python利用有道翻译实现"语言翻译器"的功能实例
实例如下:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入需要翻译的内容(退出输入Q):')
if content == 'Q':
break
else:
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=http://www.youdao.com/'
data = {}
data['type'] = 'AUTO'
data['i'] = content
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译的结果:%s' % target['translateResult'][0][0]['tgt'])
程序执行情况:
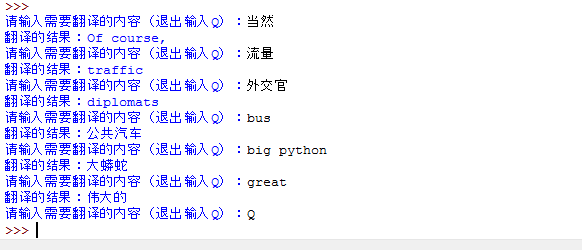
这里要注意的是两个函数urllib.request.urlopen()与urllib.parse.urlencode()。
urllib.request.urlopen()其实不止一个参数,有好几个哦,其中第二个是data,data应该是一个buffer的标准应用程序/ x-www-form-urlencoded格式(python标准库原文:data should be a buffer in the standard application/x-www-form-urlencoded format)。urllib.parse.urlencode()函数接受一个映射或序列集合,并返回一个字符串的格式(python标准库原文:The urllib.parse.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format)。我们可以看看urllib.parse.urlencode()的结果是什么样的:
