mysql 数据备份与恢复使用详解(超完整详细教程)
目录
- 一、前言
- 二、数据备份策略
- 1、全备
- 2、增备
- 3、差异备份
- 三、数据备份类型
- 1、冷备
- 2、热备
- 3、温备
- 四、前置准备
- 五、mysqldump 数据备份命令使用
- 1、命令格式
- 2、案例演示
- 3、其他重要参数选项补充
- 六、mysqldump 数据恢复
- 1、全量恢复
- 2、全量备份中恢复单库
- 3、从某个数据库中恢复单表数据
- 4、使用dump + binlog进行数据恢复
- 七、物理备份
- 八、表的导出与导入
- 1、 使用SELECT…INTO OUTFILE导出文本文件
- 2. 使用mysqldump命令导出文本文件
- 3、 使用mysql命令导出文本文件
一、前言
对一个运行中的线上系统来说,定期对数据库进行备份是非常重要的,备份不仅可以确保数据的局部完整性,一定程度上也为数据安全性提供了保障,设想如果某种极端的场景下,比如磁盘损坏导致某个时间段数据丢失,或者误操作导致数据表数据被删等...
这种情况在现实中可以说无处不在,为了避免数据丢失或损坏带来的巨大损失,有必要对线上系统的数据定期做备份,而备份的直接好处就是,一旦数据需要做恢复的时候就可以利用这些备份数据快速恢复,从而最大程度减少损失。
二、数据备份策略
根据实际的业务需求,经验参考可以据数据规模大小,服务器磁盘容量,大致可分为下面几种:
1、全备
备份完整的数据库,全量数据就是数据库中所有的数据(或某一个库的全部数据);
- 全量备份就是把数据库中所有的数据进行备份;
- mysqldump会取得一个时刻的一致性数据
2、增备
增量数据就是指上一次全量备份数据之后到下一次全备之前数据库所更新的数据,对于mysqldump,binlog就是增量数据;
3、差异备份
- 备份自上一次完全备份后的全部改动和新文件;
- 备份速度较快,恢复速度较快,对磁盘空间有要求;
- 能够更快且简单的恢复(相比较增量);
- 需要最近一次完全备份和最后一次差异备份就能快速恢复;
三、数据备份类型
根据数据备份时对生产系统的影响,可以做如下分类:
1、冷备
停库,停服务,备份
这些备份操作在用户不能访问数据的时候进行,因此无法读取或修改数据。这些脱机备份会阻止执行任何使用数据的行为。这些类型的备份不会干扰正常运行的系统的性能。但是,对于某些应用程序,会无法接受必须在一段较长的时间里锁定或完全阻止用户访问数据。
2、热备
不停库,不停服务,备份,也不会(锁表)阻止用户的写入
这些动态备份在读取或修改数据的过程中进行,很少中断或者不中断传输或处理数据的功能。使用热备份时,系统仍可供读取和修改数据的操作访问。
3、温备
不停库,不停服务,备份,会(锁表) 阻止用户的写入
这些备份在读取数据时进行,但在多数情况下,在进行备份时不能修改数据本身。这种中途备份类型的优点是不必完全锁定最终用户。但其不足之处在于无法在进行备份时修改数据集,这可能使这种类型的备份不适用于某些应用程序。在备份过程中无法修改数据可能产生性能问题。
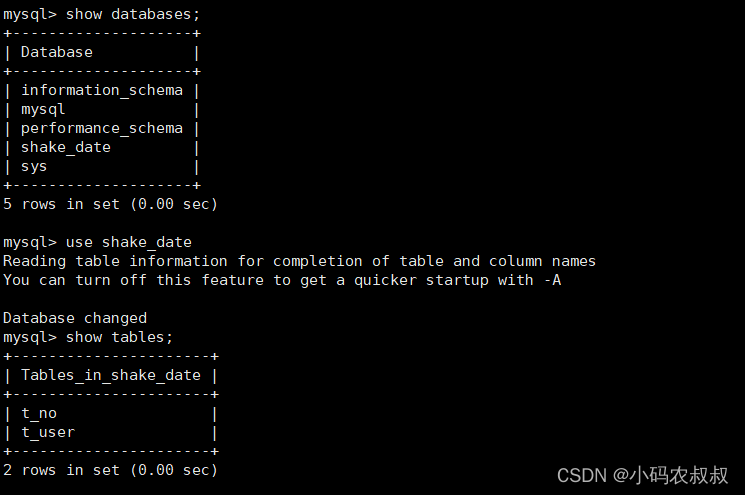
四、前置准备
提前搭建好mysql服务(本文以mysql5.7为例进行说明),并创建一个测试使用的数据库,若干数据表;
五、mysqldump 数据备份命令使用
mysqldump是mysql自带的数据备份命令,使用该命令可以完成数据库,数据表等多种备份策略,下面针对该命令的使用做详细的说明;
1、命令格式
mysqldump [选项] 数据库名 [表名] > 脚本名 或 mysqldump [选项] --数据库名 [选项 表名] > 脚本名 或 mysqldump [选项] --all-databases [选项] > 脚本名
关于选项部分,包含的参数是比较多的,下面列举常用的一些参数选项
参数名 缩写 含义 --host -h 服务器IP地址 --port -P 服务器端口号 --user -u MySQL 用户名 --pasword -p MySQL 密码 --databases 指定要备份的数据库 --all-databases 备份mysql服务器上的所有数据库 --compact 压缩模式,产生更少的输出 --comments 添加注释信息 --complete-insert 输出完成的插入语句 --lock-tables 备份前,锁定所有数据库表 --no-create-db/--no-create-info 禁止生成创建数据库语句 --force 当出现错误时仍然继续备份操作 --default-character-set 指定默认字符集 --add-locks 备份数据库表时锁定数据库表 --no-create-db, ---取消创建数据库sql(默认存在) --no-create-info,---取消创建表sql(默认存在) --no-data ---不导出数据(默认导出) --add-drop-database ---增加删除数据库sql(默认不存在) --skip-add-drop-table ---取消每个数据表创建之前添加drop数据表语句(默认每个表之前存在drop语句) --skip-add-locks ---取消在每个表导出之前增加LOCK TABLES(默认存在锁) --skip-comments ---注释信息(默认存在)
2、案例演示
1)备份全库
mysqldump -uroot -pXXX --all-databases > /usr/local/mysql/full.sql 或者 mysqldump -uroot -pXXX -A > /usr/local/mysql/full.sql

