Python实现梯度下降法的示例代码
目录
- 1.首先读取数据集
- 2.初始化相关参数
- 3.定义计算代价函数–>MSE
- 4.梯度下降
- 5.执行
1.首先读取数据集
导包并读取数据,数据自行任意准备,只要有两列,可以分为自变量x和因变量y即可即可。
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt("data.csv", delimiter=",")
x_data = data[:, 0]
y_data = data[:, 1]
2.初始化相关参数
# 初始化 学习率 即每次梯度下降时的步长 这里设置为0.0001 learning_rate = 0.0001 # 初始化 截距b 与 斜率k b = 0 k = 0 # 初始化最大迭代的次数 以50次为例 n_iterables = 50
3.定义计算代价函数–>MSE
使用均方误差 MSE (Mean Square Error)来作为性能度量标准
假设共有m个样本数据,则均方误差:

将该公式定义为代价函数,此外为例后续求导方便,则使结果在原mse的基础上,再乘以1/2。
def compute_mse(b, k, x_data, y_data):
total_error = 0
for i in range(len(x_data)):
total_error += (y_data[i] - (k * x_data[i] + b)) ** 2
# 为方便求导:乘以1/2
mse_ = total_error / len(x_data) / 2
return mse_
4.梯度下降
分别对上述的MSE表达式(乘以1/2后)中的k,b求偏导,

更新b和k时,使用原来的b,k值分别减去关于b、k的偏导数与学习率的乘积即可。至于为什么使用减号,可以这么理解:以斜率k为例,当其导数大于零的时候,则表示均方误差随着斜率的增大而增大,为了使均方误差减小,则不应该使斜率继续增大,所以需要使其减小,反之当偏导大于零的时候也是同理。其次,因为这个导数衡量的是均方误差的变化,而不是斜率和截距的变化,所以这里需要引入一个学习率,使得其与偏导数的乘积能够在一定程度上起到控制截距和斜率变化的作用。
def gradient_descent(x_data, y_data, b, k, learning_rate, n_iterables):
m = len(x_data)
# 迭代
for i in range(n_iterables):
# 初始化b、k的偏导
b_grad = 0
k_grad = 0
# 遍历m次
for j in range(m):
# 对b,k求偏导
b_grad += (1 / m) * ((k * x_data[j] + b) - y_data[j])
k_grad += (1 / m) * ((k * x_data[j] + b) - y_data[j]) * x_data[j]
# 更新 b 和 k 减去偏导乘以学习率
b = b - (learning_rate * b_grad)
k = k - (learning_rate * k_grad)
# 每迭代 5 次 输出一次图形
if i % 5 == 0:
print(f"当前第{i}次迭代")
print("b_gard:", b_grad, "k_gard:", k_grad)
print("b:", b, "k:", k)
plt.scatter(x_data, y_data, color="maroon", marker="x")
plt.plot(x_data, k * x_data + b)
plt.show()
return b, k
5.执行
print(f"开始:截距b={b},斜率k={k},损失={compute_mse(b,k,x_data,y_data)}")
print("开始迭代")
b, k = gradient_descent(x_data, y_data, b, k, learning_rate, n_iterables)
print(f"迭代{n_iterables}次后:截距b={b},斜率k={k},损失={compute_mse(b,k,x_data,y_data)}")
代码执行过程产生了一系列的图像,部分图像如下图所示,随着迭代次数的增加,代价函数越来越小,最终达到预期效果,如下图所示:
第5次迭代:

