Pandas实现在线文件和剪贴板数据读取详解
目录
- 前言
- read_html
- 在线文件1
- 在线文件2
- 读取在线CSV文件
- Pandas读取剪贴板
前言
大家好,我是Peter~
本文记录的是Pandas两种少用的读取文件方式:
- 读取在线文件的数据
- 读取剪贴板的数据
声明:本文案例和在线数据仅用于学术分享
read_html
该函数表示的是直接读取在线的html文件,一般是表格的形式;将HTML的表格转换为DataFrame的一种快速方便的方法。
这个方法对于快速合并来自不同网页上的表格非常有用,就省去了爬取数据再来读取的时间。
具体函数的参数为:
pandas.read_html(io, # 文件 io 对象;路径或者io.Strings对象 match='.+', # str 或编译的正则表达式,可选 flavor=None, # 要使用的解析引擎, None是默认值 header=None, # 文件表头 index_col=None, # 索引 skiprows=None, # 跳过行 attrs=None, # 属性 parse_dates=False, # 日期解析 thousands=',', # 千分位 encoding=None, # 编码 decimal='.', # 识别为小数点的字符 converters=None, # 属性转换 na_values=None, # 空值信息 keep_default_na=True, # 是否保持空值 displayed_only=True # 是否应该解析带有“display:none” 的元素 )
在线文件1
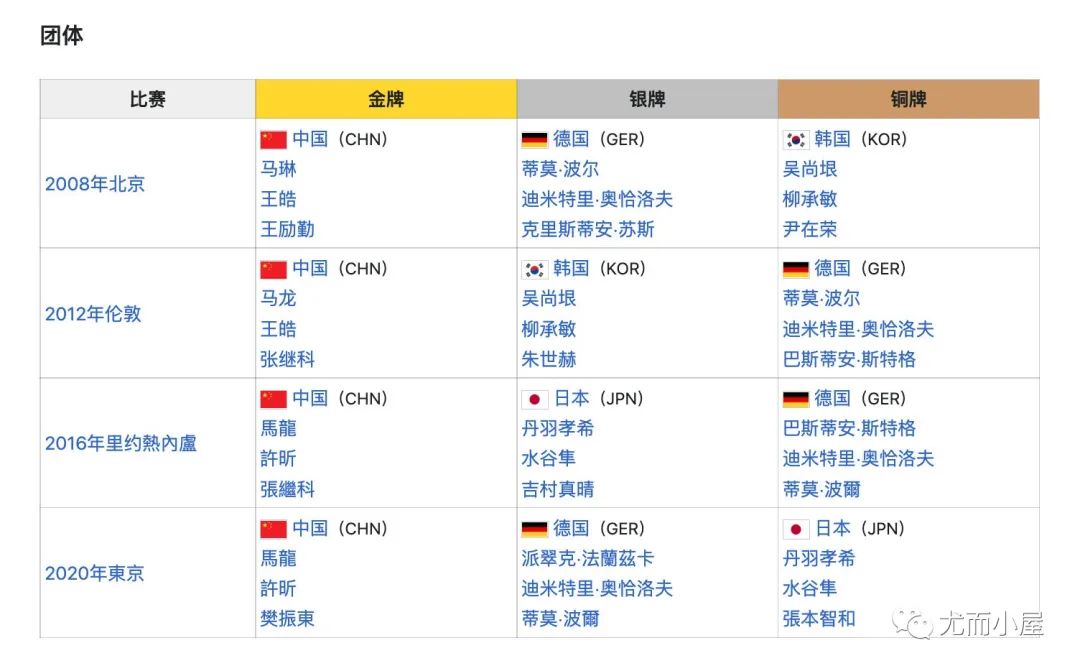
读取维基百科上一份历届奥运会乒乓球冠军的相关数据。该地址下的部分表格形式的数据:

