Python创建SQL数据库流程逐步讲解
目录
- 前言
- 先决条件
- 创建脚本
- 建立连接
- 创建表格
- 生成一些随机数据
- 结论
前言
根据《2021年Stackoverflow开发者调查》,
SQL是最常用的五种编程语言之一。
所以,我们应该多投入时间来学习SQL。
由Storyset绘制的人物插图
但是有一个问题:
如何在没有数据库的情况下练习数据库查询呢?
在今天的文章中,让我们一起来解决这个基本问题,学习如何从零开始创建自己的MySQL数据库。在Python和一些外部库的帮助下,我们将创建一个简单的脚本,可以自动创建并使用随机生成的数据,填充我们的表格。
但是,在讨论实现细节之前,我们首先需要讨论一些先决条件。
注意:当然还有其他方法可以获取用于实践的SQL数据库(例如直接找资源下载),但使用Python和一些外部库可以为我们提供额外且有价值的实践机会。
先决条件
我们先从最基本的开始。
首先,需要安装MySQL Workbench并连接服务,接下来就可以开始建立数据库:
CREATE DATABASE IF NOT EXISTS your_database_name;
现在,我们只需要安装必要的python库,基本的设置就完成了。我们将要使用的库如下所示,可以通过终端轻松安装。
- NumPy: pip install numpy
- Sqlalchemy: pip install sqlalchemy
- Faker: pip install faker
创建脚本
完成基本设置后,我们可以开始编写python脚本了。
先用一些样板代码创建一个类,为我们提供一个蓝图,指导我们完成其余的实现。
import numpy as np
import sqlalchemy
from faker import Faker [python学习裙:90 3971231###
from sqlalchemy import Table, Column, Integer, String, MetaData, Date,
class SQLData:
def __init__(self, server:str, db:str, uid:str, pwd:str) -> None:
self.__fake = Faker()
self.__server = server
self.__db = db
self.__uid = uid
self.__pwd = pwd
self.__tables = dict()
def connect(self) -> None:
pass
def drop_all_tables(self) -> None:
pass
def create_tables(self) -> None:
pass
def populate_tables(self) -> None:
pass
目前我们还没用特别高级的语法。
我们基本上只是创建了一个类,存储了数据库凭据供以后使用,导入了库,并定义了一些方法。
建立连接
我们要完成的第一件事是创建一个数据库连接。
幸运的是,我们可以利用python库sqlalchemy来完成大部分工作。
class SQLData:
#...
def connect(self) -> None:
self.__engine = sqlalchemy.create_engine(
f"mysql+pymysql://{self.__uid}:{self.__pwd}@{self.__server}/{self.__db}"
)
self.__conn = self.__engine.connect()
self.__meta = MetaData(bind=self.__engine)
这个方法可以创建并存储3个对象作为实例属性。
首先,我们创建一个连接,作为sqlalchemy应用程序的起点,描述如何与特定类型的数据库/ DBAPI组合进行对话。
在我们的例子中,我们指定一个MySQL数据库并传入我们的凭据。
接下来,创建一个连接,它可以让我们执行SQL语句和一个元数据对象(一个容器),将数据库的不同功能放在一起,让我们关联和访问数据库表。
创建表格
现在,我们需要创建数据库表。
class SQLData:
#...
def create_tables(self) -> None:
self.__tables['jobs'] = Table (
'jobs', self.__meta,
Column('job_id', Integer, primary_key=True, autoincrement=True, nullable=False),
Column('description', String(255))
)
self.__tables['companies'] = Table(
'companies', self.__meta,
Column('company_id', Integer, primary_key=True, autoincrement=True, nullable=False),
Column('name', String(255), nullable=False),
Column('phrase', String(255)),
Column('address', String(255)),
Column('country', String(255)),
Column('est_date', Date)
)
self.__tables['persons'] = Table(
'persons', self.__meta,
Column('person_id', Integer, primary_key=True, autoincrement=True, nullable=False),
Column('job_id', Integer, ForeignKey('jobs.job_id'), nullable=False),
Column('company_id', Integer, ForeignKey('companies.company_id'), nullable=False),
Column('last_name', String(255), nullable=False),
Column('first_name', String(255)),
Column('date_of_birth', Date),
Column('address', String(255)),
Column('country', String(255)),
Column('zipcode', String(10)),
Column('salary', Integer)
)
self.__meta.create_all()
我们创建了3个表,并将它们存储在一个字典中,以供以后参考。
在sqlalchemy中创建表也非常简单。我们只需实例化一个新的表,提供表名、元数据对象,并指定不同的列。
在本例中,我们创建了一个job表、一个company表和一个person表。person表还通过了foreign kkey链接了其他表,这使数据库在实践SQL连接方面更加有趣。
定义了所有表格之后,我们只需调用MetaData对象的create_all()方法就好了。
生成一些随机数据
虽然我们创建了数据库表,但仍然没有任何数据可用。因此,我们需要生成一些随机数据并将其插入到表中。
class SQLData:
#...