2)备份数据库【一个或多个】
使用 -- databases 或 - B 参数,该参数后面跟数据库名,多个库间中间用空格,如果指定 databases 参数,备份文件中会存在创建数据库的语句,如果不指定参数,则不存在;
mysqldump –u user –h host –p -- databases [ 数据库的名称 1 [ 数据库的名称 2...]] > 备份文件名称 .sql
mysqldump -uroot -pXXX --databases shake_date > /usr/local/mysql/shake_date_01.sql 或者 mysqldump -uroot -pXXX -B shake_date shake_flow > /usr/local/mysql/combine.sql

3)备份数据表
如果业务中不需要对全库做备份,只想备份部分表的时候,
mysqldump –u user –h host –p密码 数据库名 [ 表名 1 [ 表名 2...]] > 备份文件名称 .sql
备份shake_date 下面的t_user表

4)只备份表结构
mysqldump -u用户名 -pXXX --no-data 数据库 数据表名称 > 备份sql文件名.sql
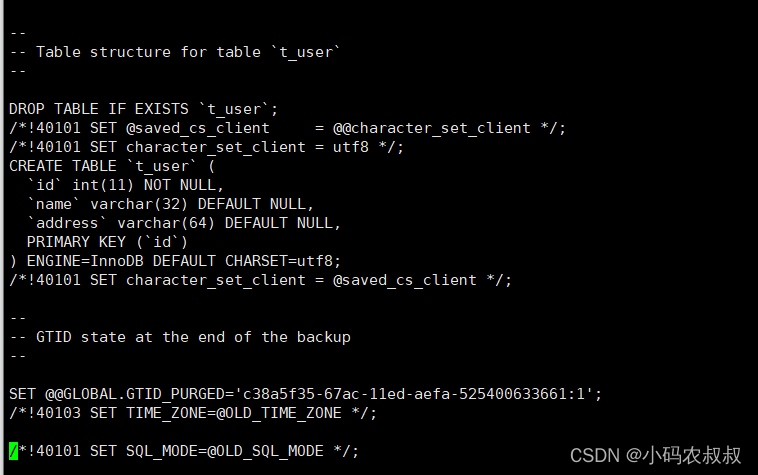
备份shake_date下面的t_user表,只备份表结构
mysqldump -uroot -pXXX --no-data shake_date t_user > /usr/local/mysql/t_user_bk2.sql

可以打开备份的文件检查下,可以发现这里就只剩下表结构;
5)只备份表的部分数据
有时候一张表数据量很大,只需要部分数据,这时就可以使用 --where 选项了,where后面附
带需要满足的条件;
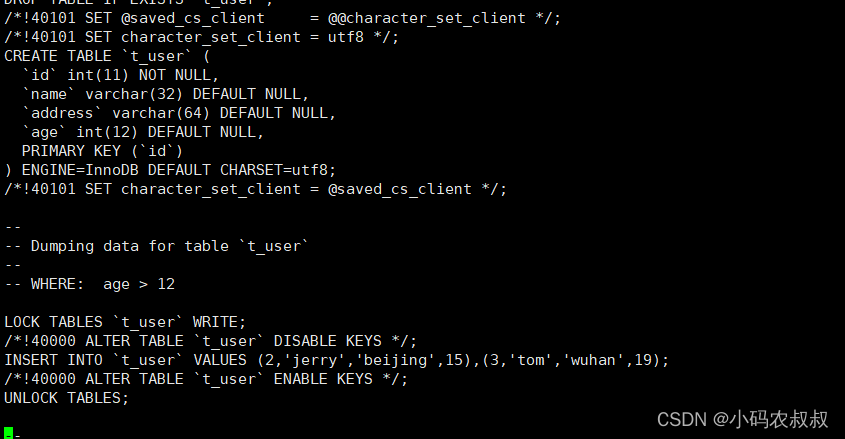
如下,备份t_user表中age大于12岁的用户
mysqldump -uroot -pXXX shake_date t_user --where="age > 12 " > t_user_bk3.sql

6)排除某些表的备份
如果备份某个库,但某些表数据量很大或与业务关联不大,这时候可以考虑排除这些表的备份,适用选项 --ignore-table ;
如下备份shake库下的表,排除t_no这个表
mysqldump -uroot -pXXX shake_date --ignore-table=shake_date.t_no > /usr/local/mysql/t_user_bk5.sql

3、其他重要参数选项补充
在实际生产中,备份数据需要考虑的因素其实更多,考虑的越细致,在后续在数据恢复的时候就越精确,下面列举一些实际生产备份中可能用得上的额外的参数选项;
-R 备份存储过程及函数 --triggers 备份触发器 -E 备份事件 -F 在备份开始时,刷新一个新binlog日志 --master-data=2 以注释的形式,保存备份开始时间点的binlog的状态信息 --single-transaction innodb 存储引擎开启热备(快照备份)功能 --set-gtid-purged=auto
更多的参数,可以通过命令: mysqldump --help 进行查看和学习,每一项都有详细的介绍,可以结合官网一起学习;

在以上罗列的参数中,有下面三个参数选项这里做一下补充说明,也是备份过程中常常会涉及到的
- --master-data;
- --single-transaction;
- --set-gtid-purged;
1)--master-data
可选值 : 1 ,2