In [3]:
url = "https://zh.m.wikipedia.org/zh/%E5%A5%A5%E6%9E%97%E5%8C%B9%E5%85%8B%E8%BF%90%E5%8A%A8%E4%BC%9A%E4%B9%92%E4%B9%93%E7%90%83%E5%A5%96%E7%89%8C%E5%BE%97%E4%B8%BB%E5%88%97%E8%A1%A8" df = pd.read_html(url) df
Out[3]:
我们观察到此时读取到的df是一个列表,总长度是15
list
In [4]:
len(df)
Out[4]:
9
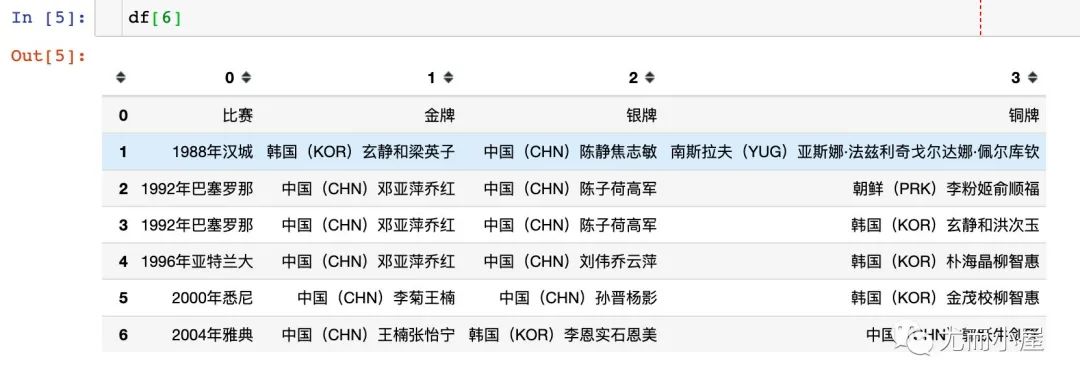
查看列表中的部分元素:此时就是一个个的DataFrame形式的数据

在线文件2
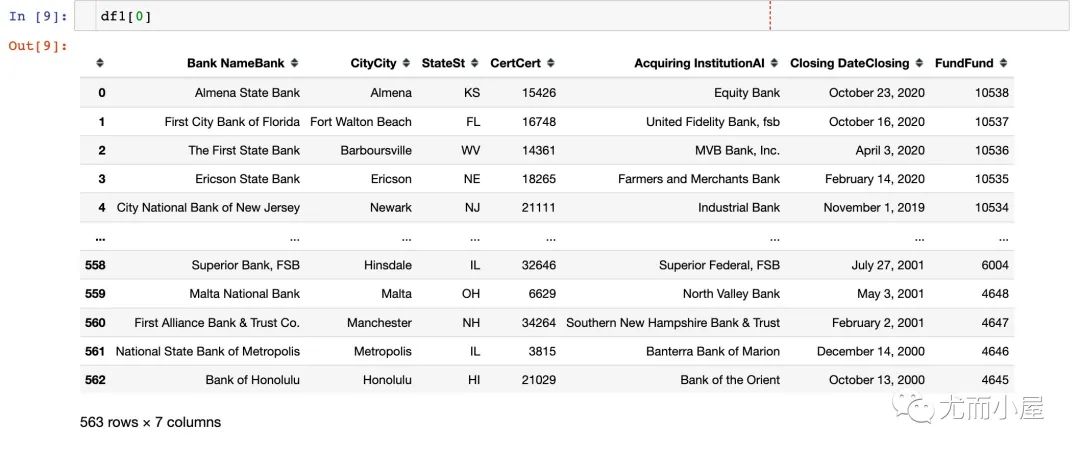
一个国外网站下的数据

In [7]:
df1 = pd.read_html("https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list")
type(df1)
Out[7]:
list
In [8]:
len(df1)
Out[8]:
1
In [9]:
df1[0]
Out[9]:
读取在线CSV文件
以读取GitHub上一个CSV文件为例:
方式1:直接读取
url="https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv" pd.read_csv(url)

方式2:通过io.Strings对象
url="https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
response=requests.get(url).content # 先发请求
df2 = pd.read_csv(io.StringIO(response.decode('utf-8')))
df2 # 效果同上
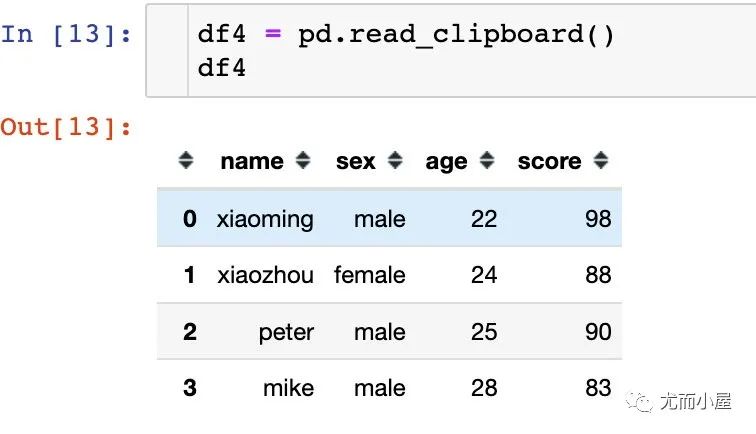
Pandas读取剪贴板
pandas.read_clipboard(sep='\\s+', **kwargs)