def populate_tables(self) -> None:
jobs_ins = list()
companies_ins = list()
persons_ins = list()
for _ in range(100):
record = dict()
record['description'] = self.__fake.job()
jobs_ins.append(record)
for _ in range(100):
record = dict()
record['name'] = self.__fake.company()
record['phrase'] = self.__fake.catch_phrase()
record['address'] = self.__fake.street_address()
record['country'] = self.__fake.country()
record['est_date'] = self.__fake.date_of_birth()
companies_ins.append(record)
for _ in range(500):
record = dict()
record['job_id'] = np.random.randint(1, 100)
record['company_id'] = np.random.randint(1, 100)
record['last_name'] = self.__fake.last_name()
record['first_name'] = self.__fake.first_name()
record['date_of_birth'] = self.__fake.date_of_birth()
record['address'] = self.__fake.street_address()
record['country'] = self.__fake.country()
record['zipcode'] = self.__fake.zipcode()
record['salary'] = np.random.randint(60000, 150000)
persons_ins.append(record)
self.__conn.execute(self.__tables['jobs'].insert(), jobs_ins)
self.__conn.execute(self.__tables['companies'].insert(), companies_ins)
self.__conn.execute(self.__tables['persons'].insert(), persons_ins)
现在,我们可以利用Faker库来生成随机数据。
我们只需在for循环中使用随机生成的数据,创建一个由字典表示的新记录。然后将单个记录追加到可用于(多个)insert语句的列表中。
接下来,从连接对象中调用execute()方法,并将字典列表作为参数传递。
就是这样!我们成功实现了类—只需要把类实例化,并调用相关函数来创建数据库。
if __name__ == '__main__':
sql = SQLData('localhost','yourdatabase','root','yourpassword')
sql.connect()
sql.create_tables()
sql.populate_tables()
试着做一个查询
剩下的唯一一件事是——需要验证我们的数据库是否已经启动和运行,是否确实包含一些数据。
从基本的查询开始:
SELECT * FROM jobs LIMIT 10;

基本查询结果[图片by作者]
看起来我们的脚本成功了,我们有一个包含实际数据的数据库。
现在,尝试一个更复杂的SQL语句:
SELECT p.first_name, p.last_name, p.salary, j.description FROM persons AS p JOIN jobs AS j ON p.job_id = j.job_id WHERE p.salary > 130000 ORDER BY p.salary DESC;
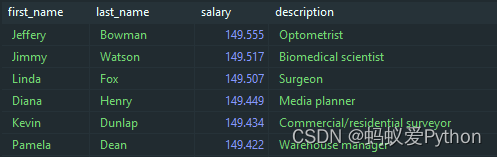
这个结果看起来很靠谱 – 可以说我们的数据库在正常运行。
结论
在本文中,我们学习了如何利用Python和一些外部库来用随机生成的数据创建我们自己的实践数据库。
虽然可以很容易地下载现有的数据库来开始练习SQL,但使用Python从头创建自己的数据库提供了额外的学习机会。由于SQL和Python经常紧密联系在一起,所以这些学习机会可能会特别有用。
到此这篇关于Python创建SQL数据库流程逐步讲解的文章就介绍到这了,更多相关Python创建SQL内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python操作SQLite数据库的方法详解【导入,创建,游标,增删改查等】
本文实例讲述了Python操作SQLite数据库的方法.分享给大家供大家参考,具体如下: SQLite简介 SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中.它是D.RichardHipp建立的公有领域项目.它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了.它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl.C
-
Python 中创建 PostgreSQL 数据库连接池
目录 习惯于使用数据库之前都必须创建一个连接池,即使是单线程的应用,只要有多个方法中需用到数据库连接,建立一两个连接的也会考虑先池化他们.连接池的好处多多, 1) 如果反复创建连接相当耗时, 2) 对于单个连接一路用到底的应用,有连接池时避免了数据库连接对象传来传去, 3) 忘记关连接了,连接池幸许还能帮忙在一定时长后关掉,当然密集取连接的应用势将耗尽连接, 4) 一个应用打开连接的数量是可控的 接触到 Python 后,在使用 PostgreSQL 也自然而然的考虑创建连接池,使用时从池中取,