通过mysqldump --help 命令可以清楚查看官方对该命令的解释,这里简单说下这个参数的作用
- 加上该选项之后,会在备份的sql中添加并记录备份时间点binlog中的偏移量,利用这个偏移的位置,结合完整的binlog日志,可以全量恢复从这个时间点之前的数据 + 这个时间点之后的数据;
- 在mysql的主从模式中可以用到;
- 该值设置为1或2,在不同的参数值设置时,备份中带来的结果不一样,通常结合--single-transaction;一起使用,可以在备份期间进行锁表,防止期间外部数据的读写造成备份数据的不一致;
以--master-data=2为例进行说明
以注释的形式,保存备份开始时间点的binlog的状态信息
- 在备份时,会自动记录,二进制日志文件名和位置号;
- 自动锁表(FTWRL);
- 如果配合--single-transaction,只对非InnoDB表进行锁表备份,InnoDB表进行“热“”备,实际上是实现快照备份;
2)--single-transaction
innodb 存储引擎开启热备(快照备份)功能
直观上理解,使用该参数,可以在数据备份期间开启类似于事务的操作,这样的话可以避免外部的DDL操作带来备份时的数据上的影响,比如有如下场景,在mysql5.6版本中可能出现的情况:
- 100+G 有MyISAM表,做大批量DML,mysqldump备份数据库出现hang住;
- 3000w表做DDL,改数据类型,备份期间,锁表情况严重;
如果配合上面的master-data可以自动实现加锁
- 不加--single-transaction ,启动所有表的温备份,所有表都锁定;
- 加上--single-transaction , 对innodb进行快照备份, 对非innodb表可以实现自动锁表功能;
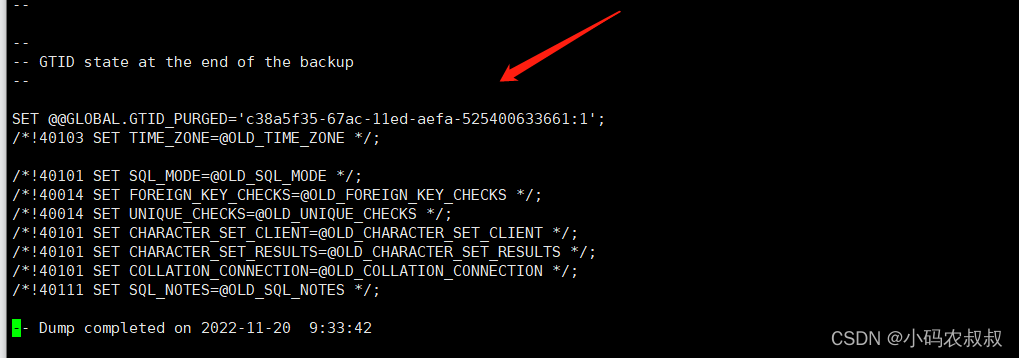
3)--set-gtid-purged
此为默认参数,即使在命令中不写,依旧生效,它的效果是在mysqldump输出的备份文件中生成
SET@@GLOBAL.GTID_PURGED语句;备份文件中的这条语句记录了GTID号, 可选值:auto , on
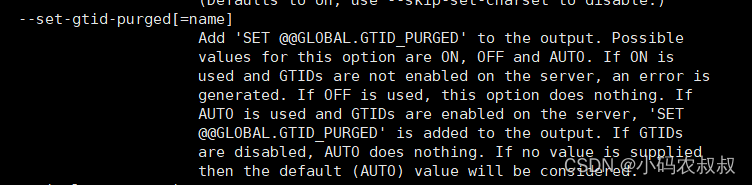
使用场景
- 在构建主从模式时,主库上有许多数据需要先备份出来并恢复到从库上,以此来保持两个库没有差异,然后再去配置主从,在这种场景下,需要将参数设置为 on,对于想要基于GTID实现主从复制的从库来说,从库是基于MASTER_AUTO_POSITION=1自动获取并应用GTID的,因此如果再主库导出的备份文件中没有GTID,那么从库无法自动获取并应用GTID;
- 设为off时,在mysqldump输出中不包含SET@@GLOBAL.GTID_PURGED语句;
4)--max-allowed-packet=#
适当调大该参数,可以避免在备份数据量过大时因数据落盘时数据包过大的备份失败问题
5)-R -E --triggers
备份数据时连同触发器函数等也一同进行备份
操作演示
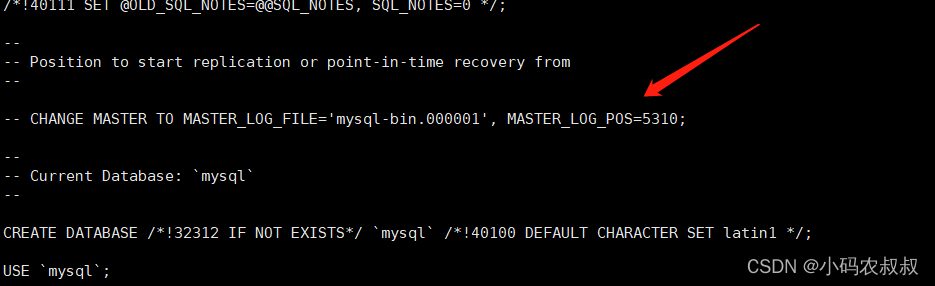
--set-gtid-purged=OFF
mysqldump -uroot -pXXX -A --master-data=2 --single-transaction --set-gtid-purged=OFF >/usr/local/mysql/shake_user_empty.sql