一个简单的例子说明函数使用:假设本地目录下有这样Excel表格的数据
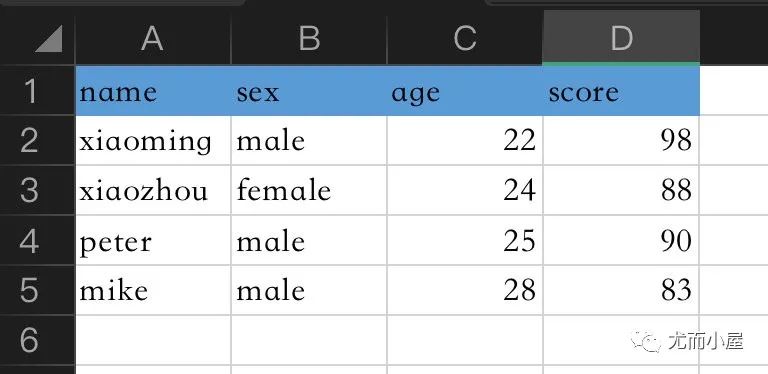
1、先剪贴数据:【Ctrl + C】

2、运行代码下面的代码,按下MacOS中的【向上的箭头】 + 【回车键】,完成读取
Windows下面应该是【Shift + Enter】
如果数据比较少,省去了通过Excel或者CSV文件的读取方式的时间:
以上就是Pandas实现在线文件和剪贴板数据读取详解的详细内容,更多关于Pandas数据读取的资料请关注我们其它相关文章!
相关推荐
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-