-

Python创建SQL数据库流程逐步讲解
目录 前言 先决条件 创建脚本 建立连接 创建表格 生成一些随机数据 结论 前言 根据<2021年Stackoverflow开发者调查>, SQL是最常用的五种编程语言之一. 所以,我们应该多投入时间来学习SQL. 由Storyset绘制的人物插图 但是有一个问题: 如何在没有数据库的情况下练习数据库查询呢? 在今天的文章中,让我们一起来解决这个基本问题,学习如何从零开始创建自己的MySQL数据库.在Python和一些外部库的帮助下,我们将创建一个简单的脚本,可以自动创建并使用随机生成的数据,
-
SpringCloud Config连接git与数据库流程分析讲解
目录 1.什么是Spring Cloud Config 2.EnvironmentRepository抽象 3.实战-使用git作为配置源 1.搭建config server 2.搭建config client 3.config server HTTP接口 4.实战-使用数据库作为配置源 5.实战-复合配置源 1.什么是Spring Cloud Config Spring Cloud Config为微服务架构提供了配置管理的功能,通过Spring Cloud Config服务端提供配置中心,在各
-
Python创建简单的神经网络实例讲解
在过去的几十年里,机器学习对世界产生了巨大的影响,而且它的普及程度似乎在不断增长.最近,越来越多的人已经熟悉了机器学习的子领域,如神经网络,这是由人类大脑启发的网络.在本文中,将介绍用于一个简单神经网络的 Python 代码,该神经网络对于一个 1x3 向量,分类第一个元素是否为 10. 步骤1: 导入 NumPy. Scikit-learn 和 Matplotlib import numpy as np from sklearn.preprocessing import MinMaxScale
-
python创建堆的方法实例讲解
1.说明 创建堆有两种基本方法:heappush() 和 heapify(). 当使用heappush()时,当新元素添加时,堆得顺序被保持了. 如果数据已经在内存中,则使用 heapify() 来更有效地重新排列列表中的元素. 2.实例 import heapq from heapq_showtree import show_tree from heapq_heapdata import data heap = [] print('random :', data) print() for n
-
带你彻底搞懂python操作mysql数据库(cursor游标讲解)
1.什么是游标? 一张图讲述游标的功能: 图示说明: 2.使用游标的好处? 如果不使用游标功能,直接使用select查询,会一次性将结果集打印到屏幕上,你无法针对结果集做第二次编程.使用游标功能后,我们可以将得到的结果先保存起来,然后可以随意进行自己的编程,得到我们最终想要的结果集. 3.利用python连接数据库,经常会使用游标功能 1)以python连接mysql数据库为例 2)使用游标的操作步骤 首先,使用pymysql连接上mysql数据库,得到一个数据库对象. 然后,我们必须要开启数据
-
Python操作MongoDb数据库流程详解
1.简介 MongoDB是一个基于分布式文件存储的文档数据库,可以说是非关系型(NoSQL,Not Only SQL)数据库中比较像关系型数据库的一个,具有免费.操作简单.面向文档.自动分片.可扩展性强.查询功能强大等特点,对大数据处理支持较好,旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB将数据存储为一个文档,数据结构由键值(key=>value)对组成.MongoDB文档类似于JSON对象.字段值可以包含其他文档,数组及文档数组. 2.应用 MongoDB数据库可以到网
-
c# asp .net 动态创建sql数据库表的方法
复制代码 代码如下: //必须的命名空间using System;using System.Data;using System.Data.SqlClient;//中间常规内容略string tabName = "table1";//声明要创建的表名,你也可以改为从textbox中获取:string sqlStr = "create table ";sqlStr += tabName + "( ";sqlStr += "col0 nume
-
Android学习笔记-保存数据到SQL数据库中(Saving Data in SQL Databases)
知识点: 1.使用SQL Helper创建数据库 2.数据的增删查改(PRDU:Put.Read.Delete.Update) 背景知识: 上篇文章学习了android保存文件,今天学习的是保存数据到SQL数据库中.相信大家对数据库都不陌生.对于大量重复的,有特定结构的数据的保存,用 SQL数据库 来保存是最理想不过了. 下面将用一个关于联系人的数据库Demo来具体学习. 具体知识: 1.定义Contract类 在创建SQL数据库之前,要创建Contract类.那什么是Contract类呢? 复
-
Python轮播图与导航栏功能的实现流程全讲解
目录 轮播图功能 安装依赖模块 上传文件相关配置 注册home子应用 创建轮播图的model模型 创建Banner的序列化器 创建Banner的视图类 配置Banner的路由 配置Xadmin 配置文件注册Xadmin应用 在总路由中添加xadmin的路由信息 给Xadmin配置基本的站点信息 注册轮播图模型到xadmin中 修改后端Xadmin中子应用名称 给轮播图添加测试数据 web端代码获取数据 导航栏的实现 前端导航栏子组件Header的代码 后端导航栏的实现 设计导航栏的model模型