第10次迭代:
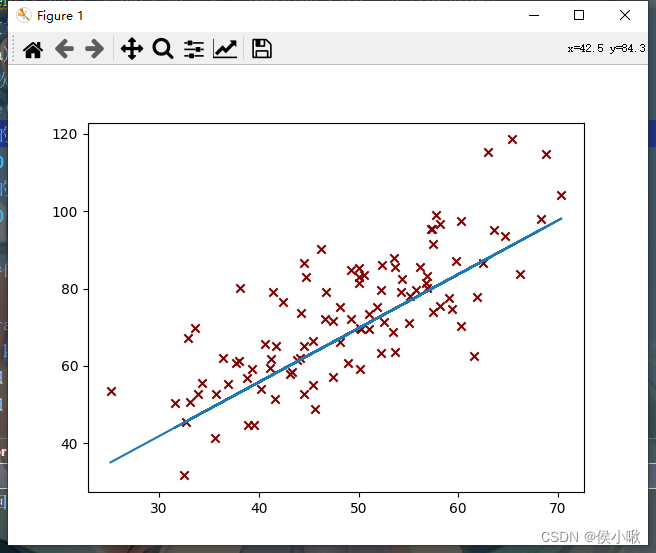
第50次迭代:
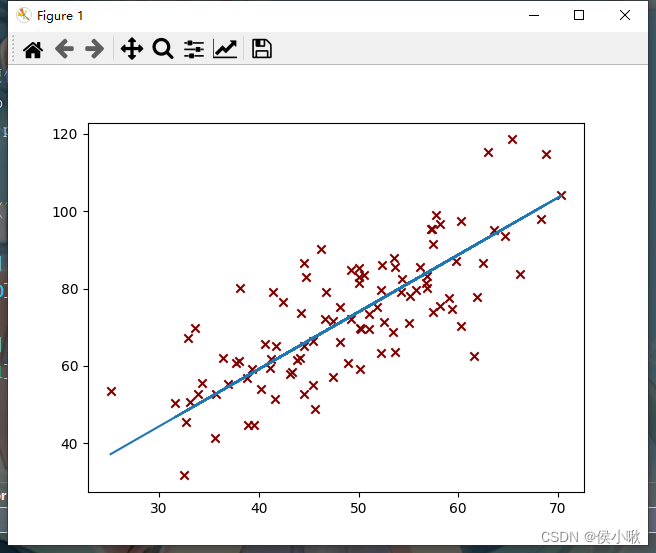
执行过程的输出结果如下图所示:

可以看到,随着偏导数越来越小,斜率与截距的变化也越来越细微。
到此这篇关于Python实现梯度下降法的示例代码的文章就介绍到这了,更多相关Python梯度下降法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