--set-gtid-purged=on
设置该参数之后,最明显的效果就是打开备份脚本文件,可以看到下面的信息,开启这个参数后在构建主从复制的时候会用上
--max-allowed-packet=#
在一些数据量比较大的备份情况下,建议适当的调大该参数
mysqldump -uroot -pXXX -B shake_date -R -E --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF --max-allowed-packet=256M >/usr/local/mysql/shake_full_10.sql
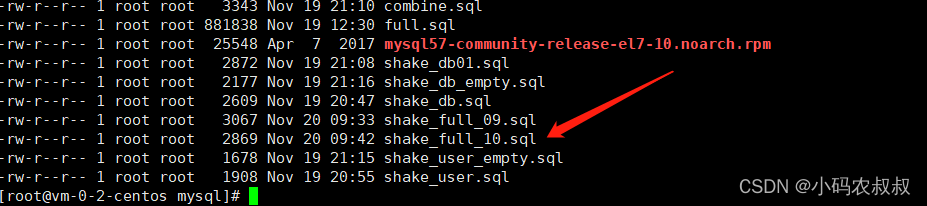
六、mysqldump 数据恢复
使用mysqldump可以对备份的数据进行恢复,基本语法
mysql –u root –p [dbname] < backup .sql
1、全量恢复
如果备份文件中包含了创建数据库的语句,则恢复的时候不需要指定数据库名称
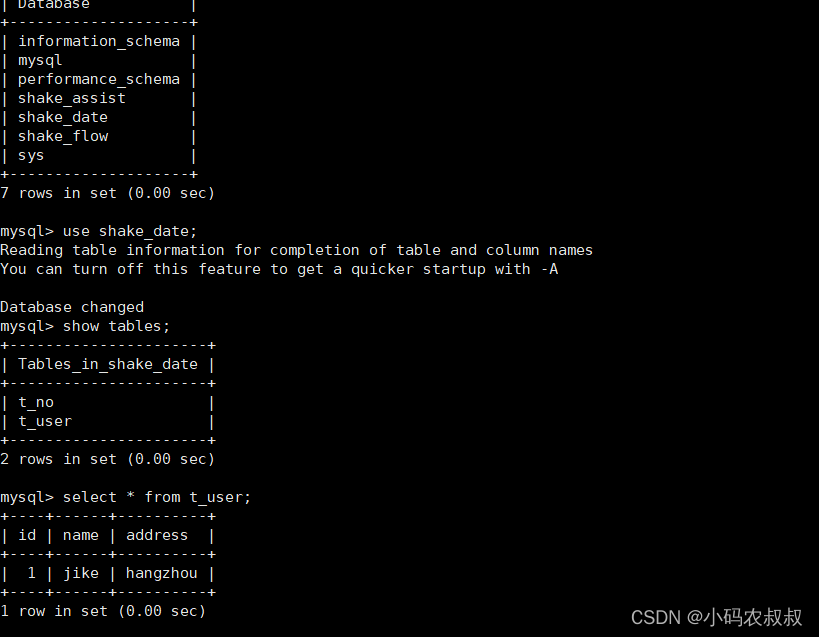
删除shake_date数据库

执行数据恢复,再次查看发现数据就回来了;
mysql -uroot -pXXX < /usr/local/mysql/full.sql
2、全量备份中恢复单库
有整个实例的备份,但只想恢复某个数据库,这时可以从全量备份中分理出单个库的备份,可以参考下面的命令,比如将shake_date数据库从full.sql中分离出来;
sed -n '/^-- Current Database: `shake_date`/,/^-- Current Database: `/p' full.sql> /usr/local/mysql/shake_full.sql

3、从某个数据库中恢复单表数据
这也是一种比较常见的需求了,比如业务中某些表的数据非常重要,优先恢复这些表,就可以用到这个功能,操作步骤如下:
- 用shell语法分离出创建表的语句及插入数据的语句;
- 再依次导出完成数据恢复;
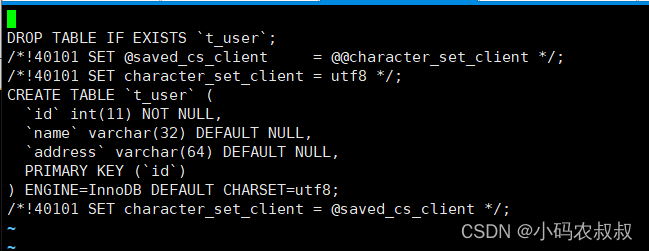
cat shake_full.sql | sed -e '/./{H;$!d;}' -e 'x;/CREATE TABLE `t_user`/!d;q' > t_user_structure.sql
cat shake_full.sql | grep --ignore-case 'insert into `t_user`' > t_user_data.sql
首先,将shake_date库中的t_user表删除
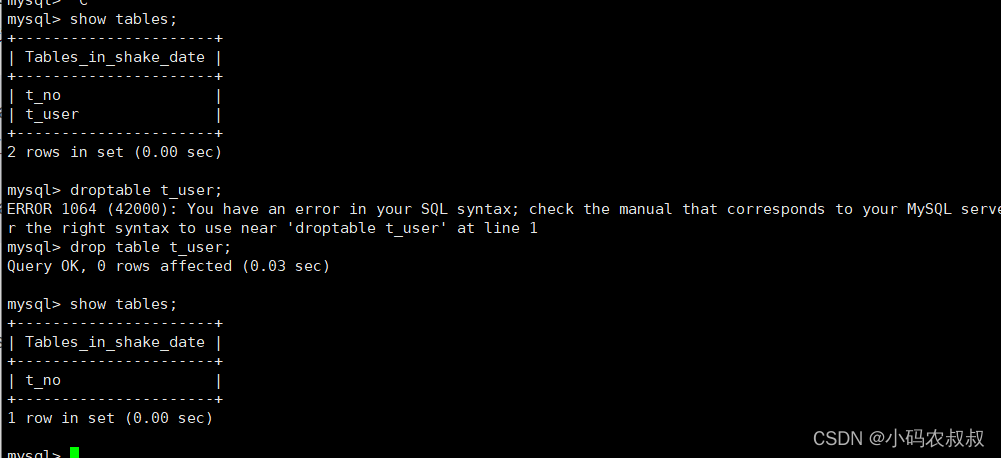
依次执行上面的sql,即建表sql以及insert的数据sql从全库的sql备份中分离出来

