式为(?:XX).我们先从正则表达式数量词说起,如果我们要求字符b至少出现一次,可以使用正则/b+/:如果要求ab至少出现一次,那么必需使用/(ab)+/,不能用/ab+/.也就是说,如果想对多个字符使用数量词,必需要用圆括号. var str = "a1***ab1c
-
JS正则表达式获取分组内容的方法详解
支持多次匹配的方式: 复制代码 代码如下: var testStr = "now test001 test002"; var re = /test(\d+)/ig; var r = ""; while(r = re.exec(testStr)) { alert(r[0] + " " + r[1]); } 此外也可以用testStr.match(re),但是这样的话就不能有g的选项,而且只能得到第一个匹配. 另外备忘
-

正则表达式、分组、子匹配(子模式)、非捕获子匹配(子模式)
前面我们知道正则表达式有很多元字符表示匹配次数(量词),都是可以重复匹配前面出现的单个字符次数.有时候,我们可能需要匹配一组多个字符一起出现的次数.这个时候,我们需要分组了.就是用小括号来括起这些字符,指定子表达式(也叫做分组).然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作.这个时候,可以把括号中一组字符,看作一个整体了. 分组模式举例说明 如:查找字符串中,连续出现多个win字符串的字符.可以这样完 <?php $str = "this is win wi
-
javascript正则表达式中分组详解
之前写了一篇关于正则新手入门的文章,本以为对正则表达式相对比较了解 但是今天我又遇到了一个坑,可能是自己不够细心的原因吧,今天就着重和大家分享一下javascript正则表达式中的分组.如果你对JS正则表达式不够理解 可以点击这里了解更多. 分组在正则中用的还是比较广的,我所理解的分组 就是一对括号() ,每一对括号 就代表了一个分组, 分组可以分为: 捕获性分组 非捕获性分组 捕获性分组 捕获性分组会在 比如 match exec这样的函数中以第二项,第三项的形式得到相应分组的结果.先来看一个
-
浅谈JavaScript正则表达式-非捕获性分组
非捕获性分组定义子表达式可以作为整体被修饰但是子表达式匹配结果不会被存储. 非捕获性分组通过将子表达式放在"?:"符号后. str = "img1.jpg,img2.jpg,img3.bmp"; reg = /(?:\w*)(?=\.gif)/; arr_m = str.match(reg);//arr_m = ["img1","img2"] 你在期待什么还是在等待什么?你选择了什么还是只想浮徒一生?茫茫人海,真的需要那么回眸
-
JavaScript正则表达式的分组匹配详解
分组 下面的正则表达式可以匹配kidkidkid: /kidkidkid/ 而另一种更优雅的写法是: /(kid){3}/ 这里由圆括号包裹的一个小整体称为分组. 候选 一个分组中,可以有多个候选表达式,用|分隔: var reg = /I love (him|her|it)/; reg.test('I love him') // true reg.test('I love her') // true reg.test('I love it') // true reg.test('I love
-
js正则表达式之前瞻后顾与非捕获分组
目录 前瞻后顾与捕获分组的结合使用 捕获分组与非捕获分组 前瞻.后顾与负前瞻.负后顾 总结 前瞻后顾与捕获分组的结合使用 在现实的应用场景中,捕获分组或非捕获分组通常被限制在前瞻后顾条件内,举例来说,对数字12345678格式化,结果为12,345,678.其正则实现如下: let formatSum = '12345678'.replace(/\B(?=(?:\d{3})+(?!\d))/g, ',') 捕获分组与非捕获分组 为了理解前瞻与后顾,首先要先理解捕获分组与非捕获分组 在js中, (
-
正则表达式之捕获组/非捕获组介绍
捕获组 语法: 字符 描述 示例 (pattern) 匹配pattern并捕获结果,自动设置组号. (abc)+d 匹配abcd或者abcabcd (?<name>pattern) 或 (?'name'pattern) 匹配pattern并捕获结果,设置name为组名. \num 对捕获组的反向引用.其中 num 是一个正整数. (\w)(\w)\2\1 匹配abba \k< name > 或 \k' name ' 对命名捕获组的反向引用.其中 name 是捕获组名. (?<
-
PHP之正则表达式捕获组与非捕获组(详解)
在项目开发过程中正则表示经常会用到,可以说会正则表达式是每个程序员最基本的要求,初学者在刚接触正则表达式都感到很吃力.最近看到一位朋友的博客写的<PHP正则表达式>获益颇多,在章节对通配符以及捕获数据非常感兴趣.这两章节刚好也涉及到了正则表达式的捕获组和非捕获组的内容,以此来分析这方面的内容 我们知道,在正则表达式下(x) 表示匹配'x'并记录匹配的值.这只是比较通俗的说法,甚至说这是不严谨的说法,只有()捕获组形式才会记录匹配的值.非捕获组则只匹配,不记录. 捕获组: (pattern) 这
-
PHP正则表达式之捕获组与非捕获组
今天遇到一个正则匹配的问题,忽然翻到有捕获组的概念,手册上也是一略而过,百度时无意翻到C#和Java中有对正则捕获组的特殊用法,搜索关键词有PHP时竟然没有相关内容,自己试了一下,发现在PHP中也是可行的,于是总结一下,分享的同时也希望有大神和细心的学习者找到我理解中出现的问题. 什么是捕获组 捕获组语法: 字符 描述 示例 (pattern) 匹配pattern并捕获结果,自动设置组号. (abc)+d 匹配abcd或者abcabcd (?<name>pattern) 或 (?'name'
-
浅谈PHP正则中的捕获组与非捕获组
今天遇到一个正则匹配的问题,忽然翻到有捕获组的概念,手册上也是一略而过,百度时无意翻到C#和Java中有对正则捕获组的特殊用法,搜索关键词有PHP时竟然没有相关内容,自己试了一下,发现在PHP中也是可行的,于是总结一下,分享的同时也希望有大神和细心的学习者找到我理解中出现的问题. 什么是捕获组 我们先看一下PHP的正则匹配函数 int preg_match ( string $pattern , string $subject [, array &$matches [, int $flags =
-
Python正则表达式中的量词符号与组问题小结
正则表达式中的符号 例子 | 是或的关系,只要存在就会被捕获 匹配到的数据只按字符串顺序返回,而不是按照匹配规则返回 In [18]: data = 'insane@loafer.com' In [19]: print(re.findall('insane|com|loafer', data)) ['insane', 'loafer', 'com'] ^ 等同于 \A In [20]: print(re.findall('^insane',data)) ['insane'] In [21]: p
-
PHP 正则表达式效率 贪婪、非贪婪与回溯分析(推荐)
先扫盲一下什么是正则表达式的贪婪,什么是非贪婪?或者说什么是匹配优先量词,什么是忽略优先量词? 好吧,我也不知道概念是什么,来举个例子吧. 某同学想过滤之间的内容,那是这么写正则以及程序的. $str = preg_replace('%<script>.+?</script>%i','',$str);//非贪婪 看起来,好像没什么问题,其实则不然.若 $str = '<script<script>alert(document.cookie)</script&