Flink作业Task运行源码解析
目录
- 引言
- 概览
- 调度框架
- JobMaster
- ScheduleNG
- TaskExecutor
- Task
- 计算框架
- 算子计算处理
- 总结
引言
上一篇我们分析了Flink部署集群的过程和作业提交的方式,本篇我们来分析下,具体作业是如何被调度和计算的。具体分为2个部分来介绍
- 作业运行的整体框架,对相关的重要角色有深入了解
- 计算流程,重点是如何调度具体的operator机制
概览
首先我们来了解下整体的框架 JobMaster: 计算框架的主节点,负责运行单个JobGraph,包括任务的调度,资源申请和TaskManager的管理等。 TaskExecutor: 负责多个Task的具体执行 Dispatcher接收到submitJob的请求后,会生成一个JobMaster实例(具体为Dispatcher创建JobManagerRunner,JobManagerRunner创建JobMaster),下面来具体介绍下JobMaster和TaskExecutor的内部信息
调度框架
JobMaster
private final SchedulerNG schedulerNG;
private final ShuffleMaster<?> shuffleMaster;
private final SlotPoolService slotPoolService;
private final LeaderRetrievalService resourceManagerLeaderRetriever;
private final BlobWriter blobWriter;
private final JobMasterPartitionTracker partitionTracker;
private HeartbeatManager<TaskExecutorToJobManagerHeartbeatPayload, AllocatedSlotReport>
taskManagerHeartbeatManager;
private HeartbeatManager<Void, Void> resourceManagerHeartbeatManager;
JobMaster作为整个任务调度计算的主节点,需要和一些外部角色进行交互,具体的如下:
- resourceManagerLeaderRetriever: 负责和resourceManager间的通讯
- slotPoolService: 用于管理slotpool的,slot资源管理,负责slot的申请、释放等。
- partitionTracker: 负责算子计算结果数据分区的跟踪
- schedulerNG:内部的调度引擎,负责job的调度处理
- shuffleMaster: 数据shuffle处理
- taskManagerHeartbeatManager:记录和taskManager间的心跳信息,
- resourceManagerHeartbeatManager:记录和resourceManager间的心跳
ScheduleNG
ScheduleNG实际负责job调度处理,包括生成ExecutionGraph,作业的调度执行,任务出错处理等。其实现类为DefaultScheduler
- SchedulingStrategy:任务调度的策略,实现类为PipelinedRegionSchedulingStrategy,按pipeline region的粒度来调度任务
- ExecutionGraphFactory:其实现类为DefaultExecutionGraphFactory,创建ExecutionGraph的工厂类
TaskExecutor
实际任务运行的节点,该类负责多个任务的运行,首先我们看看其实现了TaskExecutorGateway接口,TaskExecutorGateway定义了各类可以调用的功能接口,具体内容见下表
| 分类 | 方法名 | 说明 |
|---|---|---|
| Task操作相关 | SubmitTask | 向TaskExecutor提交任务 |
| Task操作相关 | cancelTask | 取消指定的任务 |
| Task操作相关 | sendOperatorEventToTask | 发送算子事件给Task |
| Slot操作相关 | requestSlot | 给指定的Job分配指定的slot |
| Slot操作相关 | freeSlot | 释放对应的slot |
| Slot操作相关 | freeInactiveSlots | 释放指定Job的未使用的slot |
| Partition操作相关 | updatePartitions | 更新分区信息 |
| Partition操作相关 | releaseOrPromotePartitions | 批量释放或保留分区 |
| Partition操作相关 | releaseClusterPartitions | 释放属于给定datasets的所有集群分区数据 |
| checkpoint操作相关 | triggerCheckpoint | 触发指定任务的checkpoint处理 |
| checkpoint操作相关 | confirmCheckpoint | 确认指定任务的checkpoint |
| checkpoint操作相关 | abortCheckpoint | 终止给定任务的checkpoint |
Task
一个Task负责TaskManager上一个subtask的一次执行,Task对Flink Operator进行包装然后运行,并提供需要的各类服务,如消费输入数据,生产数据以及和JobManager通讯。Task实现了Runnable接口,即通过一个单独的线程来运行,而其中的Flink Operator部分封装在实现了TaskInvokable接口的类中,实现类主要为SourceStreamTask和OneInputStreamTask。下面分别详细介绍下这几个类
- Task: 对应为一个线程,来运行具体的Operator的逻辑,并包括相关的其他的辅助功能,包括如执行状态的管理、结果数据管理(ResultPartitionWriters)、输入数据(IndexInputGate)以及生成封装了Operator逻辑的TaskInvokable实例并运行
- TaskInvokable:封装了具体Operator的处理逻辑,主要包括有2个方法,restore()和invoke()。restore()方法在invoke()之前调用,用于恢复上次的有效状态。invoke()方法执行具体的处理逻辑。下面我们看看其实现子类(这里只列了与StreamGraph相关的实现类,对于其他的子类没有展示)
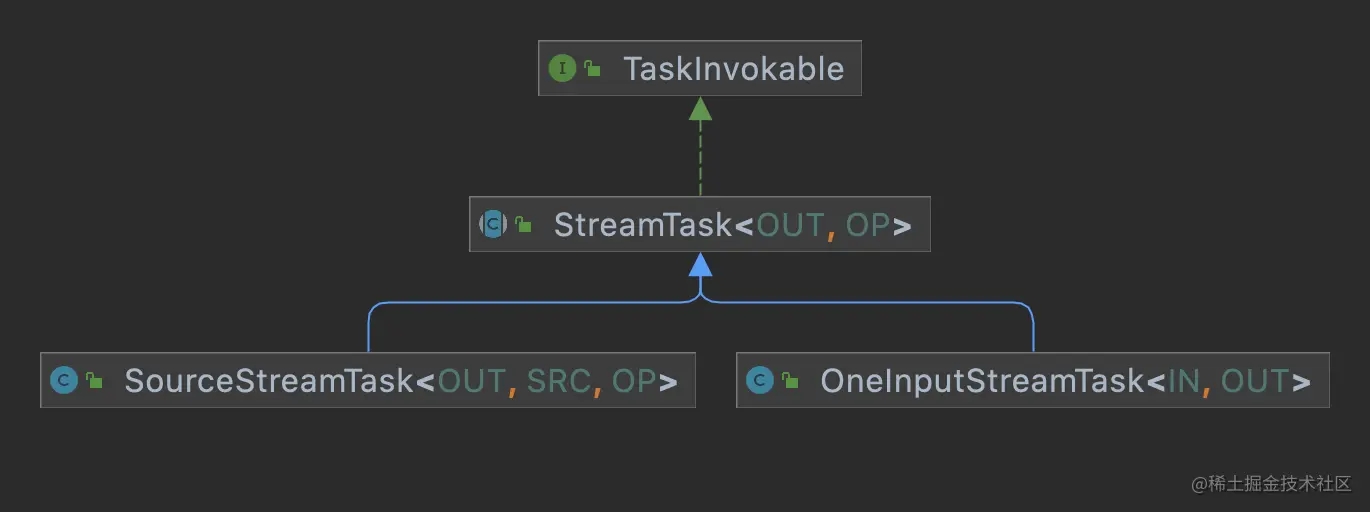
- SourceStreamTask:用于执行StreamSource,即源头的读取数据类Operator
- OneInputStreamTask:用于执行OneInputStreamOperator,即只有一个输入的operator
- TwoInputStreamTask: 用于执行TwoInputStreamOperator,有2个输入的operator
- MultipleInputStreamTask: 用于执行MultipleInputStreamOperator,有多个输入的operator
计算框架
计算框架这节主要来了解数据是如何在Flink中如何处理和流转的。这里我们主要回答以下几个问题:
- Flink中整个数据的处理流程,单条数据是如何在各个算子间流转和处理的
- 对于算子chain和其他算子其底层实现区别是怎样的,为何chain后的效率会高 我们先以StreamMap算子为例来看整体计算框架的设计
public class StreamMap<IN, OUT> extends AbstractUdfStreamOperator<OUT, MapFunction<IN, OUT>>
implements OneInputStreamOperator<IN, OUT> {
private static final long serialVersionUID = 1L;
public StreamMap(MapFunction<IN, OUT> mapper) {
super(mapper);
chainingStrategy = ChainingStrategy.ALWAYS;
}
@Override
public void processElement(StreamRecord<IN> element) throws Exception {
output.collect(element.replace(userFunction.map(element.getValue())));
}
}
这里StreamMap实现了Input接口,其中在实现的processElement()方法中实现了具体的对具体数据的操作处理(Operator),并将结果通过Output接口的collect()方法发射出去。我们先看看这2个接口定义的方法
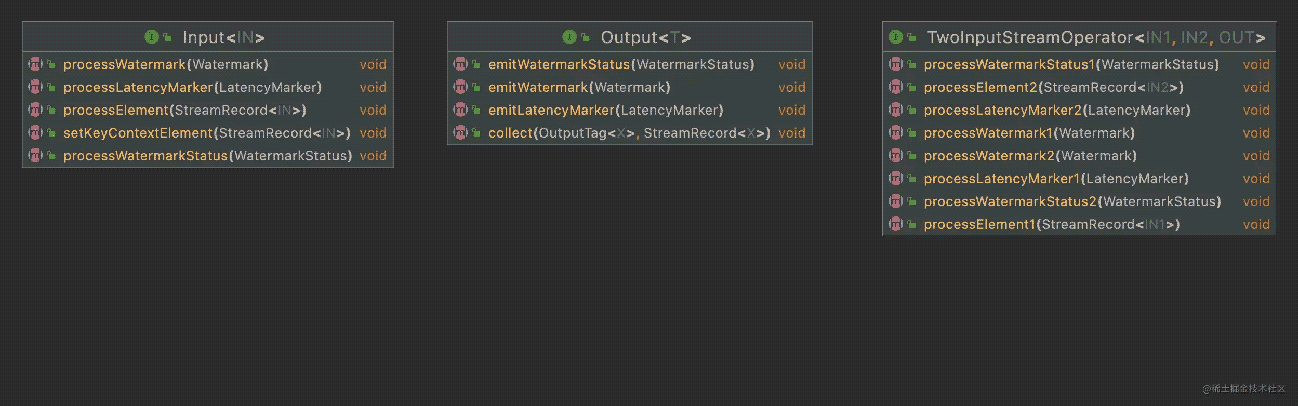
基本上2边是一一对应的关系,Input负责处理Element\Watermark\WatermarkStatus\LatencyMarker,而Output负责emit这些。这里Input是处理一个输入的,如果是2个输入那对应的就是TwoInputStreamOperator
算子计算处理
对于Chain的操作,是通过Output接口的实现类ChainingOutput.java
// ChainingOutput.java
@Override
public void collect(StreamRecord<T> record) {
pushToOperator(record);
}
protected <X> void pushToOperator(StreamRecord<X> record) {
try {
...
input.setKeyContextElement(castRecord);
input.processElement(castRecord);
} catch (Exception e) {
throw new ExceptionInChainedOperatorException(e);
}
这里可以看到在output.collect()方法中把数据再推送到了算子,然后算子(input)继续执行processElement()这样来实现了在当前线程内的pipeline处理,
总结
本篇我们介绍了Flink是如何来执行相应的算子来实现计算的,主要介绍了TaskExecutor运行的Task实现,以及chain算子是如何串行来运行的。对于算子之间的数据交互这块我们后面一篇来单独介绍。
以上就是Flink作业Task运行源码解析的详细内容,更多关于Flink作业Task运行的资料请关注我们其它相关文章!
相关推荐
-

Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
Flink状态和容错源码解析
目录 引言 概述 State Keyed State 状态实例管理及数据存储 HeapKeyedStateBackend RocksDBKeyedStateBackend OperatorState 上层封装 总结 引言 计算模型 DataStream基础框架 事件时间和窗口 状态和容错 部署&调度 存储体系 底层支撑 Flink中提供了State(状态)这个概念来保存中间计算结果和缓存数据,按照不同的场景,Flink提供了多种不同类型的State,同时为了实现Exactly once的语义,F
-
Flink JobGraph生成源码解析
目录 引言 概念 JobGraph生成 生成hash值 生成chain 总结 引言 在DataStream基础中,由于其中的内容较多,只是介绍了JobGraph的结果,而没有涉及到StreamGraph到JobGraph的转换过程.本篇我们来介绍下JobGraph的生成的详情,重点是Operator可以串联成Chain的条件 概念 首先我们来回顾下JobGraph中的相关概念 JobVertex:job的顶点,即对应的计算逻辑(这里用的是Vertex, 而前面用的是Node,有点差异),通过in
-
Flink DataStream基础框架源码分析
目录 引言 概览 深入DataStream DataStream 属性和方法 类体系 Transformation 属性和方法 类体系 StreamOperator 属性和方法 类体系 Function DataStream生成提交执行的Graph StreamGraph 属性和方法 StreamGraph生成 JobGraph 属性和方法 总结 引言 希望通过对Flink底层源码的学习来更深入了解Flink的相关实现逻辑.这里新开一个Flink源码解析的系列来深入介绍底层源码逻辑.说明:这里默
-
详解Flink同步Kafka数据到ClickHouse分布式表
目录 引言 什么是ClickHouse? 创建复制表 通过jdbc写入 引言 业务需要一种OLAP引擎,可以做到实时写入存储和查询计算功能,提供高效.稳健的实时数据服务,最终决定ClickHouse 什么是ClickHouse? ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS). 列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解),图片来源于ClickHouse中文官方文档. 行式 列
-
Flink时间和窗口逻辑处理源码分析
目录 概览 时间 重要类 WatermarkStrategy WatermarkGenerator TimerService 处理逻辑 窗口 重要类 Window WindowAssigner Triger Evictor WindowOperator InternalAppendingState 处理逻辑 总结 概览 计算模型 DataStream基础框架 事件时间和窗口 部署&调度 存储体系 底层支撑 在实时计算处理时,需要跟时间来打交道,如实时风控场景的时间行为序列,实时分析场景下的时间窗
-
Flink部署集群整体架构源码分析