可以打开一个看看
然后再执行数据的恢复
source /usr/local/mysql/t_user_structure.sql; source /usr/local/mysql/t_user_data.sql;

4、使用dump + binlog进行数据恢复
下面说一个具体的场景,在生产环境下,假如定期对某个数据库进行全备,比如每周2的晚上进行全备,但现在发生了一件事,即在周三的时候,某位同事不小心将某张表的数据删除了,这该怎么办呢?
可以这么考虑,从周二全备那天来看,备份的数据是截止到那个时间点的全量数据,备份的时候可以将 master-data参数加进去,这样备份出来的数据中就有了那一刻binlog中的数据位置点,而在binlog日志中,记录了完整的操作记录行,那么就可以结合起来对数据进行快速恢复;
操作步骤如下:
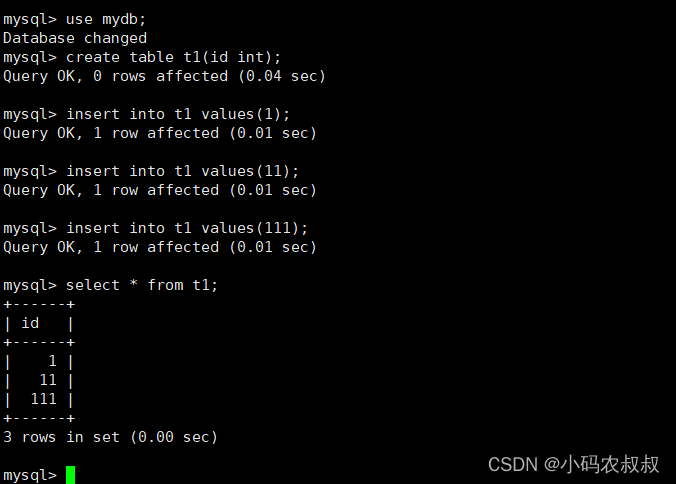
1)创建一个数据库和数据表
给t1表随机插入几条数据

2)模拟周2对当前数据库进行全备
mysqldump -uroot -pXXX --databases mydb --master-data=2 --single-transaction --set-gtid-purged=ON >/usr/local/mysql/mydb.sql
注意:
--master-data=2 这个参数一定要开启,这个参数会记录备份那一刻的位置

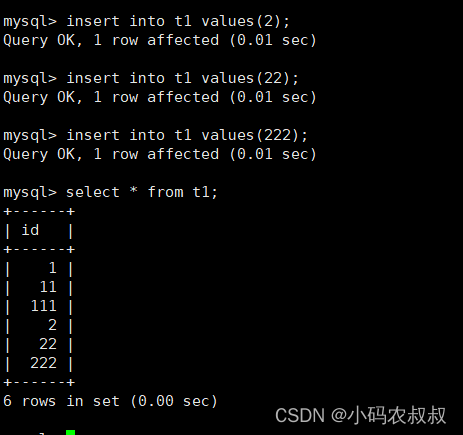
3)模拟周3又对t1表做了相关的数据操作
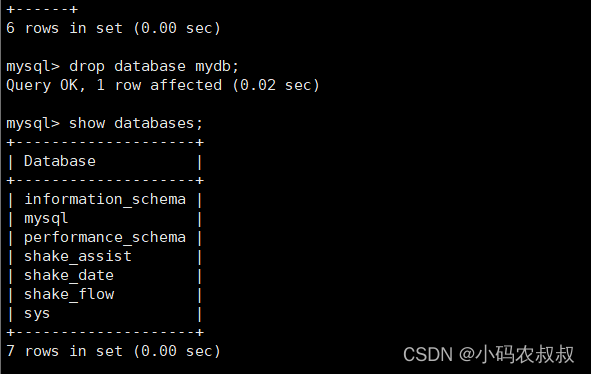
4)模拟周3不小心将数据库删了
5)执行数据恢复
恢复步骤
- 恢复截止到周1的备份数据;
- 寻找binlog的起始位置;
- 根据binlog恢复周1到周2之间的数据;
将备份的sql中的下面的信息定位到,CHANGE 开头的表示在binlog中记录的位置号为4001,这就是说,剩下的待恢复的数据从4001开始截取就可以了;


SET @@GLOBAL.GTID_PURGED='c38a5f35-67ac-11ed-aefa-525400633661:1-16'; CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=4001;
定位到mysql的binlog位置,结合上述的gtid,通过binlog进行恢复,使用下面的命令检查最后删除的位置点;
show binlog events in 'mysql-bin.000002';

在上面我们定位到备份中的sql文件中的gtid是1~16,这里最后drop的时候是20这个位置,则需要截取的那部分就是17 ~ 20;
mysqlbinlog --skip-gtids --include-gtids='c38a5f35-67ac-11ed-aefa-525400633661:17-20' mysql-bin.000002 > /usr/local/mysql/mydb_extend.sql
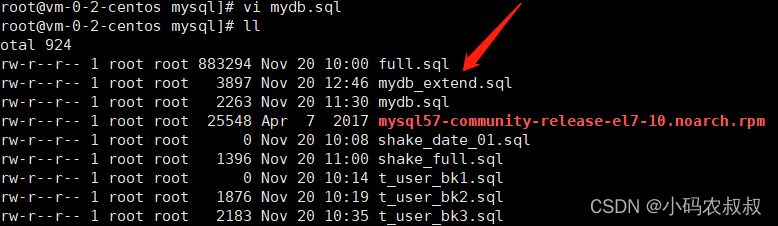
执行恢复

检查全备恢复后的数据,这样就恢复到了周一的数据;

接下来再恢复周2的数据;
source /usr/local/mysql/mydb_extend.sql;
七、物理备份
所谓物理备份,最直接的就是将MySQL中的数据库文件复制出来,这种方式简单粗暴,速度也快,比较省事,
比如在上面创建了一个mydb的数据库,在mysql的数据目录下就存在下面几个数据文件;

