PyCharm搭建Spark开发环境的实现步骤
1.安装好JDK
下载并安装好jdk-12.0.1_windows-x64_bin.exe,配置环境变量:
- 新建系统变量JAVA_HOME,值为Java安装路径
- 新建系统变量CLASSPATH,值为 .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意最前面的圆点)
- 配置系统变量PATH,添加 %JAVA_HOME%bin;%JAVA_HOME%jrebin
在CMD中输入:java或者java -version,不显示不是内部命令等,说明安装成功。
2.安装Hadoop,并配置环境变量
下载hadoop:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
- 解压hadoop-2.7.7.tar.gz特定路径,如:D:\adasoftware\hadoop
- 添加系统变量HADOOP_HOME:D:\adasoftware\hadoop
- 在系统变量PATH中添加:D:\adasoftware\hadoop\bin
- 安装组件winutils:将winutils中对应的hadoop版本中的bin替换自己hadoop安装目录下的bin
3.Spark环境变量配置
spark是基于hadoop之上的,运行过程中会调用相关hadoop库,如果没配置相关hadoop运行环境,会提示相关出错信息,虽然也不影响运行。
- 下载对应hadoop版本的spark:http://spark.apache.org/downloads.html
- 解压文件到:D:\adasoftware\spark-2.4.3-bin-hadoop2.7
- 添加PATH值:D:\adasoftware\spark-2.4.3-bin-hadoop2.7\bin;
- 新建系统变量SPARK_HOME:D:\adasoftware\spark-2.4.3-bin-hadoop2.7;
4.下载安装anaconda
anaconda集成了python解释器和大多数python库,安装anaconda 后不用再安装python和pandas numpy等这些组件了。下载地址。最后将python加到path环境变量中。
5.在CMD中运行pyspark,出现类似下图说明安装配置正常:

出现这种warning是因为JDK版本为12,太高了,但是不影响运行。没有影响。
6.在pycharm中配置spark
打开PyCharm,创建一个Project。然后选择“Run” ->“Edit Configurations”–>点击+创建新的python Configurations
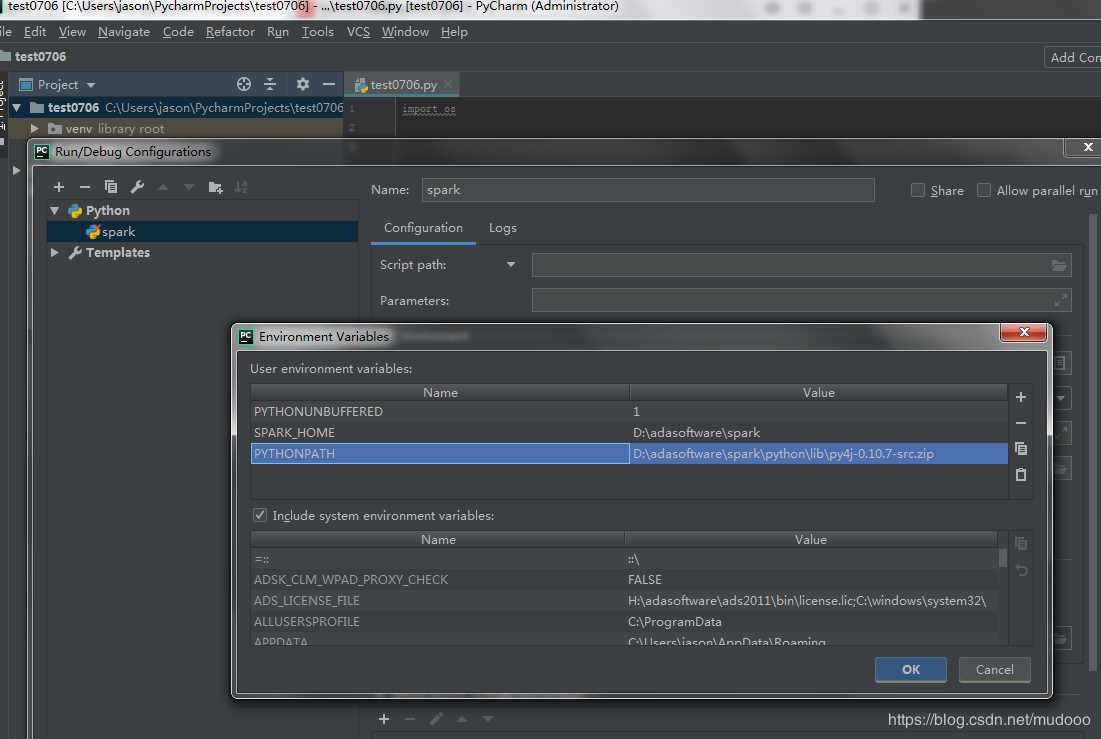
选择 “Environment variables” 增加SPARK_HOME目录与PYTHONPATH目录。
- SPARK_HOME:Spark安装目录
- PYTHONPATH:Spark安装目录下的Python目录

选择 File->setting->你的project->project structure
右上角Add content root添加:py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)
保存即可
7.测试是否配置成功,程序代码如下,创建一个python程序放进去就可以:
import os
import sys
# Path for spark source folder
os.environ['SPARK_HOME'] = "D:\adasoftware\spark"
# Append pyspark to Python Path
sys.path.append("D:\adasoftware\spark\python")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print("Successfully imported Spark Modules")
except ImportError as e:
print("Can not import Spark Modules", e)
sys.exit(1)
若程序正常输出: "Successfully imported Spark Modules"就说明环境已经可以正常执行。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
PyCharm搭建Spark开发环境实现第一个pyspark程序
一, PyCharm搭建Spark开发环境 Windows7, Java1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop2.7.6 通常情况下,Spark开发是基于Linux集群的,但这里作为初学者并且囊中羞涩,还是在windows环境下先学习吧. 参照这个配置本地的Spark环境. 之后就是配置PyCharm用来开发Spark.本人在这里浪费了不少时间,因为百度出来的无非就以下两种方式: 1.在程序中设置环境变量 import os import sys
-

