Python爬虫DOTA排行榜爬取实例(分享)
1、分析网站
打开开发者工具,我们观察到排行榜的数据并没有在doc里

doc文档
在Javascript里我么可以看到下面代码:

ajax的post方法异步请求数据
在 XHR一栏里,我们找到所请求的数据
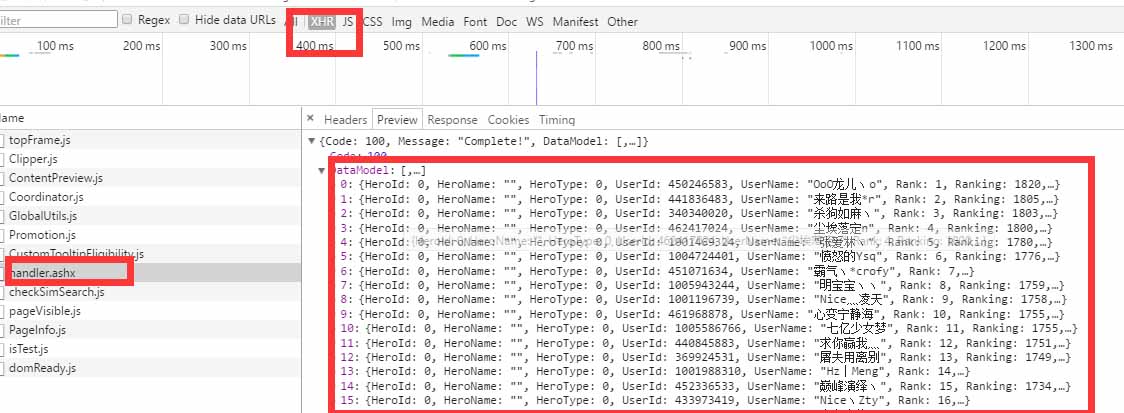
json存储的数据
请求字段为:

post请求字段
2、伪装浏览器,并将json数据存入excel里面

获取信息

将数据保存到excel中
3、结果展示
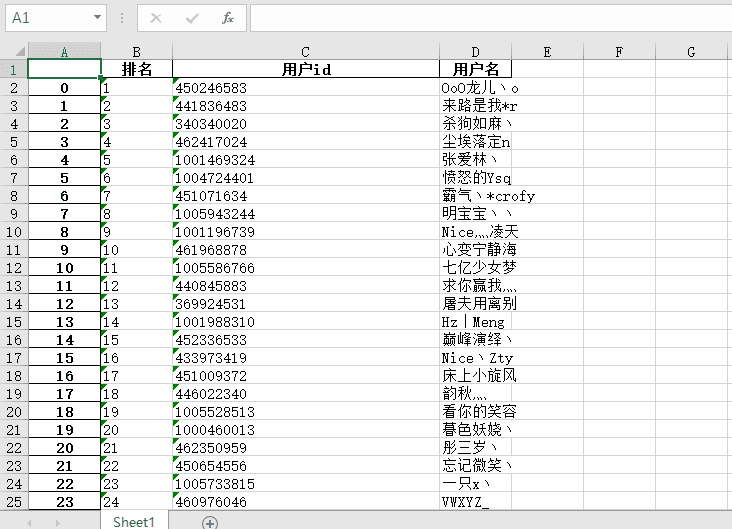
以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python爬虫爬取美剧网站的实现代码
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间.之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了.但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷下载的美剧下载网站[天天美剧],各种资源随便下载,最近迷上的BBC的高清纪录片,大自然美得不要不要的. 虽说找到了资源网站可以下载了,但是每次都要打开浏览器,输入网址,找到该美剧,然后点击链接才能下载.时间长了就觉得过程好繁琐,而且有时候网
-
Python实现爬取知乎神回复简单爬虫代码分享
看知乎的时候发现了一个 "如何正确地吐槽" 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了. 工具 1.Python 2.7 2.BeautifulSoup 分析网页 我们先来看看知乎上该网页的情况 网址:,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了. 再来看一下我们要爬取的内容: 我们要爬取两个内容:问题和回答,回答仅限于显示
-
python实现简单爬虫功能的示例
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度.好吧-!其实你很厉害的,右键查看页面源代码. 我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地.下面就看看如何使用python来实现这样一个功能. 一,获取整个页面数据 首先我们
-
python妹子图简单爬虫实例
本文实例讲述了python妹子图简单爬虫实现方法.分享给大家供大家参考.具体如下: #!/usr/bin/env python #coding: utf-8 import urllib import urllib2 import os import re import sys #显示下载进度 def schedule(a,b,c): ''''' a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 ''' per = 100.0 * a * b / c if per > 100 : per
-
Python爬虫DOTA排行榜爬取实例(分享)
1.分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在 XHR一栏里,我们找到所请求的数据 json存储的数据 请求字段为: post请求字段 2.伪装浏览器,并将json数据存入excel里面 获取信息 将数据保存到excel中 3.结果展示 以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python爬虫UA伪装爬取的实例讲解
在使用python爬取网站信息时,查看爬取完后的数据发现,数据并没有被爬取下来,这是因为网站中有UA这种请求载体的身份标识,如果不是基于某一款浏览器爬取则是不正常的请求,所以会爬取失败.本文介绍Python爬虫采用UA伪装爬取实例. 一.python爬取失败原因如下: UA检测是门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求.如果检测到请求的载体身份标识不是基于某一款浏览器的.则表示该请求为不正常的请求,则服务器端就很有可能会
-
Python爬虫小例子——爬取51job发布的工作职位
概述 不知从何时起,Python和爬虫就如初恋一般,情不知所起,一往而深,相信很多朋友学习Python,都是从爬虫开始,其实究其原因,不外两方面:其一Python对爬虫的支持度比较好,类库众多.其二Pyhton的语法简单,入门容易.所以两者形影相随,不离不弃,本文主要以一个简单的小例子,简述Python在爬虫方面的简单应用,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 本例主要爬取51job发布的工作职位,用到的知识点如下: 开发环境及工具:主要用到Python3.7 ,IDE为PyC
-
python爬虫使用正则爬取网站的实现
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关. 本文章是自己学习的一些记录.欢迎各位大佬点评! 首先 今天是第一天写博客,感受到了博客的魅力,博客不仅能够记录每天的代码学习情况,并且可以当作是自己的学习笔记,以便在后面知识点不清楚的时候前来复习.这是第一次使用爬虫爬取网页,这里展示的是爬取豆瓣电影top250的整个过程,欢迎大家指点. 这里我只爬取了电影链接和电影名称,如果想要更加完整的爬取代码,请联系我.qq 1540741
-
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip 环境:python3.8+pycharm 库:requests,lxml 浏览器:谷歌 IP地址:http://www.xiladaili.com/gaoni/ 分析网页源码: 选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath 我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1] 虽然可以查出来ip,但不利于程序自动爬取所有
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
python爬虫之Appium爬取手机App数据及模拟用户手势
目录 Appium 模拟操作 屏幕滑动 屏幕点击 屏幕拖动 屏幕拖拽 文本输入 动作链 实战:爬取微博首页信息 Appium 在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式.但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象. 那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容. 也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载
-
Python爬虫实战之爬取某宝男装信息
目录 知识点介绍 实现步骤 1. 分析目标网站 2. 获取单个商品界面 3. 获取多个商品界面 4. 获取商品信息 5. 保存到MySQL数据库 完整代码 知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审