Spring Cloud Ribbon的使用原理解析
目录
- 一、概述
- 1、Ribbon是什么
- 2、Ribbon能干什么
- 3、Ribbon现状
- 4、未来替代方案
- 5、架构说明
- 二、RestTemplate 用法详解
- 三、Ribbon核心组件IRule
- 四、实战项目
- 1、回顾之前的项目
- 2、@RibbonClient注解用法
- 3、配置文件用法
- 3、测试
- 五、Ribbon原理
- 1、负载均衡算法
- 2、源码分析
- 六、手写负载均衡器
一、概述
1、Ribbon是什么
Ribbon是Netflix发布的开源项目,Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的框架。
2、Ribbon能干什么
LB负载均衡(Load Balance)是什么?
简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA(高可用)。
常见的负载均衡有软件Nginx,硬件 F5等。
什么情况下需要负载均衡?
现在Java非常流行微服务,也就是所谓的面向服务开发,将一个项目拆分成了多个项目,其优点有很多,其中一个优点就是:将服务拆分成一个一个微服务后,我们很容易的来针对性的进行集群部署。例如订单模块用的人比较多,我就可以将这个模块多部署几台机器,来分担单个服务器的压力。
这时候有个问题来了,前端页面请求的时候到底请求集群当中的哪一台?既然是降低单个服务器的压力,所以肯定全部机器都要利用起来,而不是说一台用着,其他空余着。这时候就需要用负载均衡了,像这种前端页面调用后端请求的,要做负载均衡的话,常用的就是Nginx。
Ribbon和Nginx负载均衡区别
- 当后端服务是集群的情况下,前端页面调用后端请求,要做负载均衡的话,常用的就是Nginx。
- Ribbon主要是在服务端内做负载均衡,举例:订单后端服务 要调用 支付后端服务,这属于后端之间的服务调用,压根根本不经过页面,而支付后端服务是集群,这时候订单服务就需要做负载均衡来调用支付服务,记住是订单服务做负载均衡 来调用 支付服务。
负载均衡分类
- 集中式LB:即在服务的消费方和提供方之间使用独立的LB设施(可以是硬件,如F5, 也可以是软件,如nginx),由该设施负责把访问请求通过某种策略转发至服务的提供方;
- 进程内LB:将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务器。
Ribbon负载均衡
Ribbon就属于进程内LB,它只是一个类库,集成于消费方进程。
举例:微服务经常会涉及到A服务调用B服务的接口,这时候就需要用HTTP远程调用框架,常见的有Feign、RestTemplate、HttpClient,假如B服务只有一个节点,这时候我们可以在调用的时候写固定ip来进行调用,假如B服务的节点存在多个(也就是集群),那A服务究竟调用B服务的哪个节点呢,这时候可以通过负载均衡框架来计算出调用哪个,比如轮询调用B服务的多个节点,总不可能一直调用人家的一个服务,这样B服务的集群有什么意义呢?或者也可以随机调用任意节点,总之负载均衡的作用就是避免一直调用一个节点。
大概的流程:RestTemplate或者Feign可以通过注册中心拿到服务提供方的IP+端口,假如提供者有多个,那他就会拿到多个地址,有了这些地址就差访问的时候访问哪个地址的服务了,而Ribbon可以很好的和RestTemplate或者Feign进行集成,来决定调用哪个服务,具体是负载均衡还是随机Ribbon都可以设置。
3、Ribbon现状
项目处于维护状态 ,已经一年多没有更新过了。
https://github.com/Netflix/ribbon

4、未来替代方案

5、架构说明

首先通过上图一定要明白一点:ribbon一定是用在消费方,而不是服务的提供方!
Ribbon在工作时分成两步(这里以Eureka为例,consul和zk同样道理):
- 第一步先选择 EurekaServer ,它优先选择在同一个区域内负载较少的server.
- 第二步再根据用户指定的策略,在从server取到的服务注册列表中选择一个地址。
其中Ribbon提供了多种策略:比如轮询、随机和根据响应时间加权。
Spring Cloud Eureka服务注册中心入门流程分析
https://www.jb51.net/article/204240.htm
之前写样例时候没有引入spring-cloud-starter-ribbon也可以使用ribbon,这是为什么?
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
猜测spring-cloud-starter-netflix-eureka-client自带了spring-cloud-starter-ribbon引用
证明如下: 可以看到spring-cloud-starter-netflix-eureka-client 确实引入了Ribbon(zk和consul注册中心同样是如此)