Python数据分析之pandas读取数据
一.三种数据文件的读取 二.csv.tsv.txt 文件读取 1)CSV文件读取: 语法格式:pandas.read_csv(文件路径) CSV文件内容如下: import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回
-
利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼.最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能. 首先分享一下数据集: 编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.7
-
pandas实现数据读取&清洗&分析的项目实践
目录 一.数据读取和写入 1.1 CSV和txt文件: 1.2 Excel文件: 1.3 MYSQL数据库: 二.数据清洗 2.1 清除不需要的行数据 2.2 清除不需要的列 2.3 调整列的展示顺序或列标签名 2.4 对行数据进行排序 2.5 空值的处理 2.6 数据去重处理 2.7 对指定列数据进行初步加工 2.8 对DataFrame内所有数据进行初步加工处理 2.9 设置数据格式 三.数据切片和筛选查询 3.1 行切片 3.2 列切片 3.3 数据筛选和查询 3.4 遍历 四.数据简单统
-
pandas读取CSV文件时查看修改各列的数据类型格式
下面给大家介绍下pandas读取CSV文件时查看修改各列的数据类型格式,具体内容如下所述: 我们在调bug的时候会经常查看.修改pandas列数据的数据类型,今天就总结一下: 1.查看: Numpy和Pandas的查看方式略有不同,一个是dtype,一个是dtypes print(Array.dtype) #输出int64 print(df.dtypes) #输出Df下所有列的数据格式 a:int64,b:int64 2.修改 import pandas as pd import numpy a
-
Pandas实现在线文件和剪贴板数据读取详解
目录 前言 read_html 在线文件1 在线文件2 读取在线CSV文件 Pandas读取剪贴板 前言 大家好,我是Peter~ 本文记录的是Pandas两种少用的读取文件方式: 读取在线文件的数据 读取剪贴板的数据 声明:本文案例和在线数据仅用于学术分享 read_html 该函数表示的是直接读取在线的html文件,一般是表格的形式:将HTML的表格转换为DataFrame的一种快速方便的方法. 这个方法对于快速合并来自不同网页上的表格非常有用,就省去了爬取数据再来读取的时间. 具体函数的参
-
对pandas的行列名更改与数据选择详解
记录一些pandas选择数据的内容,此前首先说行列名的获取和更改,以方便获取数据.此文作为学习巩固. 这篇博的内容顺序大概就是: 行列名的获取 -> 行列名的更改 -> 数据选择 一.pandas的行列名获取和更改 1. 获取: df.index() df.columns() 首先,举个例子,做一个DataFrame如下: >>>import pandas as pd >>>import numpy as np >>>data = pd.D
-
对python读取zip压缩文件里面的csv数据实例详解
利用zipfile模块和pandas获取数据,代码比较简单,做个记录吧: # -*- coding: utf-8 -*- """ Created on Tue Aug 21 22:35:59 2018 @author: FanXiaoLei """ from zipfile import ZipFile import pandas as pd myzip=ZipFile('2.zip') f=myzip.open('2.csv') df=pd.r
-
python数据分析之文件读取详解
目录 前言: 一·Numpy库中操作文件 二·Pandas库中操作文件 三·补充 总结 前言: 如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作csv文件 import numpy as np a=np.random.randint(0,10,size=(3,4)) np.savetext("score.csv",a,deliminte
-
tensorflow入门:TFRecordDataset变长数据的batch读取详解
在上一篇文章tensorflow入门:tfrecord 和tf.data.TFRecordDataset的使用里,讲到了使用如何使用tf.data.TFRecordDatase来对tfrecord文件进行batch读取,即使用dataset的batch方法进行:但如果每条数据的长度不一样(常见于语音.视频.NLP等领域),则不能直接用batch方法获取数据,这时则有两个解决办法: 1.在把数据写入tfrecord时,先把数据pad到统一的长度再写入tfrecord:这个方法的问题在于:若是有大量
-
使用 Python 读取电子表格中的数据实例详解
Python 是最流行.功能最强大的编程语言之一.由于它是自由开源的,因此每个人都可以使用.大多数 Fedora 系统都已安装了该语言.Python 可用于多种任务,其中包括处理逗号分隔值(CSV)数据.CSV文件一开始往往是以表格或电子表格的形式出现.本文介绍了如何在 Python 3 中处理 CSV 数据. CSV 数据正如其名.CSV 文件按行放置数据,数值之间用逗号分隔.每行由相同的字段定义.简短的 CSV 文件通常易于阅读和理解.但是较长的数据文件或具有更多字段的数据文件可能很难用肉眼
-
Python学习之文件的读取详解
目录 文件读取的模式 文件对象的读取方法 使用 read() 函数一次性读取文件全部内容 使用 readlines() 函数 读取文件内容 使用 readline() 函数 逐行读取文件内容 mode().name().closed() 函数演示 文件读取小实战 with open() 函数 利用with open() 函数读取文件的小实战 上一章节 我们学习了如何利用 open() 函数创建一个文件,以及如何在文件内写入内容:今天我们就来了解一下如何将文件中的内容读取出去来的方法. 文件读取的
-
Python学习之yaml文件的读取详解
目录 yaml 文件的应用场景与格式介绍 yaml 文件的应用场景 yaml 文件的格式 第三方包 - pyyaml 读取 yaml 文件的方法 yaml文件读取演示案例 yaml 文件的应用场景与格式介绍 yaml 文件的应用场景 yaml其实也类似于 json.txt ,它们都属于一种文本格式.在我们的实际工作中, yaml 文件经常作为服务期配置文件来使用. 比如一些定义好的内容,并且不会修改的信息,我们就可以通过定义 yaml 文件,然后通过读取这样的文件,将数据导入到我们的服务中进行使
-
C/C++实现segy文件的读取详解
目录 1头文件ReadSeismic.h的编写及其规范 1.1程序描述.调用.声明.定义 1.2声明函数 1.3完整代码 2C++文件ReadSeismic.cpp的编写及其规范 2.1必要的说明 2.2定义读.写函数 2.3完整代码 3主函数main.cpp及运行结果 本文档将介绍SEGY的读取与写入过程,其中包括IBM与PC两种数据格式的转换. 程序将调用IEEE2IBM.cpp文件完成IBM与PC格式的互相转换. 新建头文件ReadSeismic.h与C++文件ReadSeismic.cp
-
Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr