Pandas中根据条件替换列中的值的四种方式
目录
- 方法1:使用dataframe.loc[]函数
- 方法2:使用NumPy.where()函数
- 方法3:使用pandas掩码函数
- 方法4:替换包含指定字符的字符串
方法1:使用dataframe.loc[]函数
通过这个方法,我们可以用一个条件或一个布尔数组来访问一组行或列。如果我们可以访问它,我们也可以操作它的值,是的!这是我们的第一个方法,通过pandas中的dataframe.loc[]函数,我们可以访问一个列并通过一个条件改变它的值。
语法:df.loc[ df["column_name"] == "some_value", "column_name" ] = "value"
some_value = 需要被替换的值 value = 应该被放置的值。
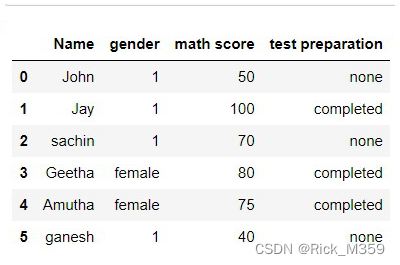
示例: 我们要把性别栏中的所有 “男性 “改为1。
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用
df.loc[df["gender"] == "male", "gender"] = 1
输出:
使用dataframe.loc[]函数
方法2:使用NumPy.where()函数
NumPy是一个非常流行的库,用于2D和3D数组的计算。它为我们提供了一个非常有用的方法where()来访问有条件的特定行或列。我们也可以用这个函数来改变某一列的特定值。 语法: df[“column_name”] = np.where(df[“column_name”]==”some_value”, value_if_true, value_if_false)
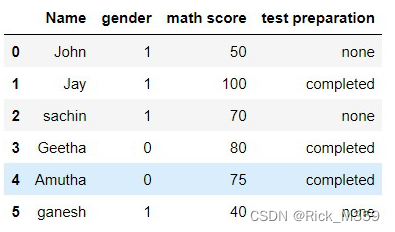
示例: 这个numpy.where()函数应该写上条件,如果条件为真,后面是值,如果条件为假,则是一个值。现在,我们要把性别栏中的所有 “女性 “改为0,”男性 “改为1。
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用
df["gender"] = np.where(df["gender"] == "female", 0, 1)
输出:
使用NumPy.where()函数
方法3:使用pandas掩码函数
Pandas的掩蔽函数是为了用一个条件替换任何行或列的值。
语法: df[‘column_name’].mask( df[‘column_name’] == ‘some_value’, value , inplace=True )
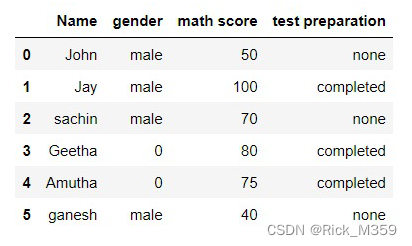
示例:使用这个屏蔽条件,将性别栏中所有的 “女性 “改为0。
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用 1
df['gender'].mask(df['gender'] == 'female', 0, inplace=True)
# 条件应用 2
#df['math score'].mask(df['math score'] >=60 ,'good', inplace=True)
输出:
使用pandas掩码函数
方法4:替换包含指定字符的字符串
语法 : data["列名"].mask(data.列名.str.contains(".*?某字符串"), "替换目标字符串", inplace=True)
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, '良70', 80, '良75', 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用
data["math score"].mask(data.math score.str.contains(".*?良"), "良好", inplace=True)
使用pandas掩码函数
到此这篇关于Pandas中根据条件替换列中的值的四种方式的文章就介绍到这了,更多相关Pandas 条件替换列值内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas替换NaN值的方法实现
目录 问题 方法 替换 NaN 值的步骤 参考 替换Pandas DataFram中的 NaN 值 问题 NaN 代表 Not A Number,是表示数据中缺失值的常用方法之一.它是一个特殊的浮点值,不能转换为 float 以外的任何其他类型.NaN 值是数据分析中的主要问题之一.为了得到理想的结果,对 NaN 进行处理是非常必要的. 方法 用零替换Pandas DataFram中的 NaN 值的方法: fillna(): 用于使用指定的方法填充 NA/NaN 值. replace(): da
-
使用pandas对矢量化数据进行替换处理的方法
使用pandas处理向量化的数据,进行数据的替换时不仅仅能够进行字符串的替换也能够处理数字. 做简单的示例如下: In [4]: data = Series(range(5)) In [5]: data Out[5]: 0 0 1 1 2 2 3 3 4 4 dtype: int64 In [6]: data.replace(3,333) Out[6]: 0 0 1 1 2 2 3 333 4 4 dtype: int64 In [7]: data Out[7]: 0 0 1 1 2 2 3 3
-

Pandas 模糊查询与替换的操作
主要用到的工具:Pandas .fuzzywuzzy Pandas:是基于numpy的一种工具,专门为分析大量数据而生,它包含大量的处理数据的函数和方法, 以下为pandas中文API: 缩写和包导入 在这个速查手册中,我们使用如下缩写: df:任意的Pandas DataFrame对象 s:任意的Pandas Series对象 同时我们需要做如下的引入: import pandas as pd import numpy as np 导入数据 pd.read_csv(filename):从CSV
-
pandas快速处理Excel,替换Nan,转字典的操作
pandas读取Excel import pandas as pd # 参数1:文件路径,参数2:sheet名 pf = pd.read_excel(path, sheet_name='sheet1') 删除指定列 # 通过列名删除指定列 pf.drop(['序号', '替代', '签名'], axis=1, inplace=True) 替换列名 # 旧列名 新列名对照 columns_map = { '列名1': 'newname_1', '列名2': 'newname_2', '列名3':
-
Pandas中批量替换字符的六种方法总结
目录 一.前言 二.解决过程 方法一 方法二 方法三 方法四 方法五 方法六 三.总结 一.前言 前几天在Python最强王者群有个叫[dcpeng]的粉丝问了一个关于Pandas中的问题,这里拿出来给大家分享下,一起学习. 想问一下我有一列编码为1,2,3,4的数据,如何将1批量换为“开心”,2批量换为“悲伤”这种字符替换呢? 二.解决过程 思路挺简单,限定Pandas处理,想到的方法有很多,这里拿出来给大家分享,希望对大家的学习有帮助. 下面这个是生成源数据的代码: df = pd.Data
-
Python Pandas中缺失值NaN的判断,删除及替换
目录 前言 1. 检查缺失值NaN 2. Pandas中NaN的类型 3. NaN的删除 dropna() 3.1 删除所有值均缺失的行/列 3.2 删除至少包含一个缺失值的行/列 3.3 根据不缺少值的元素数量删除行/列 3.4 删除特定行/列中缺少值的列/行 4. 缺失值NaN的替换(填充) fillna() 4.1 用通用值统一替换 4.2 为每列替换不同的值 4.3 用每列的平均值,中位数,众数等替换 4.4 替换为上一个或下一个值 总结 前言 当使用pandas读取csv文件时,如果元
-
Python pandas替换指定数据的方法实例
目录 一.构造dataframe 二.替换指定数据(fillna.isin.replace) 1.用"sz"列的同行数据将"bj"列的空值替换掉 2.在1的基础上,将"sz"列为2或者6的数据替换成-4 三.替换函数replace()详解 1.全局替换元素 2.通过指定条件替换元素 3.通过模糊条件替换指定元素 总结 一.构造dataframe import pandas as pd import numpy as np df=pd.DataFr
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值
-
pandas值替换方法
如下所示: import pandas as pd from pandas import * import numpy as np data = Series([1,-999,2,-999,-1000,3]) print(data.replace(-999,np.nan)) print(data.replace([-999,-1000],np.nan)) print(data.replace([-999,-1000],[np.nan,0])) print(data.replace({-999:n
-
python pandas 如何替换某列的一个值
摘要:本文主要是讲解怎么样替换某一列的一个值. 应用场景: 假如我们有以下的数据集: 我们想把里面不是pre的字符串全部换成Nonpre,我们要怎么做呢? 做法很简单. df['col2']=df['col1'] df.loc[df['col1'] !=' pre','col2']=Nonpre 以上这篇python pandas 如何替换某列的一个值就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.