PyCharm搭建Spark开发环境的实现步骤
1.安装好JDK 下载并安装好jdk-12.0.1_windows-x64_bin.exe,配置环境变量: 新建系统变量JAVA_HOME,值为Java安装路径 新建系统变量CLASSPATH,值为 .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意最前面的圆点) 配置系统变量PATH,添加 %JAVA_HOME%bin;%JAVA_HOME%jrebin 在CMD中输入:java或者java -version,不显示不是内部命令等,说明
-
Webpack 4.x搭建react开发环境的方法步骤
本文介绍了了Webpack 4.x搭建react开发环境的方法步骤,分享给大家,也给自己留个笔记 必要依赖一览(npm install) 安装好. "dependencies": { "babel-core": "^6.26.3", "babel-loader": "^7.1.5", "babel-preset-env": "^1.7.0", "react&
-
VSCode搭建STM32开发环境的方法步骤
目录 1.安装VScode 2.安装C/C++插件 3.安装Keil Assistant插件 4.用vscode打开keil工程 5.编译.下载程序 6.常用操作 官方简述 摘要: 作为一个51单片机或STM32单片机的使用者,keil一直是我们的必备的一款工具之一.但keil的一些问题也一直存在,当然也有人用其他的比如STM32CubeIDE.但是今天推荐的是VScode+Keil Assistant插件,不需要很复杂的配置各种文件和环境变量,只需要一个插件即可!可以编译代码和下载程序. 当我
-
Eclipse+ADT+Android SDK搭建安卓开发环境的实现步骤
目录 运行环境 下载地址 环境下载 安装JDK 安装Eclipse 下载独立的Android SDK工具 ADT安卓开发工具安装 eclipse离线安装ADT插件 配置ADT插件 通过Android SDK Manage添加新的软件包 AVD Manage创建安卓虚拟机 运行环境 windows 7 下载地址 环境下载 最近开接触Android(安卓)嵌入式开发,首要问题是搭建Andoid开发环境,由于本人用的是windows7的笔记本,也就只能到Windows中搭建Android 开发环境了!
-
使用IDEA搭建Hadoop开发环境的操作步骤(Window10为例)
下载安装Hadoop 下载安装包 进入官网下载下载hadoop的安装包(二进制文件)http://hadoop.apache.org/releases.html 我们这里下载2.10.1版本的,如果想下载更高版本的请先去maven仓库查看是否有对应版本 解压文件 下载好的.gz文件可以直接解压. winRAR和Bandizip都可以用来解压,但是注意必须以管理员身份打开解压软件,否则会出现解压错误 配置环境变量 配置JAVA_HOME和HADOOP_HOME 我们在环境变量处分别设置JAVA_H
-
Linux环境下搭建php开发环境的操作步骤
本文主要记载了通过编译方式进行软件/开发环境的安装过程,其他安装方式忽略! 文章背景: 因为php和Apache等采用编译安装方式进行安装,然而编译安装方式,需要c,c++编译环境, 通过apt方式安装build-essential $ sudo apt-get install build-essential 编译安装的步骤一般分为: 编译配置 $ ./configure --XXX(参数s) 编译配置的问题: a.在没有安装之前,对软件无法全面了解 b.如果不全全面了解,又不知道该怎么安装(附
-
利用Docker搭建Laravel开发环境的完整步骤
前言 在这篇文章中我们将通过Docker在个人本地电脑上构建一个快速.轻量级.不依赖本地电脑所安装的任何开发套件的可复制的Laravel和Vue项目的开发环境(开发环境的所有依赖都安装在Docker构建容器里),加入Vue只是因为有的项目里会在Laravel项目中使用Vue做前后端分离开发,开发环境中需要安装前端开发需要的工具集,当然前后端也可以分成两个项目开发,这个话题不在本篇文章的讨论范围内. 所以我们的目标是: 不在本地安装Mamp/Wamp这样的软件 不使用类似Vagrant这样的虚拟机
-
pycharm配置pyqt5-tools开发环境的方法步骤
本文介绍使用python+pyqt5开发桌面程序的一个可视化UI视图布局 一.环境包的安装 1.如果还不知道虚拟环境的可以参考,或者直接使用pipenv 2.安装pyqt5 pip3 install pyqt5 3.安装pyqt5-tools(注意目前只支持在window系统下,如果你是mac电脑请自行安装虚拟机) pip3 install pyqt5-tools 4.使用pip3 list查看安装是否成功 二.在pycharm中配置pyqt5-tools工具 在pycharm编辑器中主要配置有
-
在Mac OS下搭建LNMP开发环境的步骤详解
一.概述 大家应该都知道LNMP代表的就是:Linux系统下Nginx+MySQL+PHP这种网站服务器架构.Linux是一类Unix计算机操作系统的统称,是目前最流行的免费操作系统.代表版本有:debian.centos.ubuntu.fedora.gentoo等.Nginx是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器.Mysql是一个小型关系型数据库管理系统.PHP是一种在服务器端执行的嵌入HTML文档的脚本语言.这四种软件均为免费开源软件,组合到一