pytorch如何定义新的自动求导函数
目录
- pytorch定义新的自动求导函数
- pytorch自动求导与逻辑回归
- 自动求导
- 逻辑回归
- 总结
pytorch定义新的自动求导函数
在pytorch中想自定义求导函数,通过实现torch.autograd.Function并重写forward和backward函数,来定义自己的自动求导运算。参考官网上的demo:传送门
直接上代码,定义一个ReLu来实现自动求导
import torch
class MyRelu(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
# 我们使用ctx上下文对象来缓存,以便在反向传播中使用,ctx存储时候只能存tensor
# 在正向传播中,我们接收一个上下文对象ctx和一个包含输入的张量input;
# 我们必须返回一个包含输出的张量,
# input.clamp(min = 0)表示讲输入中所有值范围规定到0到正无穷,如input=[-1,-2,3]则被转换成input=[0,0,3]
ctx.save_for_backward(input)
# 返回几个值,backward接受参数则包含ctx和这几个值
return input.clamp(min = 0)
@staticmethod
def backward(ctx, grad_output):
# 把ctx中存储的input张量读取出来
input, = ctx.saved_tensors
# grad_output存放反向传播过程中的梯度
grad_input = grad_output.clone()
# 这儿就是ReLu的规则,表示原始数据小于0,则relu为0,因此对应索引的梯度都置为0
grad_input[input < 0] = 0
return grad_input
进行输入数据并测试
dtype = torch.float
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 使用torch的generator定义随机数,注意产生的是cpu随机数还是gpu随机数
generator=torch.Generator(device).manual_seed(42)
# N是Batch, H is hidden dimension,
# D_in is input dimension;D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in, device=device, dtype=dtype,generator=generator)
y = torch.randn(N, D_out, device=device, dtype=dtype, generator=generator)
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True, generator=generator)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True, generator=generator)
learning_rate = 1e-6
for t in range(500):
relu = MyRelu.apply
# 使用函数传入参数运算
y_pred = relu(x.mm(w1)).mm(w2)
# 计算损失
loss = (y_pred - y).pow(2).sum()
if t % 100 == 99:
print(t, loss.item())
# 传播
loss.backward()
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()
pytorch自动求导与逻辑回归
自动求导

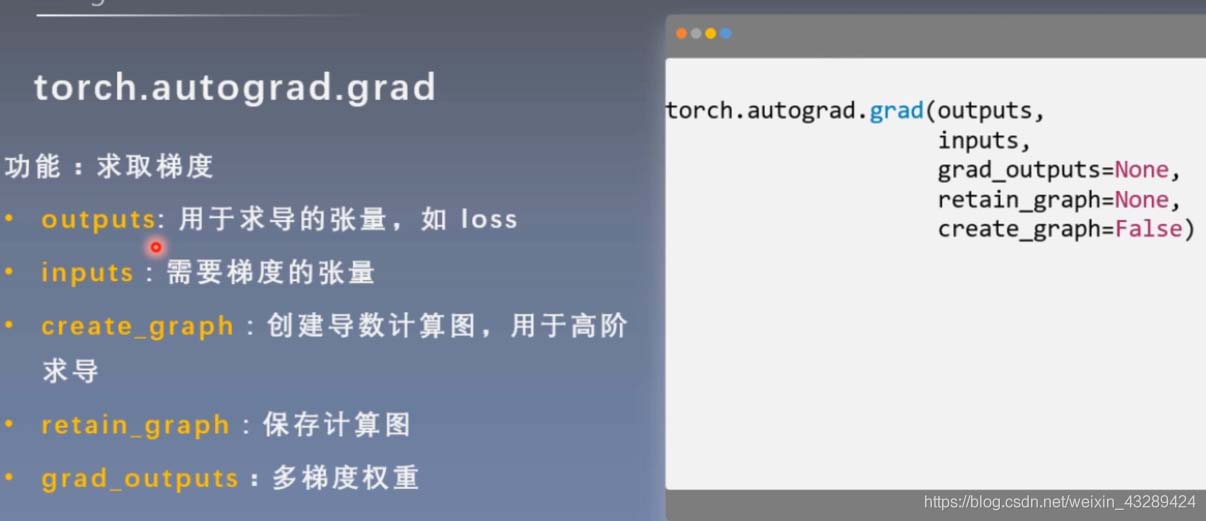
retain_graph设为True,可以进行两次反向传播

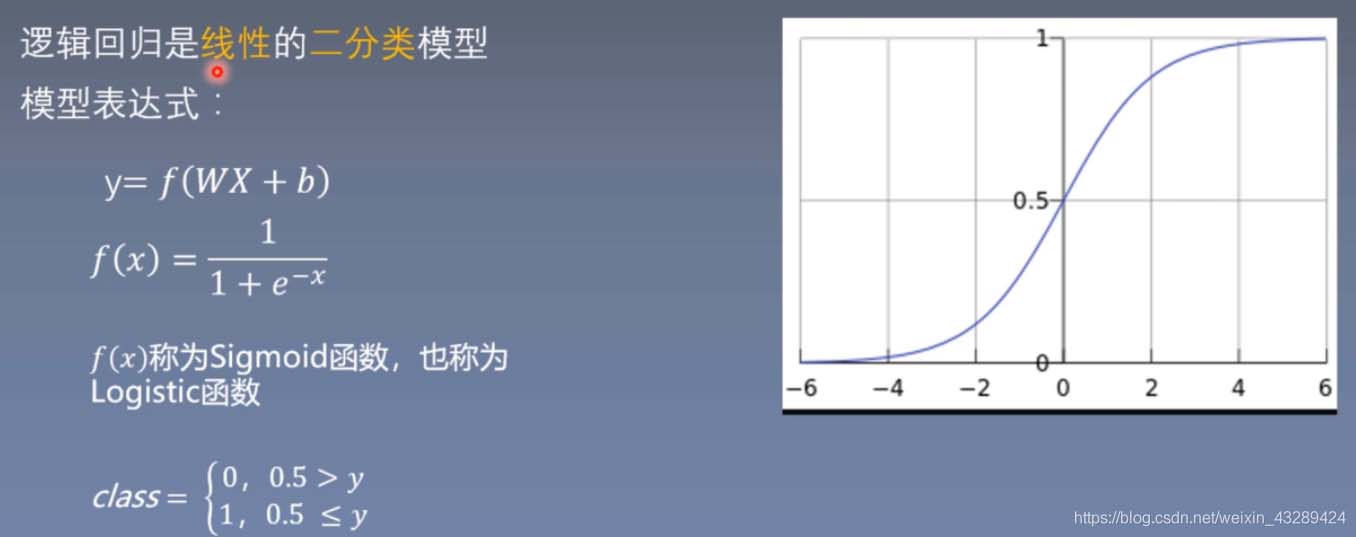
逻辑回归

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
torch.manual_seed(10)
#========生成数据=============
sample_nums = 100
mean_value = 1.7
bias = 1
n_data = torch.ones(sample_nums,2)
x0 = torch.normal(mean_value*n_data,1)+bias#类别0数据
y0 = torch.zeros(sample_nums)#类别0标签
x1 = torch.normal(-mean_value*n_data,1)+bias#类别1数据
