深入解析C++ Data Member内存布局
如果一个类只定义了类名,没定义任何方法和字段,如class A{};那么class A的每个实例占用1个字节的内存,编译器会会在这个其实例中安插一个char,以保证每个A实例在内存中有唯一的地址,如A a,b;&a!=&b。如果一个直接或是间接的继承(不是虚继承)了多个类,如果这个类及其父类像A一样没有方法没有字段,那么这个类的每个实例的大小都是1字节,如果有虚继承,那就不是1字节了,每虚继承一个类,这个类的实例就会多一个指向被虚继承父类的指针。还有一点值得说明的就是像A这样的类,编译器不一定会产生传说中的那6个方法,这些方法只会在需要的时候产生,如class A没有被任何地方使用那这些方法编译器就没有必要产生,如果这个类实例化了,那么会产生default constructor,而destructor则不一定产生。
如果一个类中有static data member,nonstatic data member,还有const data member,enum,那么它的内存布局会是什么样的呢,看下面简单的类Point:
代码如下:
class Point
{
public:
Point():maxCount(10){}
private:
int X;
static int count;
int Y;
const int maxCount ;
enum{
minCount=2
};
};
Sizeof(Point)=12,为什么占12字节呢,我相信很多人都知道是哪几个成员变量占用的,就是X,Y,maxCount,maxCount作为常量字段,但在Point的每个实例中可能有不同的值,当然属于Point实例的一部分,如果把maxCount定义成static,那它就不不是Point实例的一部分了,如果定义成static const int maxCount=1;则maxCount分配在.data段中,如果没有初始化则分配在.bss段中,反正跟Point的实例无关,count分配在.bss段中,minCount分配在.rdata段中,总之count,maxCount,minCount在编译连接完成之后,内存(虚拟地址)就分配好了,在程序加载的时候,会把他们的虚拟地址对应上实际的物理地址。
Data member的内存布局:nonstatic data member在class object中的顺序和其申明的顺序一样,static data member和const member不在class object中因为他们只有一份,被class object共享,所以static data member和const data member,枚举并不会响应class object的大小。关于段的信息,我觉得是每个C/C++程序员必须知道的。而Point每次实例化的时候则只需要分配X,Y,maxCount需要的内存。
每个类的data member在内存中应该是连续的,如果出现数据对齐的情况,可能中间会有空白地带。请看下面几个类:
代码如下:
class AA
{
protected:
int X;
char a;
};
class BB:public AA
{
protected:
char b;
};
class CC:public BB
{
protected:
char c;
};
Sizeof(AA)=8//对齐3字节
Sizeof(BB)=12//两个3字节对齐
Sizeof(CC)=16//编译器“无耻”的用了3个3字节对齐
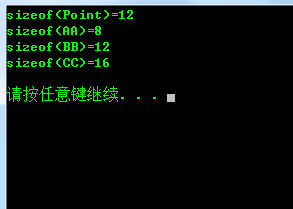
编译器为什么要无耻的在class CC中加3个3字节对齐呢,这样每个CC的实例就大了9字节。如果编译器不加这9字节的空白,那么CC的每个实例就是8字节,前面的X占4字节,后面的a,b,c占3字节,加1字节的空白对齐,刚好8字节,没有谁很傻很天真的以为最好是占7字节吧。
如果CC占用8字节内存,同样的AA,BB都是8字节的内存,这样的话,如果把一个指向AA实例的指针赋给一个指向CC实例的指针,那么就会把AA中的8字节直接盖到CC的8字节上,结果CC实例中的b,c都被赋上了不是我们想要的值,这很可能会导致你的程序出问题。
父类的data member会在子类的实例中有完整的一份,这样在有继承关系的类之间进行类型转换,就只用简单的修改指针的指向。
Data Member的存取。对一个data member的存取,编译器把对象实例的起始地址加上data member的偏移量。如CC c;
c.X=1;相当于&c+(&CC::X-1),减一其实是为了区分是指向object的指针还是指向data member的指针,指向data member的要减一。每一个data member的偏移量在编译的时候是知道的,根据成员变量的类型和内存对齐,存在virtual继承或是虚方法的情况编译器会自动加上一些辅助的指针,如指向虚方法的指针,指向虚继承父类的指针等。