二、RestTemplate 用法详解
本篇涉及到的项目均使用RestTemplate结合Ribbon来完成远程负载均衡调用!
RestTemplate 用法详解:https://www.jb51.net/article/256124.htm
三、Ribbon核心组件IRule
IRule:根据特定算法中从服务列表中选取一个要访问的服务
Ribbon给提供了很多现成的算法类,IRule就是最顶层的算法类接口,
Ribbon默认是轮询规则。假如我们想要修改算法,只需要将算法类注入到容器。然后通过简单的配置就可以修改。

这些算法类都在如下包当中,一般我们只要引入Eureka、zk、consul三个其中一个注册中心的依赖,就会附带Ribbon的依赖,Ribbon依赖就会依赖ribbon-loadbalancer包。
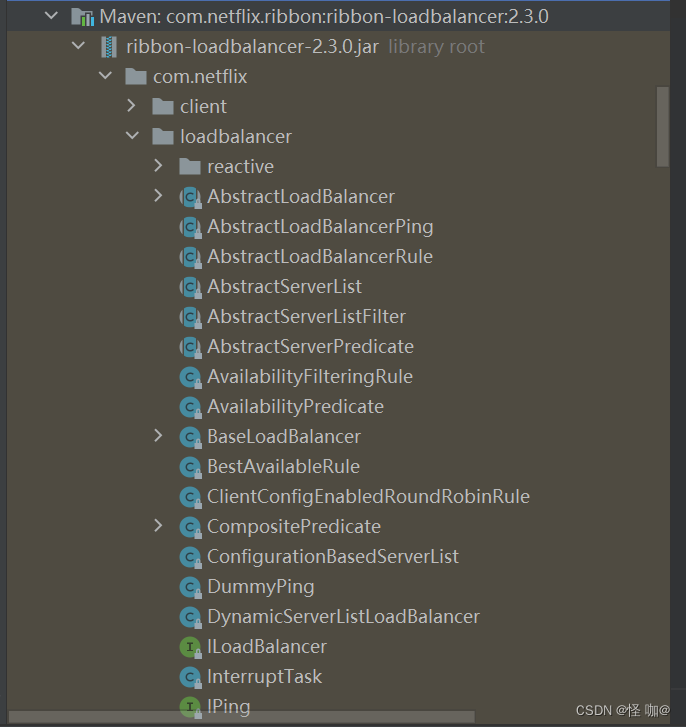
- ClientConfigEnabledRoundRobinRule:该策略较为特殊,我们一般不直接使用它。因为它本身并没有实现什么特殊的处理逻辑。一般都是可以通过继承他重写一些自己的策略,默认的choose方法就实现了线性轮询机制
- BestAvailableRule:继承自ClientConfigEnabledRoundRobinRule,会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务,该策略的特性是可选出最空闲的实例
- PredicateBasedRule:继承自ClientConfigEnabledRoundRobinRule,抽象策略,需要重写方法的,然后自己来自己定义过滤规则的
- AvailabilityFilteringRule:继承PredicateBasedRule,先过滤掉故障实例,再选择并发较小的实例
- ZoneAvoidanceRule:继承PredicateBasedRule,默认规则,复合判断server所在区域的性能和server的可用性选择服务器
- com.netflix.loadbalancer.RoundRobinRule:轮询
- WeightedResponseTimeRule:对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择
- ResponseTimeWeightedRule:对RoundRobinRule的扩展,响应时间加权
- com.netflix.loadbalancer.RandomRule:随机
- com.netflix.loadbalancer.StickyRule:这个基本也没人用
- com.netflix.loadbalancer.RetryRule:先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务
- ZoneAvoidanceRule:默认规则,复合判断server所在区域的性能和server的可用性选择服务器
四、实战项目
1、回顾之前的项目
https://www.jb51.net/article/204240.htm
如下是项目当中涉及到的微服务:
ribbon一定是用在消费端,A调用B服务的接口,那么A就是消费端