y1 = torch.ones(sample_nums)#类别1标签
train_x = torch.cat((x0,x1),0)
train_y = torch.cat((y0,y1),0)
#==========选择模型===========
class LR(nn.Module):
def __init__(self):
super(LR,self).__init__()
self.features = nn.Linear(2,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.features(x)
x = self.sigmoid(x)
return x
lr_net = LR()#实例化逻辑回归模型
#==============选择损失函数===============
loss_fn = nn.BCELoss()
#==============选择优化器=================
lr = 0.01
optimizer = torch.optim.SGD(lr_net.parameters(),lr = lr,momentum=0.9)
#===============模型训练==================
for iteration in range(1000):
#前向传播
y_pred = lr_net(train_x)#模型的输出
#计算loss
loss = loss_fn(y_pred.squeeze(),train_y)
#反向传播
loss.backward()
#更新参数
optimizer.step()
#绘图
if iteration % 20 == 0:
mask = y_pred.ge(0.5).float().squeeze() #以0.5分类
correct = (mask==train_y).sum()#正确预测样本数
acc = correct.item()/train_y.size(0)#分类准确率
plt.scatter(x0.data.numpy()[:,0],x0.data.numpy()[:,1],c='r',label='class0')
plt.scatter(x1.data.numpy()[:,0],x1.data.numpy()[:,1],c='b',label='class1')
w0,w1 = lr_net.features.weight[0]
w0,w1 = float(w0.item()),float(w1.item())
plot_b = float(lr_net.features.bias[0].item())
plot_x = np.arange(-6,6,0.1)
plot_y = (-w0*plot_x-plot_b)/w1
plt.xlim(-5,7)
plt.ylim(-7,7)
plt.plot(plot_x,plot_y)
plt.text(-5,5,'Loss=%.4f'%loss.data.numpy(),fontdict={'size':20,'color':'red'})
plt.title('Iteration:{}\nw0:{:.2f} w1:{:.2f} b{:.2f} accuracy:{:2%}'.format(iteration,w0,w1,plot_b,acc))
plt.legend()
plt.show()
plt.pause(0.5)
if acc > 0.99:
break
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
浅谈Pytorch中的自动求导函数backward()所需参数的含义
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿. 对标量自动求导 首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的. import torch from torch.autograd import Variable a = Variable(torch.Te
-
关于PyTorch 自动求导机制详解
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile.它们都允许从梯度计算中精细地排除子图,并可以提高效率. requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度.相反,只有所有输入都不需要梯度,输出才不需要.如果其中所有的变量都不需要梯度进行,后向计算不会在子图中执行. >>> x = Variable(torch.randn(5, 5)) >>> y = Variable(torch.rand
-

Pytorch自动求导函数详解流程以及与TensorFlow搭建网络的对比