在data member的存取效率上,struct member 、class member、单一继承或是多重继承的情况下效率都是一样的,因为他们的存储其实都是&obj+(&class.datamember-1)。在虚继承的情况下,可能会影响存储性能,如通过一个指针来存取一个指向虚继承而来的data member,那么性能会有影响,因为在虚继承的时候,在编译的时候还不能确定这个data member是来自子类还是父类,只有在运行的时候才能推断出来,其实就是多了一步指针的操作,在虚继承中,如果是通过对象实例来操作虚继承而来的data member,则不会有任何性能问题,因为不存在什么多态性,所有东西在编译的时候内存地址都确定了。
虚继承还是虚方法为了实现多态一样,多了一步,如果不需要多态,而是通过对象实例调用相关的方法就不会有性能问题。
相关推荐
-
基于C++执行内存memcpy效率测试的分析
在进行memcpy操作时,虽然是内存操作,但是仍然是耗一点点CPU的,今天测试了一下单线程中执行memcpy的效率,这个结果对于配置TCP epoll中的work thread 数量有指导意义.如下基于8K的内存快执行memcpy, 1个线程大约1S能够拷贝500M,如果服务器带宽或网卡到上限是1G,那么网络io的work thread 开2个即可,考虑到消息的解析损耗,3个线程足以抗住硬件的最高负载. 在我到测试机器上到测试结果是: Intel(R) Xeon(R) CPU
-
C/C++中的mem函数和strcopy函数的区别和应用
strcpy和memcpy都是标准C库函数,它们有下面的特点. strcpy提供了字符串的复制.即strcpy只用于字符串复制,并且它不仅复制字符串内容之外,还会复制字符串的结束符. memcpy提供了一般内存的复制.即memcpy对于需要复制的内容没有限制,因此用途更广. mem系列函数是面试的时候常考的知识点,我们需要熟练掌握这三个函数的原理和代码实现,要能准确无误的写出代码. memcpy.memset和memset三个函数在使用过程中,均需包含以下头文件: //在C中 #include<
-
浅析C++中memset,memcpy,strcpy的区别
复制代码 代码如下: #include <stdio.h>#include <stdlib.h>#include <string.h>#include <assert.h> //memcpy:按字节复制原型:extern void* memcpy(void *dest,void *src,unsigned int count)//功能:由src所指内存区域复制count个字节到dest所指的内存区域://同strcpyvoid *memcpy_su(void
-

C++中memcpy和memmove的区别总结
变态的命名 我们在写程序时,一般讲究见到变量的命名,就能让别人基本知道该变量的含义.memcpy内存拷贝,没有问题;memmove,内存移动?错,如果这样理解的话,那么这篇文章你就必须要好好看看了,memmove还是内存拷贝.那么既然memcpy和memmove二者都是内存拷贝,那二者究竟有什么区别呢? 先说memcpy 你有没有好好的参加过一场C++笔试.让你写出memcpy的实现,这是多么常见的笔试题啊.现在,拿起你的演算纸和笔;是的,是笔和纸,不是让你在你的IDE上写.写不出来?看下面吧:
-
C++中memset函数用法详解
本文实例讲述了C++中memset函数用法.分享给大家供大家参考,具体如下: 功 能: 将s所指向的某一块内存中的每个字节的内容全部设置为ch指定的ASCII值,块的大小由第三个参数指定,这个函数通常为新申请的内存做初始化工作 用 法: void memset(void *s, char ch, unsigned n); 程序示例: #include <string.h> #include <stdio.h> #include <memory.h> int main(v
-
深入解析C++ Data Member内存布局
如果一个类只定义了类名,没定义任何方法和字段,如class A{};那么class A的每个实例占用1个字节的内存,编译器会会在这个其实例中安插一个char,以保证每个A实例在内存中有唯一的地址,如A a,b;&a!=&b.如果一个直接或是间接的继承(不是虚继承)了多个类,如果这个类及其父类像A一样没有方法没有字段,那么这个类的每个实例的大小都是1字节,如果有虚继承,那就不是1字节了,每虚继承一个类,这个类的实例就会多一个指向被虚继承父类的指针.还有一点值得说明的就是像A这样的类,编译器不
-
深入理解JVM之Java对象的创建、内存布局、访问定位详解
本文实例讲述了深入理解JVM之Java对象的创建.内存布局.访问定位.分享给大家供大家参考,具体如下: 对象的创建 一个简单的创建对象语句Clazz instance = new Clazz();包含的主要过程包括了类加载检查.对象分配内存.并发处理.内存空间初始化.对象设置.执行ini方法等. 主要流程如下: 1. 类加载检查 JVM遇到一条new指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载.解析和初始化过.如果没有,那必须先执