目录 概览 部署模式 Application mode 客户端提交请求 服务端启动&提交Application session mode Cluster架构 Cluster的启动流程 DispatcherResourceManagerComponent Runner代码 HA代码框架 总结 概览 本篇我们来了解Flink的部署模式和Flink集群的整体架构 部署模式 Flink支持如下三种运行模式 运行模式 描述 Application Mode Flink Cluster只执行提交的整个job
-
Flink作业Task运行源码解析
目录 引言 概览 调度框架 JobMaster ScheduleNG TaskExecutor Task 计算框架 算子计算处理 总结 引言 上一篇我们分析了Flink部署集群的过程和作业提交的方式,本篇我们来分析下,具体作业是如何被调度和计算的.具体分为2个部分来介绍 作业运行的整体框架,对相关的重要角色有深入了解 计算流程,重点是如何调度具体的operator机制 概览 首先我们来了解下整体的框架 JobMaster: 计算框架的主节点,负责运行单个JobGraph,包括任务的调度,资源申请
-
Kubernetes controller manager运行机制源码解析
目录 Run StartControllers ReplicaSet ReplicaSetController syncReplicaSet Summary Run 确立目标 理解 kube-controller-manager 的运行机制 从主函数找到run函数,代码较长,这里精简了一下 func Run(c *config.CompletedConfig, stopCh <-chan struct{}) error { // configz 模块,在kube-scheduler分析中已经了解
-
深度源码解析Java 线程池的实现原理
java 系统的运行归根到底是程序的运行,程序的运行归根到底是代码的执行,代码的执行归根到底是虚拟机的执行,虚拟机的执行其实就是操作系统的线程在执行,并且会占用一定的系统资源,如CPU.内存.磁盘.网络等等.所以,如何高效的使用这些资源就是程序员在平时写代码时候的一个努力的方向.本文要说的线程池就是一种对 CPU 利用的优化手段. 线程池,百度百科是这么解释的: 线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务.线程池线程都是后台线程.每个线程都使用默认的
-
Java 线程池ThreadPoolExecutor源码解析
目录 引导语 1.整体架构图 1.1.类结构 1.2.类注释 1.3.ThreadPoolExecutor重要属性 2.线程池的任务提交 3.线程执行完任务之后都在干啥 4.总结 引导语 线程池我们在工作中经常会用到.在请求量大时,使用线程池,可以充分利用机器资源,增加请求的处理速度,本章节我们就和大家一起来学习线程池. 本章的顺序,先说源码,弄懂原理,接着看一看面试题,最后看看实际工作中是如何运用线程池的. 1.整体架构图 我们画了线程池的整体图,如下: 本小节主要就按照这个图来进行 Thre
-
JetCache 缓存框架的使用及源码解析(推荐)
目录 一.简介 为什么使用缓存? 使用场景 使用规范 二.如何使用 引入maven依赖 添加配置 配置说明 注解说明 @EnableCreateCacheAnnotation @EnableMethodCache @CacheInvalidate @CacheUpdate @CacheRefresh @CachePenetrationProtect @CreateCache 三.源码解析 项目的各个子模块 常用注解与变量 缓存API Cache接口 AbstractCache抽象类 Abstra
-
Android10 App 启动分析进程创建源码解析
目录 正文 RootActivityContainer ActivityStartController 调用startActivityUnchecked方法 ActivityStackSupervisor 启动进程 RuntimeInit.applicationInit这个方法 正文 从前文# Android 10 启动分析之SystemServer篇 (四)中可以得知,系统在完成所有的初始化工作后,会通过 mAtmInternal.startHomeOnAllDisplays(currentU
-
Java源码解析之object类
在源码的阅读过程中,可以了解别人实现某个功能的涉及思路,看看他们是怎么想,怎么做的.接下来,我们看看这篇Java源码解析之object的详细内容. Java基类Object java.lang.Object,Java所有类的父类,在你编写一个类的时候,若无指定父类(没有显式extends一个父类)编译器(一般编译器完成该步骤)会默认的添加Object为该类的父类(可以将该类反编译看其字节码,不过貌似Java7自带的反编译javap现在看不到了). 再说的详细点:假如类A,没有显式继承其他类,编译