LZ77压缩算法原理的理解
LZ77压缩算法原理的理解
数据压缩是一个减小数据存储空间的过程,目前被应用在软件工程的各个地方,了解其一些原理,方便我们更好的甄选压缩方案。
压缩方案有很多种,常见的就是有损和无损压缩。霍夫曼编码和LZ77(Lempel-Ziv-1977)都是无损压缩,其中霍夫曼是采用最小冗余编码的算法进行压缩,而LZ77是采用字典的方式进行压缩。关于霍夫曼编码的算法,网上有很多对其详细的讲解,我们本篇幅不在细说,主要图解一下LZ77压缩算法的方式,看看其有哪些优缺点。
信息熵
数据为何是可以压缩的,因为数据都会表现出一定的特性,称为熵。绝大多数的数据所表现出来的容量往往大于其熵所建议的最佳容量。比如所有的数据都会有一定的冗余性,我们可以把冗余的数据采用更少的位对频繁出现的字符进行标记,也可以基于数据的一些特性基于字典编码,代替重复多余的短语。
LZ77算法原理
LZ77压缩算法采用字典的方式进行压缩,是一个简单但十分高效的数据压缩算法。其方式就是把数据中一些可以组织成短语(最长字符)的字符加入字典,然后再有相同字符出现采用标记来代替字典中的短语,如此通过标记代替多数重复出现的方式以进行压缩。要理解这种算法,我们先了解3个关键词:短语字典,滑动窗口和向前缓冲区。
关键词:
1.前向缓冲区
每次读取数据的时候,先把一部分数据预载入前向缓冲区。为移入滑动窗口做准备
2.滑动窗口
一旦数据通过缓冲区,那么它将移动到滑动窗口中,并变成字典的一部分。
3.短语字典
从字符序列S1...Sn,组成n个短语。比如字符(A,B,D) ,可以组合的短语为{(A),(A,B),(A,B,D),(B),(B,D),(D)},如果这些字符在滑动窗口里面,就可以记为当前的短语字典,因为滑动窗口不断的向前滑动,所以短语字典也是不断的变化。
LZ77的主要算法逻辑就是,先通过前向缓冲区预读数据,然后再向滑动窗口移入(滑动窗口有一定的长度),不断的寻找能与字典中短语匹配的最长短语,然后通过标记符标记。我们还以字符ABD为例子,看如下图:
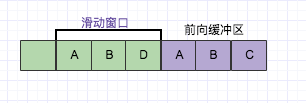
目前从前向缓冲区中可以和滑动窗口中可以匹配的最长短语就是(A,B),然后向前移动的时候再次遇到(A,B)的时候采用标记符代替。
压缩
当压缩数据的时候,前向缓冲区与移动窗口之间在做短语匹配的是后会存在2种情况:
- 找不到匹配时:将未匹配的符号编码成符号标记(多数都是字符本身)
- 找到匹配时:将其最长的匹配编码成短语标记。
- 短语标记包含三部分信息:(滑动窗口中的偏移量(从匹配开始的地方计算)、匹配中的符号个数、匹配结束后的前向缓冲区中的第一个符号)。
一旦把n个符号编码并生成响应的标记,就将这n个符号从滑动窗口的一端移出,并用前向缓冲区中同样数量的符号来代替它们,如此,滑动窗口中始终有最新的短语。
我们采用图例来看:
1、开始

2、滑动窗口中没有数据,所以没有匹配到短语,将字符A标记为A

3、滑动窗口中有A,没有从缓冲区中字符(BABC)中匹配到短语,依然把B标记为B

4、缓冲区字符(ABCB)在滑动窗口的位移6位置找到AB,成功匹配到短语AB,将AB编码为(6,2,C)

5、缓冲区字符(BABA)在滑动窗口位移4的位置匹配到短语BAB,将BAB编码为(4,3,A)

6、缓冲区字符(BCAD)在滑动窗口位移2的位置匹配到短语BC,将BC编码为(2,2,A)

7、缓冲区字符D,在滑动窗口中没有找到匹配短语,标记为D

8、缓冲区中没有数据进入了,结束

解压
解压类似于压缩的逆向过程,通过解码标记和保持滑动窗口中的符号来更新解压数据。
当解码字符标记:将标记编码成字符拷贝到滑动窗口中
解码短语标记:在滑动窗口中查找响应偏移量,同时找到指定长短的短语进行替换。
我们还是采用图例来看下:
1、开始

2、符号标记A解码

3、符号标记B解码

4、短语标记(6,2,C)解码

5、短语标记(4,3,A)解码

6、短语标记(2,2,A)解码

7、符号标记D解码

优缺点
大多数情况下LZ77压缩算法的压缩比相当高,当然了也和你选择滑动窗口大小,以及前向缓冲区大小,以及数据熵有关系。其压缩过程是比较耗时的,因为要花费很多时间寻找滑动窗口中的短语匹配,不过解压过程会很快,因为每个标记都明确告知在哪个位置可以读取了。
以上就是LZ77压缩算法原理的理解,如有疑问请留言或者到本站社区交流讨论,感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-
js LZ77算法的实现代码
所以钻研了一段时间的gzip,后来发现还是仅用LZ77 比较容易实现,gzip中的 haffman 压缩部分对于JS来说太难搞了. 代码如下,注释的非常完整,所以就不多说了,有兴趣的可以仔细研究下: LZ77 * { font-size:12px; } body { overflow:auto; background-color:buttonface; } textarea { width:100%; height:240px; overflow:auto; } #btn1 { width:10
-

