使用coverage统计python web项目代码覆盖率的方法详解
本文实例讲述了使用coverage统计python web项目代码覆盖率的方法。分享给大家供大家参考,具体如下:
在使用python+selenium过程中,有时候考虑代码覆盖率,所以专门查了一下python的coverage,所以特此记录
1.安装coverage
自己电脑安装了pip的 直接: pip install coverage,等待安装完成
安装完成后,会在C:\Python27\Scripts下看到相关的安装信息;
2.安装完成以后,就是开始使用了
2.1核心参数---run
以前执行一个.py的文件方式: python test.py
现在使用coverage执行.py的文件方式: coverage run test.py ,跑完后,会自动生成一个覆盖率统计结果文件(data file):.coverage
这个文件在你的text.py的文件对应目录下
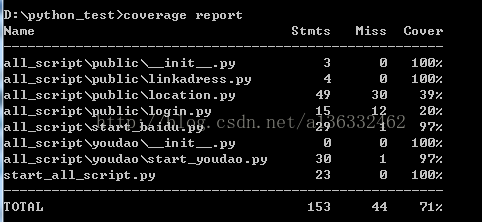
2.2核心参数---report
有了覆盖率统计结果文件,只需要再运行report参数,就可以在命令里看到统计的结果。
2.3核心参数---生成html
最帅最酷的功能了,直接生成html的测试报告。
testhtml是你要生成的html文件夹的名称,这个可以自定义,生成的文件同样在你的.py的文件目录下
这里有一个的预览的html文件,点击可以看看效果
http://nedbatchelder.com/files/sample_coverage_html/,里面对于覆盖于未覆盖的代码都有高亮显示,这个就不多说了
html参数说明:
| Stmts | 总的有效代码行数(不包含空行和注释行) |
| Miss | 未执行的代码行数(不包含空行和注释行) |
| Branch | 总分支数 |
| BrMiss | 未执行的分支数 |
| Cover | 代码覆盖率 |
| Missing | 未执行的代码部分在源文件中行号 |
最后给个忠告:
通过对coverage的学习,其实你用用就会发现,问题还是很多的,所以其实这个的意义也不大,但是聊胜于无;
这是别人总结的,觉得很好,就复制过来了,大家可以想下:
a. 覆盖率数据只能代表你测试过哪些代码,不能代表你是否测试好这些代码。
b. 不要过于相信覆盖率数据。
c. 路径覆盖率 < 判定覆盖 < 语句覆盖
d. 测试人员不能盲目追求代码覆盖率,而应该想办法设计更多更好的案例,哪怕多设计出来的案例对覆盖率一点影响也没有。
关于Python相关内容感兴趣的读者可查看本站专题:《Python函数使用技巧总结》、《Python面向对象程序设计入门与进阶教程》、《Python数据结构与算法教程》、《Python字符串操作技巧汇总》、《Python编码操作技巧总结》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
python统计字母、空格、数字等字符个数的实例
如下所示: # -*- coding: utf-8 -*- # 要求:输入一行字符,分别统计出其中英文字母.空格.数字和其它字符的个数. def count(s): count_a=count_z=count_o=count_s=0 for i in s: if (ord(i)>=97 and ord(i)<=122) or (ord(i)>=65 and ord(i)<=90): count_a=count_a+1 elif ord(i)>=48 and ord(i)<
-
python统计文本文件内单词数量的方法
本文实例讲述了python统计文本文件内单词数量的方法.分享给大家供大家参考.具体实现方法如下: # count lines, sentences, and words of a text file # set all the counters to zero lines, blanklines, sentences, words = 0, 0, 0, 0 print '-' * 50 try: # use a text file you have, or google for this one
-
Python实现统计单词出现的个数
最近在看python脚本语言,脚本语言是一种解释性的语言,不需要编译,可以直接用,由解释器来负责解释.python语言很强大,而且写起来很简洁.下面的一个例子就是用python统计单词出现的个数. import sys import string #import collections if len(sys.argv) == 1 or sys.argv[1] in {"-h", "--help"}: print("usage: uniqueword fil
-
python用字典统计单词或汉字词个数示例
有如下格式的文本文件 复制代码 代码如下: /"/请/!/"/"/请/!/"/两名/剑士/各自/倒转/剑尖/,/右手/握/剑柄/,/左手/搭于/右手/手背/,/躬身行礼/./两/人/身子/尚未/站/直/,/突然/间/白光闪/动/,/跟着/铮的/一/声响/,/双剑相/交/,/两/人/各/退一步/./旁/观众/人/都/是/"/咦/"/的/一声/轻呼/./青衣/剑士/连/劈/三/剑/ 将这段话进行词频统计,结果是 词-词数 的形式,比如 请 2
-

python实现简单中文词频统计示例
本文介绍了python实现简单中文词频统计示例,分享给大家,具体如下: 任务 简单统计一个小说中哪些个汉字出现的频率最高 知识点 1.文件操作 2.字典 3.排序 4.lambda 代码 import codecs import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体 mpl.rcParams['axes.unicode_minus
-
Python统计列表中的重复项出现的次数的方法
本文实例展示了Python统计列表中的重复项出现的次数的方法,是一个很实用的功能,适合Python初学者学习借鉴.具体方法如下: 对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在我们需要统计这个列表里的重复项,并且重复了几次也要统计出来. 方法1: mylist = [1,2,2,2,2,3,3,3,4,4,4,4] myset = set(mylist) #myset是另外一个列表,里面的内容是mylist里面的无重复 项 for item in myset: prin
-
Python实现对excel文件列表值进行统计的方法
本文实例讲述了Python实现对excel文件列表值进行统计的方法.分享给大家供大家参考.具体如下: #!/usr/bin/env python #coding=gbk #此PY用来统计一个execl文件中的特定一列的值的分类 import win32com.client filename=raw_input("请输入要统计文件的详细地址:") flag=0 #用于判断文件 名如果不带'日'就为 0 if '\xc8\xd5' in filename:flag=1 print 50*'
-
python统计文本字符串里单词出现频率的方法
本文实例讲述了python统计文本字符串里单词出现频率的方法.分享给大家供大家参考.具体实现方法如下: # word frequency in a text # tested with Python24 vegaseat 25aug2005 # Chinese wisdom ... str1 = """Man who run in front of car, get tired. Man who run behind car, get exhausted."&quo
-
python统计一个文本中重复行数的方法
本文实例讲述了python统计一个文本中重复行数的方法.分享给大家供大家参考.具体实现方法如下: 比如有下面一个文件 2 3 1 2 我们期望得到 2,2 3,1 1,1 解决问题的思路: 出现的文本作为key, 出现的数目作为value,然后按照value排除后输出 最好按照value从大到小输出出来,可以参照: 复制代码 代码如下: in recent Python 2.7, we have new OrderedDict type, which remembers the order in
-
Python3读取UTF-8文件及统计文件行数的方法
本文实例讲述了Python3读取UTF-8文件及统计文件行数的方法.分享给大家供大家参考.具体实现方法如下: ''''' Created on Dec 21, 2012 Python 读取UTF-8文件 统计文件的行数目 @author: liury_lab ''' # -*- coding: utf-8 -*- import codecs # 对较小的文件,最简单的方法是将文件读入一个行列表中, # 然后计算列表的长度即可 count = len(codecs.open('d:/FreakOu