梯度下降法介绍及利用Python实现的方法示例
本文主要给大家介绍了梯度下降法及利用Python实现的相关内容,分享出来供大家参考学习,下面话不多说,来一起看看详细的介绍吧. 梯度下降法介绍 梯度下降法(gradient descent),又名最速下降法(steepest descent)是求解无约束最优化问题最常用的方法,它是一种迭代方法,每一步主要的操作是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向(因为在该方向上目标函数下降最快,这也是最速下降法名称的由来). 梯度下降法特点:越接近目标值,步长越小,下降速度越慢. 直观上
-
python实现梯度下降法
本文实例为大家分享了python实现梯度下降法的具体代码,供大家参考,具体内容如下 使用工具:Python(x,y) 2.6.6 运行环境:Windows10 问题:求解y=2*x1+x2+3,即使用梯度下降法求解y=a*x1+b*x2+c中参数a,b,c的最优值(监督学习) 训练数据: x_train=[1, 2], [2, 1],[2, 3], [3, 5], [1,3], [4, 2], [7, 3], [4, 5], [11, 3], [8, 7] y_train=[7, 8, 10,
-
python梯度下降法的简单示例
梯度下降法的原理和公式这里不讲,就是一个直观的.易于理解的简单例子. 1.最简单的情况,样本只有一个变量,即简单的(x,y).多变量的则可为使用体重或身高判断男女(这是假设,并不严谨),则变量有两个,一个是体重,一个是身高,则可表示为(x1,x2,y),即一个目标值有两个属性. 2.单个变量的情况最简单的就是,函数hk(x)=k*x这条直线(注意:这里k也是变化的,我们的目的就是求一个最优的 k).而深度学习中,我们是不知道函数的,也就是不知道上述的k. 这里讨论单变量的情况: 在不知道
-
python机器学习逻辑回归随机梯度下降法
目录 写在前面 随机梯度下降法 参考文献 写在前面 随机梯度下降法就在随机梯度上.意思就是说当我们在初始点时想找到下一点的梯度,这个点是随机的.全批量梯度下降是从一个点接着一点是有顺序的,全部数据点都要求梯度且有顺序. 全批量梯度下降虽然稳定,但速度较慢: SGD虽然快,但是不够稳定 随机梯度下降法 随机梯度下降法(Stochastic Gradient Decent, SGD)是对全批量梯度下降法计算效率的改进算法.本质上来说,我们预期随机梯度下降法得到的结果和全批量梯度下降法相接近:SGD的
-
Python语言描述随机梯度下降法
1.梯度下降 1)什么是梯度下降? 因为梯度下降是一种思想,没有严格的定义,所以用一个比喻来解释什么是梯度下降. 简单来说,梯度下降就是从山顶找一条最短的路走到山脚最低的地方.但是因为选择方向的原因,我们找到的的最低点可能不是真正的最低点.如图所示,黑线标注的路线所指的方向并不是真正的地方. 既然是选择一个方向下山,那么这个方向怎么选?每次该怎么走? 先说选方向,在算法中是以随机方式给出的,这也是造成有时候走不到真正最低点的原因. 如果选定了方向,以后每走一步,都是选择最陡的方向,直到最低点.
-
python实现随机梯度下降法
看这篇文章前强烈建议你看看上一篇python实现梯度下降法: 一.为什么要提出随机梯度下降算法 注意看梯度下降法权值的更新方式(推导过程在上一篇文章中有) 也就是说每次更新权值都需要遍历整个数据集(注意那个求和符号),当数据量小的时候,我们还能够接受这种算法,一旦数据量过大,那么使用该方法会使得收敛过程极度缓慢,并且当存在多个局部极小值时,无法保证搜索到全局最优解.为了解决这样的问题,引入了梯度下降法的进阶形式:随机梯度下降法. 二.核心思想 对于权值的更新不再通过遍历全部的数据集,而是选择其中
-
Python实现梯度下降法的示例代码
目录 1.首先读取数据集 2.初始化相关参数 3.定义计算代价函数–>MSE 4.梯度下降 5.执行 1.首先读取数据集 导包并读取数据,数据自行任意准备,只要有两列,可以分为自变量x和因变量y即可即可. import numpy as np import matplotlib.pyplot as plt data = np.loadtxt("data.csv", delimiter=",") x_data = data[:, 0] y_data = data
-
Python实现登录接口的示例代码
之前写了Python实现登录接口的示例代码,最近需要回顾,就顺便发到随笔上了 要求: 1.输入用户名和密码 2.认证成功,显示欢迎信息 3.用户名3次输入错误后,退出程序 4.密码3次输入错误后,锁定用户名 Readme: 1.UserList.txt 是存放用户名和密码的文件,格式为:username: password,每行存放一条用户信息 2.LockList.txt 是存放已被锁定用户名的文件,默认为空 3.用户输入用户名,程序首先查询锁定名单 LockList.txt,如果用户名在里面
-
python实现log日志的示例代码
源代码: # coding=utf-8 import logging import os import time LEVELS={'debug':logging.DEBUG,\ 'info':logging.INFO,\ 'warning':logging.WARNING,\ 'error':logging.ERROR,\ 'critical':logging.CRITICAL,} logger=logging.getLogger() level='default' def createFile
-
Python中字符串与编码示例代码
在最新的Python 3版本中,字符串是以Unicode编码的,即Python的字符串支持多语言 编码和解码 字符串在内存中以Unicode表示,在操作字符串时,经常需要str和bytes互相转换 如果在网络上传输或保存到磁盘上,则从内存读到的数据就是str,要把str变为以字节为单位的bytes,称为编码 如果从网络或磁盘上读取字节流,则从网络或磁盘上读到的数据就是bytes,要把bytes变为str,称为解码 为避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行
-
python+selenium+chromedriver实现爬虫示例代码
下载好所需程序 1.Selenium简介 Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样. 2.Selenium安装 方法一:在Windows命令行(cmd)输入pip install selenium即可自动安装,安装完成后,输入pip show selenium可查看当前的版本 方法二:直接下载selenium包: selenium下载网址 Pychome安装selenium如果出现无法安装,参考以下博客 解决Pycharm无法使用已经安装S
-
Python实现ElGamal加密算法的示例代码
在密码学中,ElGamal加密算法是一个基于迪菲-赫尔曼密钥交换的非对称加密算法.它在1985年由塔希尔·盖莫尔提出.GnuPG和PGP等很多密码学系统中都应用到了ElGamal算法. ElGamal加密算法可以定义在任何循环群G上.它的安全性取决于G上的离散对数难题. 使用Python实现ElGamal加密算法,完成加密解密过程,明文使用的是125位数字(1000比特). 代码如下: import random from math import pow a = random.randint(2
-
Python操作MySQL数据库的示例代码
1. MySQL Connector 1.1 创建连接 import mysql.connector config={ "host":"localhost","port":"3306", "user":"root","password":"password", "database":"demo" } con=
-
python golang中grpc 使用示例代码详解
python 1.使用前准备,安装这三个库 pip install grpcio pip install protobuf pip install grpcio_tools 2.建立一个proto文件hello.proto // [python quickstart](https://grpc.io/docs/quickstart/python.html#run-a-grpc-application) // python -m grpc_tools.protoc --python_out=. -
-
拿来就用!Python批量合并PDF的示例代码
大家好,今天分享一个实用的办公脚本:将多个PDF合并为一个PDF,例如我手上现在有如下3个PDF分册,需要整合成一个完整的PDF 如果换成你操作的话,是不是打开百度搜索:PDF合并,然后去第三方网站操作,可能会收费不说还担心文件泄漏,现在有请Python出场,简单快速,光速合并,拿走就用! 首先导入需要的库和路径设置 import os from PyPDF2 import PdfFileReader, PdfFileWriter if __name__ == '__main__': # 设置存