在这个项目示例当中,在消费者服务当中通过RestTemplate+@LoadBalanced来完成负载均衡调用提供者。

这里调用提供者的时候不再是固定ip,而是通过服务名称调用。相当于通过服务名称向注册中心当中去获取注册的服务,假如注册了两个名称一样的服务,那么就获取到了两个ip,RestTemplate内部控制了访问哪个ip的服务。他是如何负载均衡的?就是和Ribbon无缝结合,具体原理后续再说。
注意:RestTemplate想要通过服务名称来调用,那么一定要配置@LoadBalanced注解,不然会报错的,只有配置了这个注解,RestTemplate才会和Ribbon相结合。
服务名称就是在提供者的application当中配置的。

2、@RibbonClient注解用法
这个注解的意思就是,当RestTemplate调用服务名称为CLOUD-PAYMENT-SERVICE的时候,采用MySelfRule当中注入的负载均衡算法。
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration=MySelfRule.class)
官方文档明确给出了警告:这个自定义配置类不能放在@ComponentScan所扫描的当前包下以及子包下,否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,达不到特殊化定制的目的了(也就是一旦被扫描到,RestTemplate直接不管调用哪个服务都会用指定的算法)。
springboot项目当中的启动类使用了@SpringBootApplication注解,这个注解内部就有@ComponentScan注解,默认是扫描启动类包下所有的包,所以我们要达到定制化一定不要放在他能扫描到的地方。
cloud中文官网:https://www.springcloud.cc/spring-cloud-greenwich.html#netflix-ribbon-starter

3、配置文件用法

如下配置就可以取代@RibbonClient注解,注意一定要使用全类名,没有@RibbonClient级别高:
CLOUD-PAYMENT-SERVICE:
ribbon:
NFLoadBalancerRuleClassName: com.gzl.myrule.MySelfRule
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration=MySelfRule.class)
4、修改默认算法
我们还是基于这个Eureka项目示例来进行演示修改默认算法::https://www.jb51.net/article/204240.htm
1. 修改cloud-consumer-order80(ribbon一定是用在消费端,A调用B服务的接口,那么A就是消费端)
新建package,只要不和启动类在同一个包下即可!

@Configuration
public class MySelfRule {
@Bean
public IRule myRule() {
//定义为随机
return new RandomRule();
}
}
2、主启动类添加@RibbonClient(这个是一定要指定的,不然他不知道我们要修改算法,假如配置文件方式指定了就不需要添加这个注解了)
在启动该微服务的时候就能去加载我们的自定义Ribbon配置类,从而使配置生效:
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration= MySelfRule.class)

3、测试
这时候再测试访问消费者接口,会发现已经不再是轮询访问了,成为了随机访问!
访问:http://localhost/consumer/payment/get/1
五、Ribbon原理
1、负载均衡算法
以轮询算法为例:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标
每次服务重启动后rest接口计数从1开始。
为什么要获取服务器下标呢?
算法完全是基于DiscoveryClient来从注册中心获取到注册的服务列表,获取的是个List<ServiceInstance>,有了下标,有了服务list集合,那我们自然就知道要访问哪个服务了。
import org.springframework.cloud.client.discovery.DiscoveryClient;
@Resource
private DiscoveryClient discoveryClient;
List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");
for (ServiceInstance element : instances) {
System.out.println(element.getServiceId() + "\t" + element.getHost() + "\t" + element.getPort() + "\t"
+ element.getUri());
}
输出的结果:

如: List [0] instances = 127.0.0.1:8002
List [1] instances = 127.0.0.1:8001
8001+ 8002 组合成为集群,它们共计2台机器,集群总数为2, 按照轮询算法原理:
- 当总请求数为1时: 1 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
- 当总请求数位2时: 2 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
- 当总请求数位3时: 3 % 2 =1 对应下标位置为1 ,则获得服务地址为127.0.0.1:8001
- 当总请求数位4时: 4 % 2 =0 对应下标位置为0 ,则获得服务地址为127.0.0.1:8002
- 如此类推…
2、源码分析
我看的Cloud的Hoxton.SR1版本,版本之间源码略有不同,但是大概思路差不多。
ribbon实现的关键点是为ribbon定制的RestTemplate,ribbon利用了RestTemplate的拦截器机制,在拦截器中实现ribbon的负载均衡。负载均衡的基本实现就是利用applicationName从服务注册中心获取可用的服务地址列表,然后通过一定算法负载,决定使用哪一个服务地址来进行http调用。
1.Ribbon的RestTemplate
RestTemplate中有一个属性是List<ClientHttpRequestInterceptor> interceptors,如果interceptors里面的拦截器数据不为空,在RestTemplate进行http请求时,这个请求就会被拦截器拦截进行,拦截器需要实现ClientHttpRequestInterceptor接口,接口就一个方法,需要实现以下方法:

也就是说拦截器需要完成http请求,并封装一个标准的response返回。
2.Ribbon中的拦截器
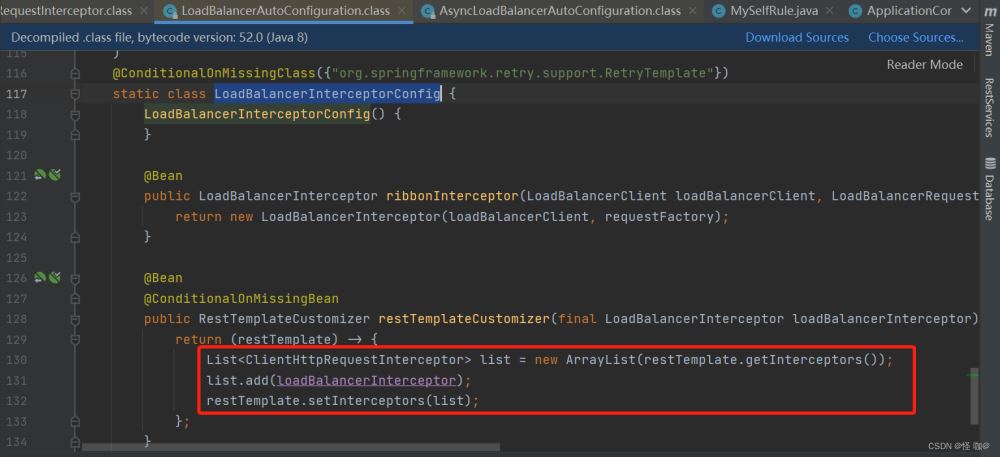
在Ribbon 中就是通过名字为LoadBalancerInterceptor的拦截器,注入到RestTemplate中,进行拦截请求,然后实现负载均衡调用的。
拦截器定义在:org.springframework.cloud.client.loadbalancer.LoadBalancerAutoConfiguration
这个类是在这个包下,并不在Ribbon的包下:

拦截器的定义与拦截器注入器的定义:下面的bean是拦截器注入器
3.Ribbon中的拦截器注入到RestTemplate
定义了拦截器,自然需要把拦截器注入到、RestTemplate才能生效,那么Ribbon中是如何实现的?上面说了拦截器的定义与拦截器注入器的定义,那么肯定会有个地方使用注入器来注入拦截器的。
还是在这个类当中:org.springframework.cloud.client.loadbalancer.LoadBalancerAutoConfiguration

遍历context中的注入器,调用注入方法,为目标RestTemplate注入拦截器,注入器和拦截器都是我们定义好的。
还有关键的一点是:需要注入拦截器的目标restTemplates到底是哪一些?因为RestTemplate实例在context中可能存在多个,不可能所有的都注入拦截器,这里就是@LoadBalanced注解发挥作用的时候了。
4.LoadBalanced注解
严格上来说,这个注解是spring cloud实现的,不是ribbon中的,它的作用是在依赖注入时,只注入实例化时被@LoadBalanced修饰的实例。
例如我们定义Ribbon的RestTemplate的时候是这样的:
@Bean
@LoadBalanced
public RestTemplate rebbionRestTemplate(){
return new RestTemplate();
}
因此才能为我们定义的RestTemplate注入拦截器。
那么@LoadBalanced是如何实现这个功能的呢?其实都是spring的原生操作,@LoadBalance的源码如下