LZ77压缩算法原理的理解
LZ77压缩算法原理的理解 数据压缩是一个减小数据存储空间的过程,目前被应用在软件工程的各个地方,了解其一些原理,方便我们更好的甄选压缩方案. 压缩方案有很多种,常见的就是有损和无损压缩.霍夫曼编码和LZ77(Lempel-Ziv-1977)都是无损压缩,其中霍夫曼是采用最小冗余编码的算法进行压缩,而LZ77是采用字典的方式进行压缩.关于霍夫曼编码的算法,网上有很多对其详细的讲解,我们本篇幅不在细说,主要图解一下LZ77压缩算法的方式,看看其有哪些优缺点. 信息熵 数据为何是可以压缩的,因为数据
-
JSONP 的原理、理解 与 实例分析
本文实例讲述了JSONP 的原理.理解 与 实例.分享给大家供大家参考,具体如下: 1.什么是jsonp 1.1 同源策略 浏览器同源策略的限制,XmlHttpRequest只允许请求当前源(相同域名.协议.端口)的资源. -1)jsonp只支持get请求 -2)不受同源策略限制 ,兼容性好 不需要XMLHttpRequest(ActiveX)支持,通过js回调函数返回结果 -3)不能解决 不同域的两个页面之间js调用的问题 2. jsonp 原理 动态添加一个script标签,get链接上发送
-
React前端框架实现原理的理解
目录 vdom dsl 的编译 渲染 vdom 组件 状态管理 react 架构的演变 fiber 架构 总结 vdom react 和 vue 都是基于 vdom 的前端框架,我们先聊下 vdom: 为什么 react 和 vue 都要基于 vdom 呢?直接操作真实 dom 不行么? 考虑下这样的场景: 渲染就是用 dom api 对真实 dom 做增删改,如果已经渲染了一个 dom,后来要更新,那就要遍历它所有的属性,重新设置,比如 id.clasName.onclick 等. 而 dom
-
JavaScript前端构建工具原理的理解
目录 前言 构建工具的前世今生 YUI Tool + Ant Grunt / Gulp Webpack / Rollup / Parcel Vite / Esbuild js 模块化的发展史和构建工具的变化 青铜时代 白银时代 黄金时代 结束语 前言 最近有幸在前端团队里面做了一次关于 webpack 的技术分享.在分享的准备过程中,为了能让大家更好的理解 webpack,特意对市面上以前和现在流行的构建工具做了一个梳理总结.在整理和分享的过程中,获益匪浅,对前端构建工具有了新的认识.在这里,将
-
C++ 多态虚函数的底层原理深入理解
目录 1 多态的基本概念 1.1 什么是多态? 1.2 怎么实现多态 2 虚函数的底层原理 1 多态的基本概念 1.1 什么是多态? 多态是在不同继承关系的类对象,去调用同一函数,产生了不同的行为,通常是父类调用子类的重写函数,在C++中就是 父类指针指向子类对象,此时父类指针的向下引用就可以实现多态 比如看下面的代码: class Animal { public: //虚函数 virtual void speak() { cout << "动物在说话" <<
-
React Context原理深入理解源码示例分析
目录 正文 一.概念 二.使用 2.1.React.createContext 2.2.Context.Provider 2.3.React.useContext 2.4.Example 三.原理分析 3.1.createContext 函数实现 3.2. JSX 编译 3.3.消费组件 - useContext 函数实现 3.4.Context.Provider 在 Fiber 架构下的实现机制 3.5.小结 四.注意事项 五.对比 useSelector 正文 在 React 中提供了一种「
-
Java并发之synchronized实现原理深入理解
目录 synchronized的三种应用方式 synchronized作用于实例方法 synchronized作用于静态方法 synchronized同步代码块 synchronized底层语义原理 理解Java对象头与Monitor synchronized代码块底层原理 synchronized方法底层原理 Java虚拟机对synchronized的优化 偏向锁 轻量级锁 自旋锁 锁消除 关于synchronized 可能需要了解的关键点 synchronized的可重入性 线程中断与syn
-
java 中HashMap实现原理深入理解
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O(1):数组的特点是:寻址容易,插入和删除困难: 链表 链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N).链表的特点是:寻址困难,插入和删除容易. 哈希表 那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提
-
Ajax工作原理深入理解
1.ajax技术的背景 不可否认,ajax技术的流行得益于google的大力推广,正是由于google earth.google suggest以及gmail等对ajax技术的广泛应用,催生了ajax的流行.而这也让微软感到无比的尴尬,因为早在97年,微软便已经发明了ajax中的关键技术,并且在99年IE5推出之时,它便开始支持XmlHttpRequest对象,并且微软之前已经开始在它的一些产品中应用ajax,比如说MSDN网站菜单中的一些应用.遗憾的是,不知道出于什么想法,当时微软发明了aja
-
HashMap原理的深入理解
hashing(散列法或哈希法)的概念 散列法(Hashing)是一种将字符组成的字符串转换为固定长度(一般是更短长度)的数值或索引值的方法,称为散列法,也叫哈希法.由于通过更短的哈希值比用原始值进行数据库搜索更快,这种方法一般用来在数据库中建立索引并进行搜索,同时还用在各种解密算法中. HashMap概念和底层结构 HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.HashMap储存的是键值对,HashMap很快.此类不保证映射