Python实现获取弹幕的两种方式分享
目录
- 前言
- 环境
- 获取方式一: <简单, 但是弹幕很少>
- 请求数据
- 获取数据
- 解析数据
- 保存数据
- 获取方式二: <复杂一点点, 弹幕比较多,按日期来>
- 请求数据
- 解析数据
- 翻页
- 保存数据
前言
弹幕可以给观众一种“实时互动”的错觉,虽然不同弹幕的发送时间有所区别,但是其只会在视频中特定的一个时间点出现,因此在相同时刻发送的弹幕基本上也具有相同的主题,在参与评论时就会有与其他观众同时评论的错觉。
在国内的视频网站里,弹幕先是从A站被大家知道,随后B站发扬光大,导致现在全部视频平台和部分漫画平台都有弹幕功能,在欣赏动漫的同时,还能看一下大家的看法,也是一件非常有趣的事。
现在,弹幕文化成为了很多人看视频的习惯,今天就教大家如何获取弹幕的数据
环境
- python 3.8
- pycharm
- requests
- re
获取方式一: <简单, 但是弹幕很少>
先打开网站,找到你想要的视频,然后在网址bili前加个i,这样你就可以直接的找到弹幕的地址
复制地址打开,你就可以看到你想要的弹幕数据,写代码时直接请求这个地址就可以了
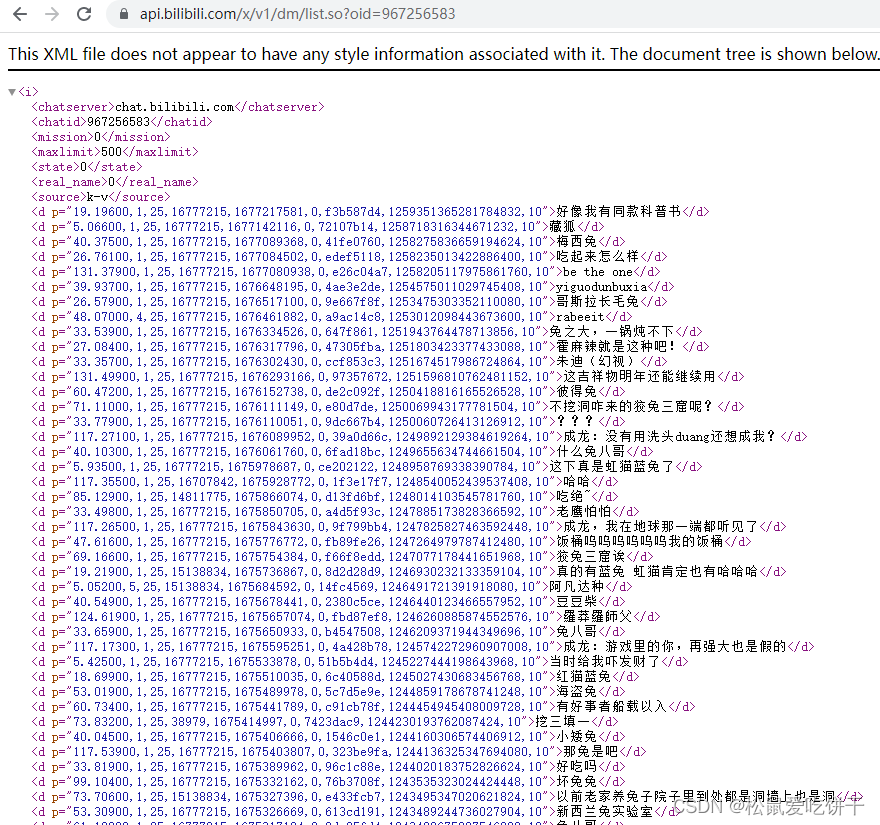
请求数据
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=967256583'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response)

获取数据
response.encoding = 'utf-8' print(response.text)
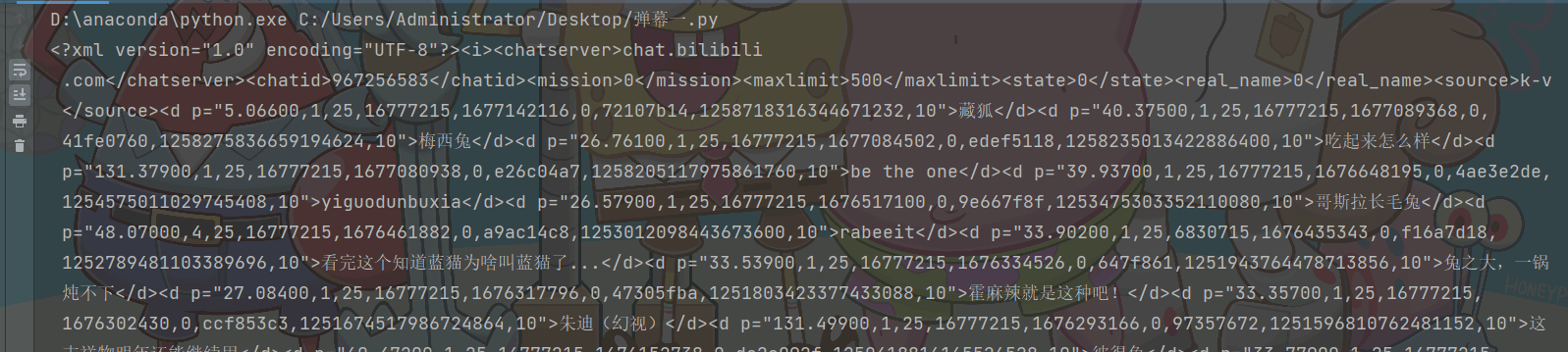
解析数据
content_list = re.findall('<d p=".*?">(.*?)</d>', response.text)
content = '\n'.join(content_list)
print(content_list)

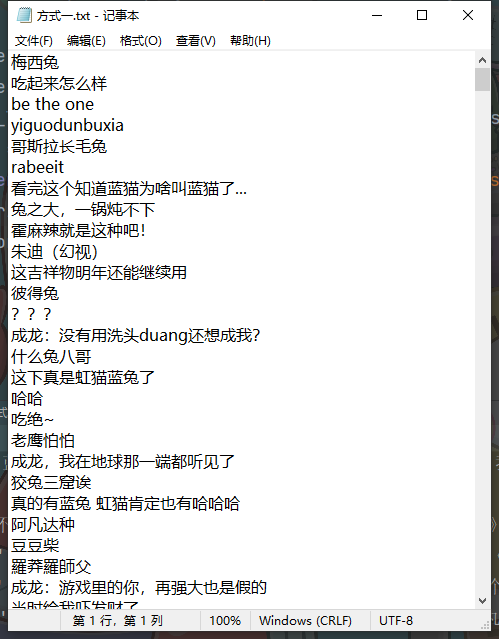
保存数据
with open('方式一.txt', mode='a', encoding='utf-8') as f:
f.write(content)
获取方式二: <复杂一点点, 弹幕比较多,按日期来>
先回到视频播放地址,打开开发者工具,选择其他日期天数,然后会出现带有当天日期的数据包,右边就是我们要找的url地址
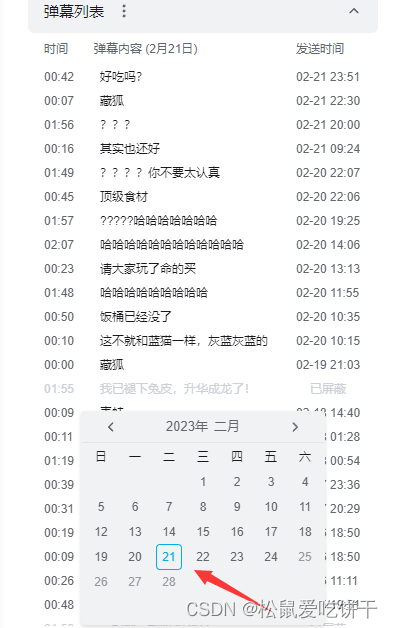
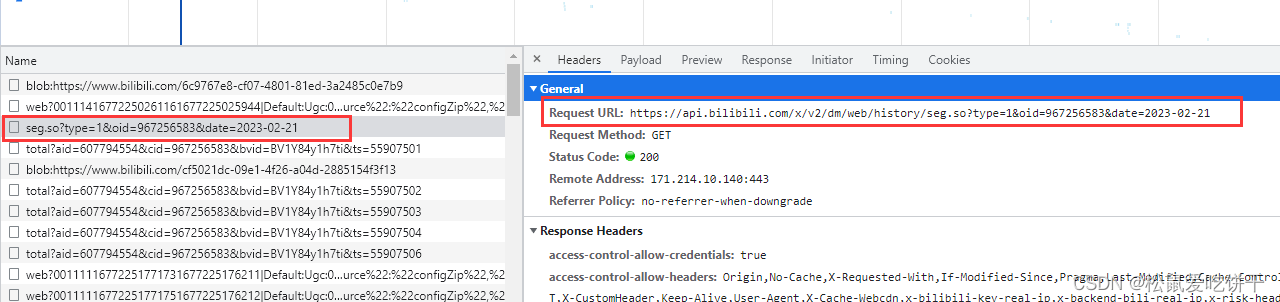
也出现了乱码的弹幕数据

请求数据
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=967256583&date=2023-02-23'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