@Qualifier注解很重要:
@Autowired默认是根据类型进行注入的,因此如果有多个类型一样的Bean候选者,则需要限定其中一个候选者,否则将抛出异常,@Qualifier限定描述符除了能根据名字进行注入,更能进行更细粒度的控制如何选择候选者
@LoadBalanced很明显,‘继承’了注解@Qualifier,RestTemplates通过@Autowired注入,同时被@LoadBalanced修饰,所以只会注入@LoadBalanced修饰的RestTemplate,也就是我们的目标RestTemplate。
5.拦截器逻辑实现
这里使用的是LoadBalancerInterceptor拦截器

当我们每通过RestTemplate调用一个接口的时候都会经过这个拦截器,通过拦截器当中的intercept方法,然后执行excute的时候,打断点会发现他会执行到这:
在这里就是根据对应的负载均衡算法选择对应的服务,
RibbonLoadBalancerClient就是Ribbon当中的类了。由此可以看出框架有时候就是这样,来回套用,cloud对外提供API,然后组件进行真正的实现,假如感觉ribbon满足不了我们,我们完全可以按照cloud的API来开发新的负载均衡框架,进行无缝替换。

(1)getLoadBalancer(serviceId):可以理解为,再第一次请求到来时,创建好IClientConfig(客户端配置)、ServerList(从配置文件中加载的服务列表)、IRule(负载均衡策略)与IPing (探活策略)等Bean,是一种懒加载的模式。
(2)getServer(loadBalancer, hint):则是通过以上的负载均衡策略与探活策略,从服务列表中选择合适的服务实例(详细代码在ZoneAwareLoadBalancer的chooseServer方法中)。Server对象包含ip、端口与协议等信息。
重点看getServer方法,看看是如何选择服务的

默认就是ZoneAvoidanceRule负载均衡算法!

ZoneAvoidanceRule:继承PredicateBasedRule,他是没有重写choose方法的,这时候就进入到了父类的choose方法。
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
// 这里就完成了服务的选择
// 而且我们可以看到,这里的lb.getAllServers 说明ILoadBalancer直接存储或者间接存储了服务列表
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
从上面可以看到chooseRoundRobinAfterFiltering 这个方法的意思就是在过滤之后,选择轮询的负载均衡方式。
而lb.getAllServers是获取该服务的所有服务实例。
由此可见chooseRoundRobinAfterFiltering就是选择的关键点了。
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
// 过滤掉不复合条件的服务实例
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
// incrementAndGetModulo 这个就是轮询的关键计算
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
其计算过程还是比较简单的,使用了AtomicInteger来计算访问的次数,cas+自旋锁来控制多线程的安全性!
private final AtomicInteger nextIndex = new AtomicInteger();

