Python爬取智联招聘数据分析师岗位相关信息的方法
进入智联招聘官网,在搜索界面输入‘数据分析师',界面跳转,按F12查看网页源码,点击network

选中XHR,然后刷新网页

可以看到一些Ajax请求, 找到画红线的XHR文件,点击可以看到网页的一些信息
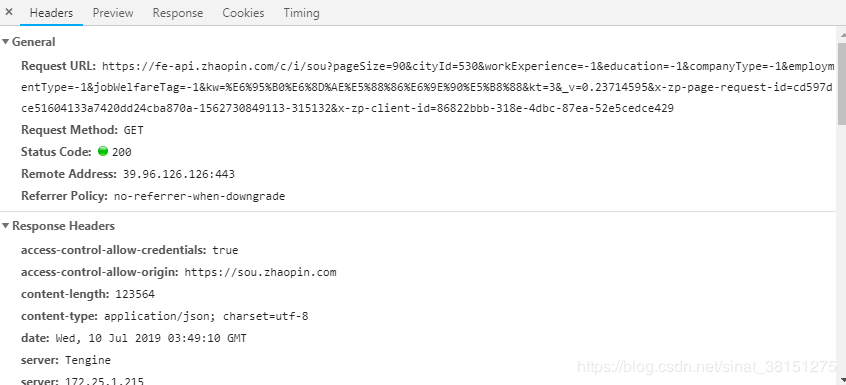
在Header中有Request URL,我们需要通过找寻Request URL的特点来构造这个请求网址,
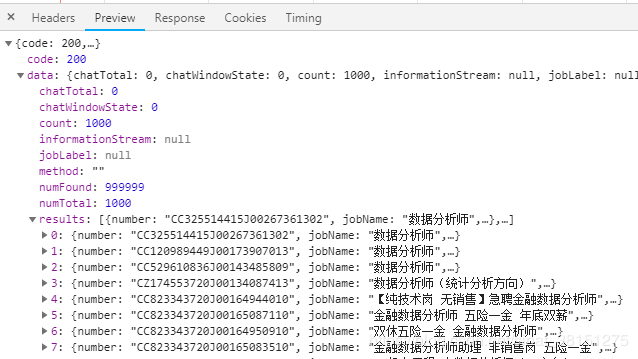
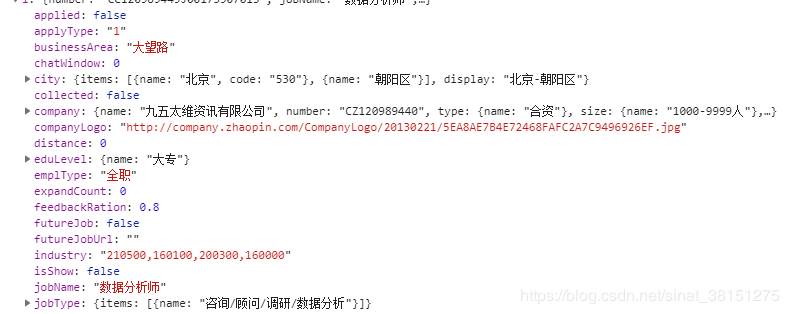
点击Preview,可以看到我们所需要的信息就存在result中,这信息基本是json格式,有些是列表;
下面我们通过Python爬虫来爬取上面的信息;
代码如下:
import requests
from urllib.parse import urlencode
import json
#from requests import codes
#import os
#from hashlib import md5
#from multiprocessing.pool import Pool
#import re
def get_page(offset):
params = {
'start': offset,
'pageSize': '90',
'cityId': '530',
'salary': '0,0',
'workExperience': '-1',
'education': '-1',
'companyType': '-1',
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': '数据分析师',
'kt': '3',
'_v': '0.77091902',
'x-zp-page-request-id': '8ff0aa73bf834b408f46324e44d89b84-1562722989022-210101',
'x-zp-client-id': '2dc4c9a4-e80d-4488-84a3-03426dd69a1e'
}
base_url = 'https://fe-api.zhaopin.com/c/i/sou?'
url = base_url + urlencode(params)
try:
resp = requests.get(url)
print(url)
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None
def get_information(json_page):
if json_page.get('data'):
results = json_page.get('data').get('results')
for result in results:
yield {
'city': result.get('city').get('display'),
'company': result.get('company').get('name'),
#'welfare':result.get('welfare'),
'workingExp':result.get('workingExp').get('name'),
'salary':result.get('salary'),
'eduLevel':result.get('eduLevel').get('name')
}
print('succ')
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False)+'\n')
def main(offset):
json_page=get_page(offset)
for content in get_information(json_page):
write_to_file(content)
if __name__=='__main__':
for i in range(10):
main(offset=90*i)
爬取结果如下:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python爬取淘宝商品详情页数据
在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据如下: 可以看到,页面上很多数据都不显示了,比如商品价格变成了划线价格,而且累计评论也变成了0,说明这些数据都是动态加载的,以下演示真实价格的找法(评论内容找法类似),首先检查页面元素,然后点击Network选项卡,刷新页面,可
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
Python爬取数据并写入MySQL数据库的实例
首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据. 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几个并列的 td 标签,下面是爬取的代码: #!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import MySQLdb print('连接到m
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的
-
python requests爬取高德地图数据的实例
如下所示: 1.pip install requests 2.pip install lxml 3.pip install xlsxwriter import requests #想要爬必须引 from lxml import html #这个是用于页面爬取 import xlsxwriter#操作Excel表格库 workbook = xlsxwriter.Workbook('E:/test/test.xlsx')# 新建的Excel表格文档路径 worksheet = workbook.ad
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-
Python如何爬取实时变化的WebSocket数据的方法
一.前言 作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据.股市实时数据或币圈实时变化的数据.如下图: Web 领域中,用于实现数据'实时'更新的手段有轮询和 WebSocket 这两种.轮询指的是客户端按照一定时间间隔(如 1 秒)访问服务端接口,从而达到 '实时' 的效果,虽然看起来数据像是实时更新的,但实际上它有一定的时间间隔,并不是真正的实时更新.轮询通常采用 拉 模式,由客户端主动从服务端拉取数据. WebSocket 采用的是 推 模式,由服务端主动将数
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re