'cookie': '加自己的'
}
response = requests.get(url=url, headers=headers)
解析数据
content_list = re.findall('[\u4e00-\u9fa5]+', response.text)
content = '\n'.join(content_list)
翻页
for page in range(1, 24):
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=967256583&date=2023-02-{page}'
保存数据
with open('方式二.txt', mode='a', encoding='utf-8') as f:
f.write(content)
print(content_list)
到此这篇关于Python实现获取弹幕的两种方式分享的文章就介绍到这了,更多相关Python获取弹幕内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫自动化爬取b站实时弹幕实例方法
最近央视新闻记者王冰冰以清除可爱和专业的新闻业务水平深受众多网友喜爱,b站也有很多up主剪辑了关于王冰冰的视频.我们都是知道b站是一个弹幕网站,那你知道如何爬取b站实时弹幕吗?本文以王冰冰视频弹幕为例,向大家介绍Python爬虫实现自动化爬取b站实时弹幕的过程. 1.导入需要的库 import jieba # 分词 from wordcloud import WordCloud # 词云 from PIL import Image # 图片处理 import numpy as np # 图片处理
-

python3写爬取B站视频弹幕功能
需要准备的环境: 一个B站账号,需要先登录,否则不能查看历史弹幕记录 联网的电脑和顺手的浏览器,我用的Chrome Python3环境以及request模块,安装使用命令,换源比较快: pip3 install request -i http://pypi.douban.com/simple 爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求 点击查看历史弹幕,获取请求 其中rolldate后面的数字表示该视频对应的弹幕号,返
-
你会使用python爬虫抓取弹幕吗
目录 前言 一.爬虫是什么? 二.饲养步骤 1.请求弹幕 2.解析弹幕 3.存储弹幕 4.总代码 三.总结 前言 时隔108天,何同学在B站发布了最新的视频,<[何同学]我用108天开了个灯…>.那么就让我们用爬虫,爬取视频的弹幕,看看小伙伴们是怎么评价的吧 一.爬虫是什么? 百度百科这样说:自动获取网页内容的程序.在我理解看来,爬虫就是~~“在网络上爬来爬去的…”住口!~~那么接下来就让我们看看如何养搬运B站弹幕的“虫”吧 二.饲养步骤 1.请求弹幕 首先,得知道爬取的网站url是什么.对于
-
Python实现获取弹幕的两种方式分享