一.定义新的自动求导函数 在底层,每个原始的自动求导运算实际上是两个在Tensor上运行的函数.其中,forward函数计算从输入Tensor获得的输出Tensors.而backward函数接收输出,Tensors对于某个标量值得梯度,并且计算输入Tensors相对于该相同标量值得梯度. 在Pytorch中,可以容易地通过定义torch.autograd.Function的子类实现forward和backward函数,来定义自动求导函数.之后就可以使用这个新的自动梯度运算符了.我们可以通过构造一
-
pytorch如何定义新的自动求导函数
目录 pytorch定义新的自动求导函数 pytorch自动求导与逻辑回归 自动求导 逻辑回归 总结 pytorch定义新的自动求导函数 在pytorch中想自定义求导函数,通过实现torch.autograd.Function并重写forward和backward函数,来定义自己的自动求导运算.参考官网上的demo:传送门 直接上代码,定义一个ReLu来实现自动求导 import torch class MyRelu(torch.autograd.Function): @staticmetho
-
在 pytorch 中实现计算图和自动求导
前言: 今天聊一聊 pytorch 的计算图和自动求导,我们先从一个简单例子来看,下面是一个简单函数建立了 yy 和 xx 之间的关系 然后我们结点和边形式表示上面公式: 上面的式子可以用图的形式表达,接下来我们用 torch 来计算 x 导数,首先我们创建一个 tensor 并且将其requires_grad设置为True表示随后反向传播会对其进行求导. x = torch.tensor(3.,requires_grad=True) 然后写出 y = 3*x**2 + 4*x + 2 y.ba
-
Pytorch中的自动求梯度机制和Variable类实例
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性:Varibale的Tensor本身的.data,对应Tensor的梯度.grad,以及这个Variable是通过什么方式得到的.grad_fn,根据最新消息,在pytorch0.4更新后,torch和torch.autograd.Variab
-
pytorch中的自定义反向传播,求导实例
pytorch中自定义backward()函数.在图像处理过程中,我们有时候会使用自己定义的算法处理图像,这些算法多是基于numpy或者scipy等包. 那么如何将自定义算法的梯度加入到pytorch的计算图中,能使用Loss.backward()操作自动求导并优化呢.下面的代码展示了这个功能` import torch import numpy as np from PIL import Image from torch.autograd import gradcheck class Bicu
-
pytorch 数据处理:定义自己的数据集合实例
数据处理 版本1 #数据处理 import os import torch from torch.utils import data from PIL import Image import numpy as np #定义自己的数据集合 class DogCat(data.Dataset): def __init__(self,root): #所有图片的绝对路径 imgs=os.listdir(root) self.imgs=[os.path.join(root,k) for k in imgs
-
TensorFlow的自动求导原理分析
原理: TensorFlow使用的求导方法称为自动微分(Automatic Differentiation),它既不是符号求导也不是数值求导,而类似于将两者结合的产物. 最基本的原理就是链式法则,关键思想是在基本操作(op)的水平上应用符号求导,并保持中间结果(grad). 基本操作的符号求导定义在\tensorflow\python\ops\math_grad.py文件中,这个文件中的所有函数都用RegisterGradient装饰器包装了起来,这些函数都接受两个参数op和grad,参数op是
-
Pytorch模型定义与深度学习自查手册
目录 定义神经网络 权重初始化 方法1:net.apply(weights_init) 方法2:在网络初始化的时候进行参数初始化 常用的操作 利用nn.Parameter()设计新的层 nn.Flatten nn.Sequential 常用的层 全连接层nn.Linear() torch.nn.Dropout 卷积torch.nn.ConvNd() 池化 最大池化torch.nn.MaxPoolNd() 均值池化torch.nn.AvgPoolNd() 反池化 最大值反池化nn.MaxUnpoo