但是这种方式并不是特别推荐,一方面在不同的操作系统下,数据目录有所不同,其次,这种备份的操作往往需要停服和锁表,以避免外部的操作给备份数据时带来的不一致的影响,另外,与mysql所使用的数据库引擎也很有关系;
八、表的导出与导入
在一些场景下,直接将数据库数据被分成sql文件可能并不是一个特别好的选择,因为导出来的文件格式不够通用,比如还有其他的数据分析平台需要使用这些数据的话,就比较麻烦了,这时候就可以考虑将数据库以文件的形式导出;
表的导出操作
1、 使用SELECT…INTO OUTFILE导出文本文件
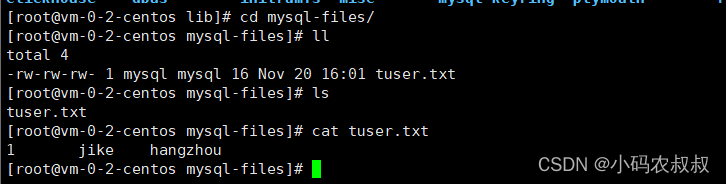
将shake_date库下的t_user表数据导出到文件
SELECT * FROM t_user INTO OUTFILE "/var/lib/mysql-files/tuser.txt";

打开该文件检查下
2. 使用mysqldump命令导出文本文件
使用mysqldump命令将将shake_date数据库中tuser表中的记录导出到文本文件:
mysqldump -uroot -pXXX -T "/var/lib/mysql-files/" shake_date t_user
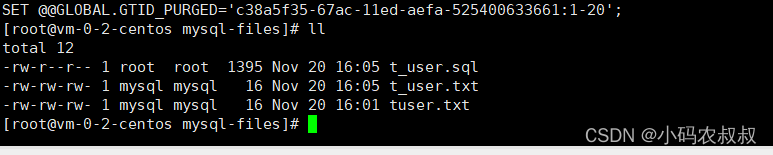
检查下文件
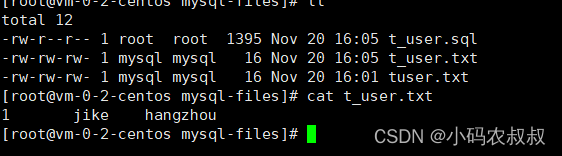
使用mysqldump将shake_date数据库中的t_user表导出到文本文件,使用FIELDS选项,要求字段之间使用逗号“,”间隔,所有字符类型字段值用双引号括起来;
mysqldump -uroot -pXXX -T "/var/lib/mysql-files/" shake_date t_user --fields-terminated-by=',' --fields-optionally-enclosed-by='\"'
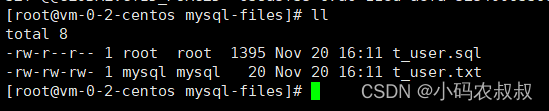
可以检查下txt文件 ,这种格式的数据在很多大数据处理业务场景中是一种比较好的数据格式

3、 使用mysql命令导出文本文件
mysql -uroot -pXXX --execute="SELECT * FROM t_user;" shake_date> "/var/lib/mysql-files/tuser1.txt"
导出的结果格式如下

使用 --veritcal 参数将该条件记录分为多行显示
mysql -uroot -pXXX --vertical --execute="SELECT * FROM t_user;" shake_date > "/var/lib/mysql-files/tuser2.txt"
得到的数据格式如下

使用 --xml参数将数据导出为xml格式
mysql -uroot -pXXX --xml --execute="SELECT * FROM t_user;" shake_date>"/var/lib/mysql-files/tuser3.xml"
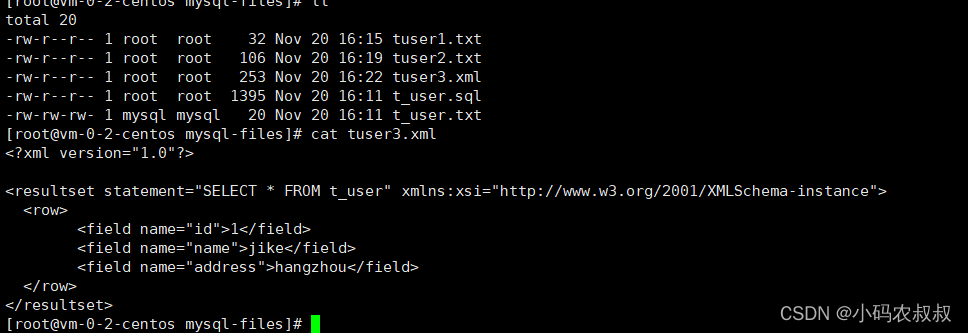
表的导入操作
上面演示了将表以各自类型格式的文件导入,下面再看看如何将不同格式的表的数据进行导入操作;
1. 使用LOAD DATA INFILE方式导入文本文件
使用 SELECT...INTO OUTFILE 将 shake_date 数据库中 t_user 表的记录导出到文本文件
执行下面的语句导出
SELECT * FROM shake_date.t_user INTO OUTFILE '/var/lib/mysql-files/tuser1.txt';

删除t_user表的数据

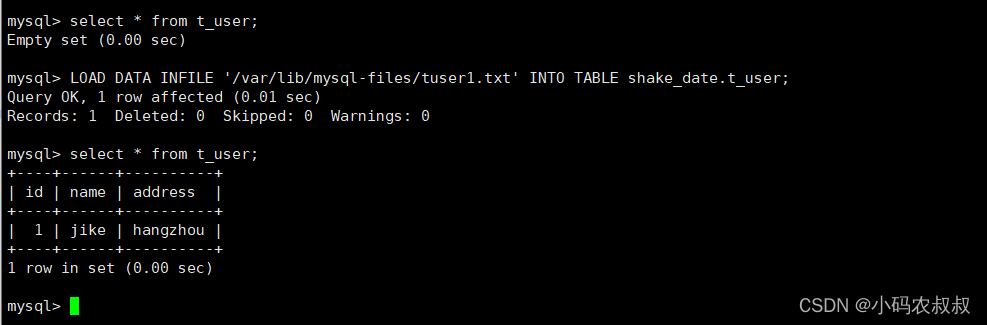
从文本文件tuser1.txt中恢复数据
LOAD DATA INFILE '/var/lib/mysql-files/tuser1.txt' INTO TABLE shake_date.t_user;
2、将上面以逗号分割的文件导入到数据表
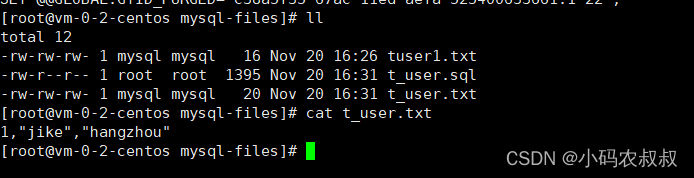
使用如下语句
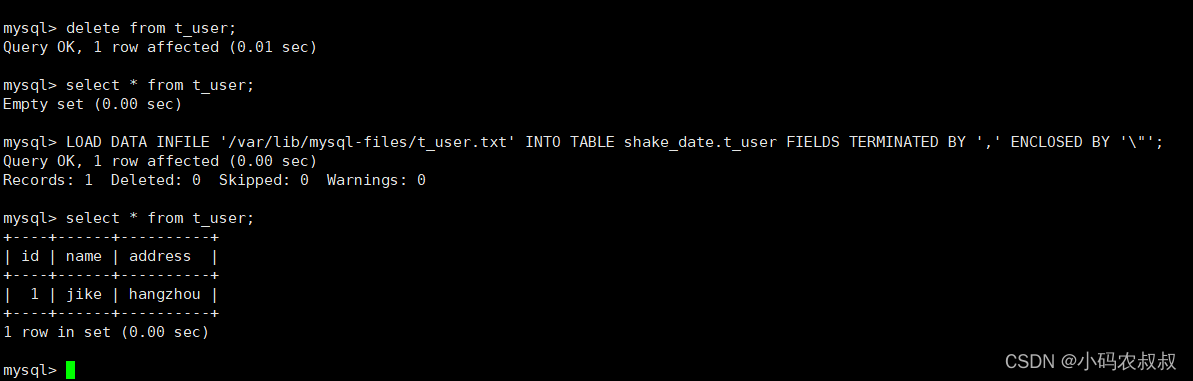
LOAD DATA INFILE '/var/lib/mysql-files/t_user.txt' INTO TABLE shake_date.t_user FIELDS TERMINATED BY ',' ENCLOSED BY '\"';
导入之前先清理下表的数据
3、使用mysqlimport方式导入文本文件
仍然以上面的那个以逗号分割的文件为例进行说明
先清理数据表
执行下面的语句进行数据导入
mysqlimport -uroot -pXXX shake_date '/var/lib/mysql-files/t_user.txt' --fields-terminated-by=',' --fields-optionally-enclosed-by='\"'
执行完成后,可以看到数据又恢复了;

到此这篇关于mysql 数据备份与恢复使用详解的文章就介绍到这了,更多相关mysql 备份与恢复内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解Mysql自动备份与恢复的几种方法(图文教程)
自动备份MySQL 5.0有三个方案: 备份方案一: 通过 mysqldump命令,直接生成一个完整的 .sql 文件 Step 1: 创建一个批处理 (说明:root 是mysql默认用户名, aaaaaa 是mysql密码, bugtracker 是数据库名) ------------mySql_backup.bat-------------------------------------------------------------------------------------- d
-
从MySQL全库备份中恢复某个库和某张表的方法
在Mysqldump官方工具中,如何只恢复某个库呢? 全库备份 [root@HE1 ~]# mysqldump -uroot -p --single-transaction -A --master-data=2 >dump.sql 只还原erp库的内容 [root@HE1 ~]# mysql -uroot -pMANAGER erp --one-database <dump.sql 可以看出这里主要用到的参数是--one-database简写-o的参数,极大方便了我们的恢复灵活性. 那么如何从
-
mysql全量备份和快速恢复的方法整理
一个简单的mysql全量备份脚本,备份最近15天的数据. 备份 #每天备份mysql数据库(保存最近15天的数据脚本) DATE=$(date +%Y%m%d) /home/cuixiaohuan/lamp/mysql5/bin/mysqldump -uuser -ppassword need_db > /home/cuixiaohuan/bak_sql/mysql_dbxx_$DATE.sql; find /home/cuixiaohuan/bak_sql/ -mtime +15 -name
-
MySQL5.7 mysqldump备份与恢复的实现
MySQL 备份 冷备份: 停止服务进行备份,即停止数据库的写入 热备份: 不停止服务进行备份(在线) mysql 的 MyIsam 引擎只支持冷备份,InnoDB 支持热备份,原因: InnoDB引擎是事务性存储引擎,每一条语句都会写日志,并且每一条语句在日志里面都有时间点,那么在备份的时候,mysql可以根据这个日志来进行redo和undo,将备份的时候没有提交的事务进行回滚,已经提交了的进行重做.但是MyIsam不行,MyIsam是没有日志的,为了保证一致性,只能停机或者锁表进行备份. I
-
shell脚本实现mysql定时备份、删除、恢复功能
mysql备份脚本: 脚本实现:按照数据库名称,全量备份mysql数据库并定期删除 #!/bin/bash #全备方式,一般在从机上执行,适用于小中型mysql数据库 #删除15天以前备份 #作者:lcm_linux #时间:2019.08.06 source ~/.bash_profile #加载用户环境变量 set -o nounset #引用未初始化变量时退出 set -o errexit #执行shell命令遇到错误时退出 #备份用户---需要在mysql中提前创建并授权 #GRANT
-
详解Mysql之mysqlbackup备份与恢复实践
一.mysqlbackup简介 mysqlbackup是ORACLE公司也提供了针对企业的备份软件MySQL Enterprise Backup简称,是MySQL服务器的备份实用程序.它是一个多平台,高性能的工具,具有丰富的功能,例如 "热"(在线)备份,增量和差异备份,选择性备份和还原,支持直接云存储备份,备份加密和压缩以及许多其他有价值的功能特征.经过优化以用于InnoDB表,MySQL Enterprise Backup能够备份和还原MySQL支持的任何存储引擎创建的各种表.它的
-
mysql 数据备份与恢复使用详解(超完整详细教程)
目录 一.前言 二.数据备份策略 1.全备 2.增备 3.差异备份 三.数据备份类型 1.冷备 2.热备 3.温备 四.前置准备 五.mysqldump 数据备份命令使用 1.命令格式 2.案例演示 3.其他重要参数选项补充 六.mysqldump 数据恢复 1.全量恢复 2.全量备份中恢复单库 3.从某个数据库中恢复单表数据 4.使用dump + binlog进行数据恢复 七.物理备份 八.表的导出与导入 1. 使用SELECT…INTO OUTFILE导出文本文件 2. 使用mysqldum
-
Android通过json向MySQL中读写数据的方法详解【读取篇】
本文实例讲述了Android通过json向MySQL中读取数据的方法.分享给大家供大家参考,具体如下: 首先 要定义几个解析json的方法parseJsonMulti,代码如下: private void parseJsonMulti(String strResult) { try { Log.v("strResult11","strResult11="+strResult); int index=strResult.indexOf("[");
-
Android通过json向MySQL中读写数据的方法详解【写入篇】
本文实例讲述了Android通过json向MySQL中写入数据的方法.分享给大家供大家参考,具体如下: 先说一下如何通过json将Android程序中的数据上传到MySQL中: 首先定义一个类JSONParser.Java类,将json上传数据的方法封装好,可以直接在主程序中调用该类,代码如下 public class JSONParser { static InputStream is = null; static JSONObject jObj = null; static String j
-
Mysql联表update数据的示例详解
1.MySQL UPDATE JOIN语法 在MySQL中,可以在 UPDATE语句 中使用JOIN子句执行跨表更新.MySQL UPDATE JOIN的语法如下: UPDATE T1, T2, [INNER JOIN | LEFT JOIN] T1 ON T1.C1 = T2. C1 SET T1.C2 = T2.C2, T2.C3 = expr WHERE condition 更详细地看看MySQL UPDATE JOIN语法: 首先,在UPDATE子句之后,指定主表(T1)和希望主表连接表
-
Mysql InnoDB引擎中的数据页结构详解
目录 Mysql InnoDB引擎数据页结构 一.页的简介 二.数据页的结构 三.记录在页中的存储结构 四.记录头信息 1. deleted_flag 2. min_rec_flag 3. n_owned 4. heap_no 5. record_type 6. next_record Mysql InnoDB引擎数据页结构 InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理
-
MySQL中数据视图操作详解
目录 1.视图概述 1.1创建视图 1.2视图的查询 2.操作视图 2.1通过视图操作数据 2.2修改视图定义 2.3删除视图 1.视图概述 视图是从一个或多个表(或视图)导出的表.视图与表(有时为与视图区别,也称表为基本表)不同,视图是一个虚表,即视图所对应的数据不进行实际存储,数据库中只存储视图的定义,对视图的数据进行操作时,系统根据视图的定义去操作与视图相关联的基本表. 视图一经定义,就可以像表一样被查询.修改.删除和更新.使用视图有下列优点: 1.为用户集中数据,简化用户的数据查询和处理
-
MySQL用户和数据权限管理详解
目录 1.管理用户 1.1.添加用户 1.2.删除用户 1.3.修改用户名 1.4.修改密码 2.授予权限和回收权限 2.1.授予权限 2.2.权限的转移和限制 2.3.回收权限 1.管理用户 1.1.添加用户 可以使用CREATE USER语句添加一个或多个用户,并设置相应的密码 语法格式: CREATE USER 用户名 [IDENTIFIED BY [PASSWORD]'密码'] CREATE USER用于创建新的MySQL账户.CREATE USER会在系统本身的mysql数据库的use
-
Mysql my.ini 配置文件详解
Mysql my.ini 配置文件详解 #BEGIN CONFIG INFO #DESCR: 4GB RAM, 只使用InnoDB, ACID, 少量的连接, 队列负载大 #TYPE: SYSTEM #END CONFIG INFO # # 此mysql配置文件例子针对4G内存 # 主要使用INNODB #处理复杂队列并且连接数量较少的mysql服务器 # # 将此文件复制到/etc/my.cnf 作为全局设置, # mysql-data-dir/my.cnf 作为服务器指定设置 # (@loc
-
对python 操作solr索引数据的实例详解
测试代码1: def test(self): data = {"add": {"doc": {"id": "100001", "*字段名*": u"我是一个大好人"}}} params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000} ur
-
PostgreSQL使用MySQL外表的步骤详解(mysql_fdw)
浅谈 postgres不知不觉已经升到了版本13,记得两年前还是版本10,当然这中间一直期望着哪天能在项目中使用postgresql,现在已实现哈-: 顺带说一下:使用postgresql的原因是它的生态完整,还有一个很重要的点儿是速度快这个在第10版的时 这么说也许还为时过早, 但是在13这一版本下一点儿也不为过,真的太快了,我简单的用500w的数据做聚合,在不建立索引(主键除外)的情况下 执行一个聚合操作,postgres 的速度是mysql的8倍,真的太快了-:好了,这一章节我就聊一聊我实