目录 前言 环境 获取方式一: <简单, 但是弹幕很少> 请求数据 获取数据 解析数据 保存数据 获取方式二: <复杂一点点, 弹幕比较多,按日期来> 请求数据 解析数据 翻页 保存数据 前言 弹幕可以给观众一种“实时互动”的错觉,虽然不同弹幕的发送时间有所区别,但是其只会在视频中特定的一个时间点出现,因此在相同时刻发送的弹幕基本上也具有相同的主题,在参与评论时就会有与其他观众同时评论的错觉. 在国内的视频网站里,弹幕先是从A站被大家知道,随后B站发扬光大,导致现在全部视频平台和部
-
Python操作MySQL数据库的两种方式实例分析【pymysql和pandas】
本文实例讲述了Python操作MySQL数据库的两种方式.分享给大家供大家参考,具体如下: 第一种 使用pymysql 代码如下: import pymysql #打开数据库连接 db=pymysql.connect(host='1.1.1.1',port=3306,user='root',passwd='123123',db='test',charset='utf8') cursor=db.cursor()#使用cursor()方法获取操作游标 sql = "select * from tes
-
Python实现图片裁剪的两种方式(Pillow和OpenCV)
在这篇文章里我们聊一下Python实现图片裁剪的两种方式,一种利用了Pillow,还有一种利用了OpenCV.两种方式都需要简单的几行代码,这可能也就是现在Python那么流行的原因吧. 首先,我们有一张原始图片,如下图所示: 原始图片 然后,我们利用OpenCV对其进行裁剪,代码如下所示: import cv2 img = cv2.imread("./data/cut/thor.jpg") print(img.shape) cropped = img[0:128, 0:512] #
-
Spring实现Aware接口自定义获取bean的两种方式
在使用spring编程时,常常会遇到想根据bean的名称来获取相应的bean对象,这时候,就可以通过实现BeanFactoryAware来满足需求,代码很简单: @Servicepublic class BeanFactoryHelper implements BeanFactoryAware { private static BeanFactory beanFactory; @Override public void setBeanFactory(BeanFactory beanFactory
-
对Python中创建进程的两种方式以及进程池详解
在Python中创建进程有两种方式,第一种是: from multiprocessing import Process import time def test(): while True: print('---test---') time.sleep(1) if __name__ == '__main__': p=Process(target=test) p.start() while True: print('---main---') time.sleep(1) 上面这段代码是在window
-