六、手写负载均衡器
1.RestTemplate去掉注解@LoadBalanced
2.LoadBalancer接口(在80消费者添加)
这个接口相当于是传进去多个服务,然后根据实现类,来选择出一个服务,至于是轮询还是随机,我们自己实现。
import org.springframework.cloud.client.ServiceInstance;
import java.util.List;
public interface LoadBalancer {
ServiceInstance instances(List<ServiceInstance> serviceInstances);
}
3.定义实现类(在80消费者添加)
@Component
public class MyLB implements LoadBalancer {
private AtomicInteger atomicInteger = new AtomicInteger(0);
// 获取服务的下标
public final int getAndIncrement() {
int current;
int next;
do {
current = this.atomicInteger.get();
next = current >= 2147483647 ? 0 : current + 1;
} while (!this.atomicInteger.compareAndSet(current, next));
System.out.println("*****next: " + next);
return next;
}
// 下标和服务数进行取模
@Override
public ServiceInstance instances(List<ServiceInstance> serviceInstances) {
int index = getAndIncrement() % serviceInstances.size();
return serviceInstances.get(index);
}
}
4.调整8001服务和8002服务,这两个服务是提供者,新增一个接口,来进行测试使用!
@Value("${server.port}")
private String serverPort;
@GetMapping(value = "/payment/lb")
public String getPaymentLB() {
return serverPort;
}
5.在消费者80端添加测试接口
@GetMapping("/consumer/payment/lb")
public String getPaymentLB() {
// 这个是利用的cloud自带的DiscoveryClient,假如cloud项目使用了注册中心都可以通过服务名称来获取对应的服务信息
List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");
if (instances == null || instances.size() <= 0) {
return null;
}
// 获取要访问的服务信息
ServiceInstance serviceInstance = loadBalancer.instances(instances);
URI uri = serviceInstance.getUri();
return restTemplate.getForObject(uri + "/payment/lb", String.class);
}
6.测试
http://localhost/consumer/payment/lb
这样我们就成功自己实现了一个负载均衡!
到此这篇关于Spring Cloud Ribbon的使用详解的文章就介绍到这了,更多相关Spring Cloud Ribbon使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解spring cloud中使用Ribbon实现客户端的软负载均衡
开篇 本例是在springboot整合H2内存数据库,实现单元测试与数据库无关性和使用RestTemplate消费spring boot的Restful服务两个示例的基础上改造而来 在使用RestTemplate来消费spring boot的Restful服务示例中,我们提到,调用spring boot服务的时候,需要将服务的URL写死或者是写在配置文件中,但这两种方式,无论哪一种,一旦ip地址发生了变化,都需要改动程序,并重新部署服务,使用Ribbon的时候,可以有效的避免这个问题. 前言:
-
SpringCloud 中使用 Ribbon的方法详解
在前两章已经给大家讲解了Ribbon负载均衡的规则 以及 如何搭建Ribbon并调用服务,那么在这一章呢 将会给大家说一说如何在SpringCloud中去使用Ribbon.在搭建之前 我们需要做一些准备工作. 1. 搭建Eureka服务器:springCloud-ribbon-server(项目名称) 2. 服务提供者:springCloud-ribbon-police(项目名称) 3. 服务调用者:springCloud-ribbon-person(项目名称) 搭建Eureka服务器 配置 p
-
详解Spring cloud使用Ribbon进行Restful请求
写在前面 本文由markdown格式写成,为本人第一次这么写,排版可能会有点乱,还望各位海涵. 主要写的是使用Ribbon进行Restful请求,测试各个方法的使用,代码冗余较高,比较适合初学者,介意轻喷谢谢. 前提 一个可用的Eureka注册中心(文中以之前博客中双节点注册中心,不重要) 一个连接到这个注册中心的服务提供者 一个ribbon的消费者 注意:文中使用@GetMapping.@PostMapping.@PutMapping.@DeleteMapping等注解需要升级 spring
-
spring cloud Ribbon用法及原理解析
这篇文章主要介绍了spring cloud Ribbon用法及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简介 这篇文章主要介绍一下ribbon在程序中的基本使用,在这里是单独拿出来写用例测试的,实际生产一般是配置feign一起使用,更加方便开发.同时这里也通过源码来简单分析一下ribbon的基本实现原理. 基本使用 这里使用基于zookeeper注册中心+ribbon的方式实现一个简单的客户端负载均衡案例. 服务提供方 首先是一个
-
Spring Cloud Ribbon的使用原理解析
目录 一.概述 1.Ribbon是什么 2.Ribbon能干什么 3.Ribbon现状 4.未来替代方案 5.架构说明 二.RestTemplate 用法详解 三.Ribbon核心组件IRule 四.实战项目 1.回顾之前的项目 2.@RibbonClient注解用法 3.配置文件用法 3.测试 五.Ribbon原理 1.负载均衡算法 2.源码分析 六.手写负载均衡器 一.概述 1.Ribbon是什么 Ribbon是Netflix发布的开源项目,Spring Cloud Ribbon是基于Net
-
Spring cloud gateway工作流程原理解析
spring cloud gateway的包结构(在Idea 2019.3中展示) 这个包是spring-cloud-gateway-core.这里是真正的spring-gateway的实现的地方. 为了证明,我们打开spring-cloud-starter-gateway的pom文件 <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId
-
Spring Cloud Gateway重试机制原理解析
重试,我相信大家并不陌生.在我们调用Http接口的时候,总会因为某种原因调用失败,这个时候我们可以通过重试的方式,来重新请求接口. 生活中这样的事例很多,比如打电话,对方正在通话中啊,信号不好啊等等原因,你总会打不通,当你第一次没打通之后,你会打第二次,第三次-第四次就通了. 重试也要注意应用场景,读数据的接口比较适合重试的场景,写数据的接口就需要注意接口的幂等性了.还有就是重试次数如果太多的话会导致请求量加倍,给后端造成更大的压力,设置合理的重试机制才是最关键的. 今天我们来简单的了解下Spr
-
Spring Cloud Ribbon的踩坑记录与原理详析
简介 Spring Cloud Ribbon 是一个基于Http和TCP的客服端负载均衡工具,它是基于Netflix Ribbon实现的.它不像服务注册中心.配置中心.API网关那样独立部署,但是它几乎存在于每个微服务的基础设施中.包括前面的提供的声明式服务调用也是基于该Ribbon实现的.理解Ribbon对于我们使用Spring Cloud来讲非常的重要,因为负载均衡是对系统的高可用.网络压力的缓解和处理能力扩容的重要手段之一.在上节的例子中,我们采用了声明式的方式来实现负载均衡.实际上,内部
-
浅谈Spring Cloud Ribbon的原理
Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起.Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等.简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随即连接等)去连接这些机器.我们也很容易使用Ribbon实现自定义的负载均衡算法. 说起负载均衡一般都会想到服务端的负载均衡,常用产品包括LBS硬件或云服务.Nginx等,都是
-
spring boot jar的启动原理解析
1.前言 近来有空对公司的open api平台进行了些优化,然后在打出jar包的时候,突然想到以前都是对spring boot使用很熟练,但是从来都不知道spring boot打出的jar的启动原理,然后这回将jar解开了看了下,与想象中确实大不一样,以下就是对解压出来的jar的完整分析. 2.jar的结构 spring boot的应用程序就不贴出来了,一个较简单的demo打出的结构都是类似,另外我采用的spring boot的版本为1.4.1.RELEASE网上有另外一篇文章对spring
-
Spring Boot 文件上传原理解析
首先我们要知道什么是Spring Boot,这里简单说一下,Spring Boot可以看作是一个框架中的框架--->集成了各种框架,像security.jpa.data.cloud等等,它无须关心配置可以快速启动开发,有兴趣可以了解下自动化配置实现原理,本质上是 spring 4.0的条件化配置实现,深抛下注解,就会看到了. 说Spring Boot 文件上传原理 其实就是Spring MVC,因为这部分工作是Spring MVC做的而不是Spring Boot,那么,SpringMVC又是怎么
-
Spring Cloud Ribbon实现客户端负载均衡的方法
简介 我们继续以之前博客的代码为基础,增加Ribbon组件来提供客户端负载均衡.负载均衡是实现高并发.高性能.可伸缩服务的重要组成部分,它可以把请求分散到一个集群中不同的服务器中,以减轻每个服务器的负担.客户端负载均衡是运行在客户端程序中的,如我们的web项目,然后通过获取集群的IP地址列表,随机选择一个server发送请求.相对于服务端负载均衡来说,它不需要消耗服务器的资源. 基础环境 JDK 1.8 Maven 3.3.9 IntelliJ 2018.1 Git:项目源码 更新配置 我们这次
-
Spring Cloud Ribbon负载均衡器处理方法
接下来撸一撸负载均衡器的内部,看看是如何获取服务实例,获取以后做了哪些处理,处理后又是如何选取服务实例的. 分成三个部分来撸: 配置 获取服务 选择服务 配置 在上一篇<撸一撸Spring Cloud Ribbon的原理>的配置部分可以看到默认的负载均衡器是ZoneAwareLoadBalancer. 看一看配置类. 位置: spring-cloud-netflix-core-1.3.5.RELEASE.jar org.springframework.cloud.netflix.ribbon