-
c++对象内存布局示例详解
目录 前言 继承对象的内存布局 具有多重继承和虚拟功能的对象的内存布局 总结 前言 了解你所使用的编程语言究竟是如何实现的,对于C++程序员可能特别有意义.首先,它可以去除我们对于所使用语言的神秘感,使我们不至于对于编译器干的活感到完全不可思议:尤其重要的是,它使我们在Debug和使用语言高级特性的时候,有更多的把握.当需要提高代码效率的时候,这些知识也能够很好地帮助我们. 简单非多态的内存布局 class X { int x; float xx; public: X() {} ~X() {}
-
Go语言中的内存布局详解
一.go语言内存布局 想象一下,你有一个如下的结构体. 复制代码 代码如下: type MyData struct { aByte byte aShort int16 anInt32 int32 aSlice []byte } 那么这个结构体究竟是什么呢? 从根本上说,它描述了如何在内存中布局数据. 这是什么意思?编译器又是如何展现出来呢? 我们来看一下. 首先让我们使用反射来检查结构中的字段. 二.反射之上 下面是一些使用
-
详解Java对象的内存布局
前言 今天来讲些抽象的东西 -- 对象头,因为我在学习的过程中发现很多地方都关联到了对象头的知识点,例如JDK中的 synchronized锁优化 和 JVM 中对象年龄升级等等.要深入理解这些知识的原理,了解对象头的概念很有必要,而且可以为后面分享 synchronized 原理和 JVM 知识的时候做准备. 对象内存构成 Java 中通过 new 关键字创建一个类的实例对象,对象存于内存的堆中并给其分配一个内存地址,那么是否想过如下这些问题: 这个实例对象是以怎样的形态存在内存中的? 一个O
-
浅析C++内存布局
目录 虚拟内存 类的实例化对象所占的内存空间 空类的实例化对象占1一个字节 类的成员函数不占用类对象的内存空间 类的成员变量占用类对象的内存空间 字节对齐原则 虚拟内存 每个进程的用户空间是私有的,内核空间是共享的:通过进程间通信比线程间通信难也是因为进程间的用户空间是相互隔离的,无法相互访问,需要通过进程间通信方式通信,通过内核地址空间: #include <iostream> int gdata1 = 1; int gdata2 = 0; int gdata3; static int gd
-
Java对象的内存布局全流程
目录 对象内存布局 对象占用内存空间 证明对象内存布局 开始先抛出一个问题:一个对象o,Object o = new Object();创建完成后会占用多少字节的内存? 要能回答这个问题,就需要了解java对象的内存布局. 对象内存布局 一个Java对象在内存中包括对象头.实例数据和对齐填充三个部分.如下图所示: 对象头 Mark Word:包含一系列的标记位比如hashcode.GC分代年龄.偏向锁位,锁标志位等.这个Mark Word在对象被加了不同量级的锁时所包含的内容和布局都有所不同,这
-
浅析Python的对象拷贝和内存布局
目录 前言 Python 对象的内存布局 牛刀小试 查看对象的内存地址 copy模块 可变和不可变对象与对象拷贝 代码片段分析 撕开 Python 对象的神秘面纱 总结 前言 在本篇文章当中主要给大家介绍 python 当中的拷贝问题,话不多说我们直接看代码,你知道下面一些程序片段的输出结果吗? a = [1, 2, 3, 4] b = a print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }
-
详谈C++中虚基类在派生类中的内存布局
今天重温C++的知识,当看到虚基类这点的时候,那时候也没有太过追究,就是知道虚基类是消除了类继承之间的二义性问题而已,可是很是好奇,它是怎么消除的,内存布局是怎么分配的呢?于是就深入研究了一下,具体的原理如下所示: 在C++中,obj是一个类的对象,p是指向obj的指针,该类里面有个数据成员mem,请问obj.mem和p->mem在实现和效率上有什么不同. 答案是:只有一种情况下才有重大差异,该情况必须满足以下3个条件: (1).obj 是一个虚拟继承的派生类的对象 (2).mem是从虚拟基类派
-
浅析内存对齐与ANSI C中struct型数据的内存布局
这些问题或许对不少朋友来说还有点模糊,那么本文就试着探究它们背后的秘密. 首先,至少有一点可以肯定,那就是ANSI C保证结构体中各字段在内存中出现的位置是随它们的声明顺序依次递增的,并且第一个字段的首地址等于整个结构体实例的首地址.比如有这样一个结构体: 复制代码 代码如下: struct vector{int x,y,z;} s; int *p,*q,*r; struct vector *ps; p = &s.x; q = &s.y; r = &s.z; ps =