Hibernate中获取Session的两种方式代码示例
Session:是应用程序与数据库之间的一个会话,是Hibernate运作的中心,持久层操作的基础.对象的生命周期/事务的管理/数据库的存取都与Session息息相关. Session对象是通过SessionFactory构建的,下面举个例子来介绍Hibernate两种获取session的方式. 日志,是编程中很常见的一个关注点.用户在对数据库进行操作的过程需要将这一系列操作记录,以便跟踪数据库的动态.那么一个用户在向数据库插入一条记录的时候,就要向日志文件中记录一条记录,用户的一系列操作都要在
-
Go语言读取YAML 配置文件的两种方式分享
目录 前言 yaml.v3 包 读取 yaml 文件 viper 包 读取 yaml 文件 小结 前言 在日常开发中,YAML 格式的文件基本上被默认为是配置文件,其内容因为缩进带来的层级感看起来非常直观和整洁.本文将会对 YAML 内容的读取进行介绍. yaml.v3 包 yaml.v3 的包,可以让我们在 Go 里面轻松地操作 yaml 格式的数据(如将 yaml 格式转成结构体等).在使用 yaml.v3 包之前,我们需要先安装它: go get gopkg.in/yaml.v3 读取 y
-
python连接clickhouse数据库的两种方式小结
目录 python连接clickhouse数据库 主要针对clickhouse_driver的使用进行简要介绍 python将数据写入clickhouse python连接clickhouse数据库 在Python中获取系统信息的一个好办法是使用psutil这个第三方模块. 顾名思义,psutil = process and system utilities,它不仅可以通过一两行代码实现系统监控,还可以跨平台使用. 主要针对clickhouse_driver的使用进行简要介绍 第一步: 通过pi
-
vue使用json最简单的两种方式分享
目录 使用json最简单方式 第一种 第二种 vue使用json假数据 第一种json数据写在js文件中直接引入使用 第二种使用json-server ./xxx.json 使用 生成请求接口 使用json最简单方式 第一种 首先我项目是在 webpack 下搭建的vue项目 在public文件夹下创建jsonTest.json json 格式的数据如下: { "innerList": [ {"attr1":"内部数据1"
-
详解python中字典的循环遍历的两种方式
开发中经常会用到对于字典.列表等数据的循环遍历,但是python中对于字典的遍历对于很多初学者来讲非常陌生,今天就来讲一下python中字典的循环遍历的两种方式. 注意: python2和python3中,下面两种方法都是通用的. 1. 只对键的遍历 一个简单的for语句就能循环字典的所有键,就像处理序列一样: d = {'name1' : 'pythontab', 'name2' : '.', 'name3' : 'com'} for key in d: print (key, ' value