网页爬虫之cookie自动获取及过期自动更新的实现方法
本文实现cookie的自动获取,及cookie过期自动更新。
社交网站中的很多信息需要登录才能获取到,以微博为例,不登录账号,只能看到大V的前十条微博。保持登录状态,必须要用到Cookie。以登录www.weibo.cn 为例:
在chrome中输入:http://login.weibo.cn/login/
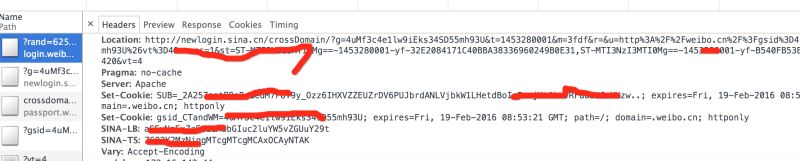
分析控制台的Headers的请求返回,会看到weibo.cn有几组返回的cookie。
实现步骤:
1,采用selenium自动登录获取cookie,保存到文件;
2,读取cookie,比较cookie的有效期,若过期则再次执行步骤1;
3,在请求其他网页时,填入cookie,实现登录状态的保持。
1,在线获取cookie
采用selenium + PhantomJS 模拟浏览器登录,获取cookie;
cookies一般会有多个,逐个将cookie存入以.weibo后缀的文件。
def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict
2,从文件中获取cookie
从当前目录中遍历以.weibo结尾的文件,即cookie文件。采用pickle解包成dict,比较expiry值与当前时间,若过期则返回为空;
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict
3,若缓存cookie过期,则再次从网络获取cookie
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
4,带cookie请求微博其他主页
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...
总结
以上所述是小编给大家介绍的网页爬虫之cookie自动获取及过期自动更新的实现方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- python爬虫中get和post方法介绍以及cookie作用
- python爬虫使用cookie登录详解
- Python爬虫番外篇之Cookie和Session详解
- Python爬虫利用cookie实现模拟登陆实例详解
- 玩转python爬虫之cookie使用方法
- Python中urllib+urllib2+cookielib模块编写爬虫实战
相关推荐
-

Python中urllib+urllib2+cookielib模块编写爬虫实战
超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件.目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问.操作,从而获取我们想要的内容.对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了. 首先要说明的是,urllib2并非是urllib的
-
Python爬虫番外篇之Cookie和Session详解
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么是Cookie 其实简单的说就是当用户通过http协议访问一个服务器的时候,这个服务器会将一些Name/Value键值对返回给客户端浏览器,并将这些数据加上一些限制条件.在条件符合时,这个用户下次再访问服务器的时候,数据又被完整的带给服务器. 因为http是一种无状态协议,用户首次访问web站点的时
-
python爬虫使用cookie登录详解
前言: 什么是cookie? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面,这样就达到了我们的目的. 一.Urllib库简介 Urllib是python内置的HTTP请求库,官方地址:https://docs.python.org/3/library/urllib.ht
-
玩转python爬虫之cookie使用方法
之前一篇文章我们学习了爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了. 在此之前呢,我们必须先介绍一个opener的概念. 1.Opener 当你获取一个URL你
-
Python爬虫利用cookie实现模拟登陆实例详解
Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 举个例子,某些网站是需要登录后才能得到你想要的信息的,不登陆只能是游客模式,那么我们可以利用Urllib2库保存我们以前登录过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取.理解cookie主要是为我们快捷模拟登录抓取目标网页做出准备. 我之前的帖子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有ur
-
python爬虫中get和post方法介绍以及cookie作用
首先确定你要爬取的目标网站的表单提交方式,可以通过开发者工具看到.这里推荐使用chrome. 这里我用163邮箱为例 打开工具后再Network中,在Name选中想要了解的网站,右侧headers里的request method就是提交方式.status如果是200表示成功访问下面的有头信息,cookie是你登录之后产生的存储会话(session)信息的.第一次访问该网页需要提供用户名和密码,之后只需要在headers里提供cookie就可以登陆进去. 引入requests库,会提供get和po
-
网页爬虫之cookie自动获取及过期自动更新的实现方法
本文实现cookie的自动获取,及cookie过期自动更新. 社交网站中的很多信息需要登录才能获取到,以微博为例,不登录账号,只能看到大V的前十条微博.保持登录状态,必须要用到Cookie.以登录www.weibo.cn 为例: 在chrome中输入:http://login.weibo.cn/login/ 分析控制台的Headers的请求返回,会看到weibo.cn有几组返回的cookie. 实现步骤: 1,采用selenium自动登录获取cookie,保存到文件; 2,读取cookie,比较
-
JavaWeb开发使用Cookie创建-获取-持久化、自动登录、购物记录、作用路径
1.cookie是啥?随手百度了网友的说说 简单的说,Cookie就是服务器暂存放在你计算机上的一笔资料,好让服务器用来辨认你的计算机.当你在浏览网站的时候,Web服务器会先送一小小资料放在你的计算机上,当下次你再光临同一个网站,Web服务器会先看看有没有它上次留下的Cookie资料,有的话,就会依据Cookie里的内容来判断使用者,送出特定的网页内容给你. 2.cookie在哪里? 3.cookie可以删除吗? 4.cookie实现原理 第一次请求浏览器,在浏览器的cookie存储区,没有co
-
Python制作简单的网页爬虫
1.准备工作: 工欲善其事必先利其器,因此我们有必要在进行Coding前先配置一个适合我们自己的开发环境,我搭建的开发环境是: 操作系统:Ubuntu 14.04 LTS Python版本:2.7.6 代码编辑器:Sublime Text 3.0 这次的网络爬虫需求背景我打算延续DotNet开源大本营在他的那篇文章中的需求,这里就不再详解.我们只抓取某一省中所有主要城市从2015-11-22到2015-10-24的白天到夜间的所有天气情况.这里以湖北省为例. 2.实战网页爬虫: 2.1.获取城市
-
python网络爬虫之模拟登录 自动获取cookie值 验证码识别的具体实现
目录 1.爬取网页分析 2.验证码识别 3.cookie自动获取 4.程序源代码 chaojiying.py sign in.py 1.爬取网页分析 爬取的目标网址为:https://www.gushiwen.cn/ 在登陆界面需要做的工作有,获取验证码图片,并识别该验证码,才能实现登录. 使用浏览器抓包工具可以看到,登陆界面请求头包括cookie和user-agent,故在发送请求时需要这两个数据.其中user-agent可通过手动添加到请求头中,而cookie值需要自动获取. 分析完毕,实践
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
Python爬虫之用Xpath获取关键标签实现自动评论盖楼抽奖(二)
一.分析链接 上一篇文章指路 一般来说,我们参加某个网站的盖楼抽奖活动,并不是仅仅只参加一个,而是多个盖楼活动一起参加. 这个时候,我们就需要分析评论的链接是怎么区分不同帖子进行评论的,如上篇的刷帖链接,具体格式如下: https://club.hihonor.com/cn/forum.php?mod=post&action=reply&fid=154&tid=21089001&extra=page%3D1&replysubmit=yes&infloat=y
-
Scrapy+Selenium自动获取cookie爬取网易云音乐个人喜爱歌单
此货很干,跟上脚步!!! Cookie cookie是什么东西? 小饼干?能吃吗? 简单来说就是你第一次用账号密码访问服务器 服务器在你本机硬盘上设置一个身份识别的会员卡(cookie) 下次再去访问的时候只要亮一下你的卡片(cookie) 服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上 需求分析 爬虫要访问一些私人的数据就需要用cookie进行伪装 想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去 但是在火狐的F12截取到的数据就是, 网易云音乐先将你的
-
nodeJS实现简单网页爬虫功能的实例(分享)
本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/hotrank var http = require('http'); http.get('http://tuijian.hao123.com/hotrank',function(res){ var data = ''; res.on('data',function(chunk){ data += chunk;
-
Python爬虫设置Cookie解决网站拦截并爬取蚂蚁短租的问题
我们在编写Python爬虫时,有时会遇到网站拒绝访问等反爬手段,比如这么我们想爬取蚂蚁短租数据,它则会提示"当前访问疑似黑客攻击,已被网站管理员设置为拦截"提示,如下图所示.此时我们需要采用设置Cookie来进行爬取,下面我们进行详细介绍.非常感谢我的学生承峰提供的思想,后浪推前浪啊! 一. 网站分析与爬虫拦截 当我们打开蚂蚁短租搜索贵阳市,反馈如下图所示结果. 我们可以看到短租房信息呈现一定规律分布,如下图所示,这也是我们要爬取的信息. 通过浏览器审查元素,我们可以看到需要爬取每条租
-
python自动获取微信公众号最新文章的实现代码
目录 微信公众号获取思路 采集实例 微信公众号获取思路 常用的微信公众号文章获取方法有搜狐.微信公众号主页获取和api接口等多个方法.听说搜狐最近不怎么好用了,之前用的api接口也频繁维护,所以用了微信公众平台来进行数据爬取.首先登陆自己的微信公众平台,没有账号的可以注册一个.进来之后找“图文信息”,就是写公众号的地方 点进去后就是写公众号文章的界面,在界面中找到“超链接” 的字段,在这里就可以对其他的公众号进行检索. 以“python”为例,输入要检索的公众号名称,在显示的公众号中选择要采集的