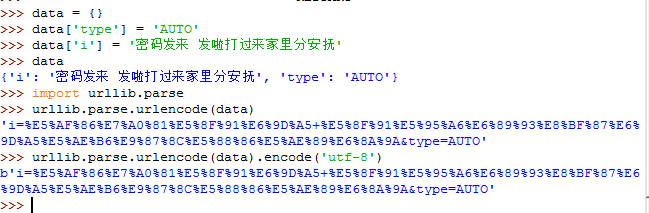
上图的结果刚好与urllib.request.urlopen()的data参数的数据类型要求一致了。
注意,上面urlopen当中的url,这个是分析有道翻译页面的真实的Request URL:
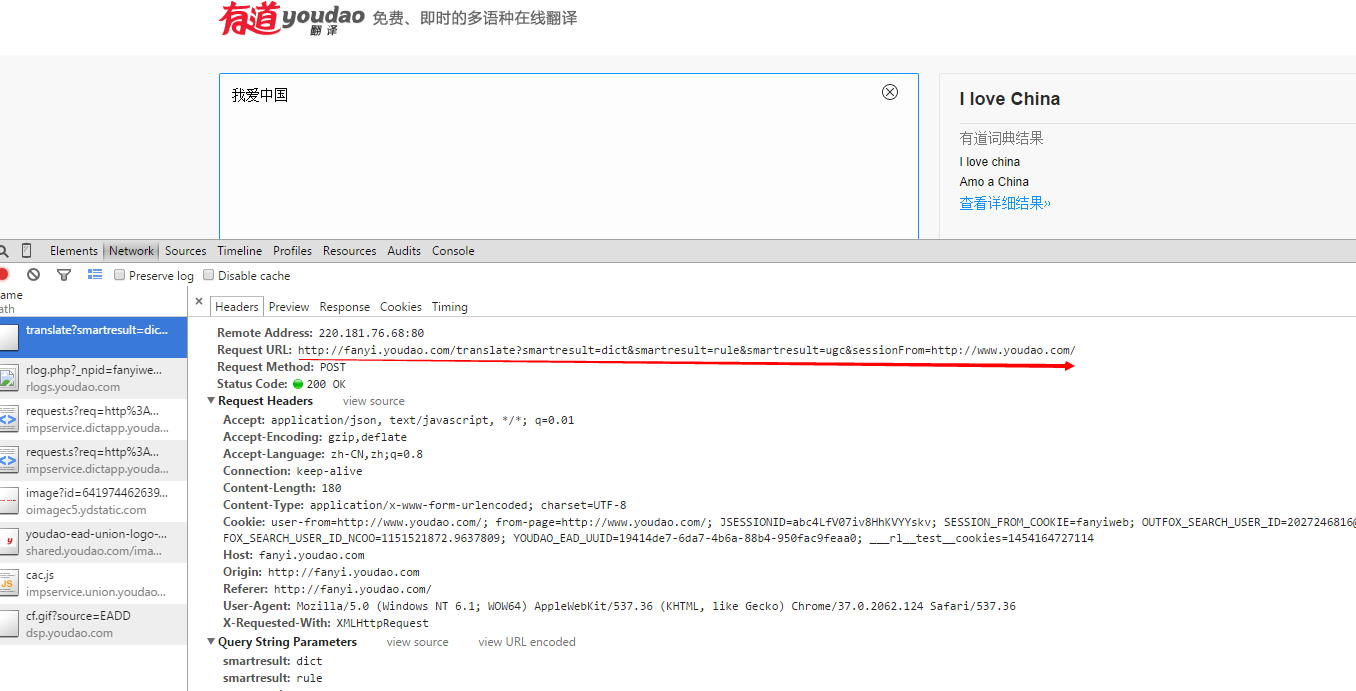
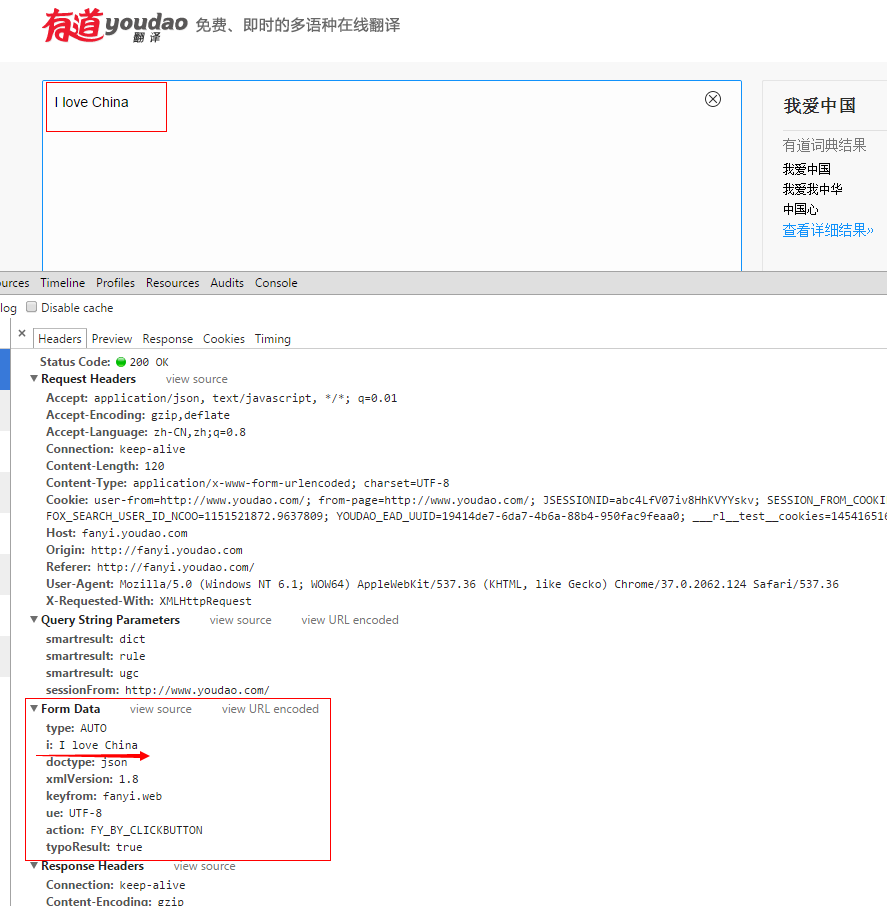
以上这篇python利用有道翻译实现"语言翻译器"的功能实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

用Pygal绘制直方图代码示例
Pygal可用来生成可缩放的矢量图形文件,对于需要在尺寸不同的屏幕上显示的图表,这很有用,可以自动缩放,自适应观看者的屏幕 1.Pygal模块安装 pygal的安装这里暂不介绍,大家可参阅<pip和pygal的安装实例教程> 2.Pygal画廊-直方图 模拟掷骰子,分析最后的结果,生成图形 创建die.py筛子类文件: from random import randint class Die(): '''扔骰子的类''' def __init__(self,num_sides=6): self
-
python字典操作实例详解
本文实例为大家分享了python字典操作实例的具体代码,供大家参考,具体内容如下 #!/usr/bin/env python3 # -*- coding: utf-8 -*- import turtle ##全局变量## #词频排列显示个数 count = 10 #单词频率数组-作为y轴数据 data = [] #单词数组-作为x轴数据 words = [] #y轴显示放大倍数-可以根据词频数量进行调节 yScale = 6 #x轴显示放大倍数-可以根据count数量进行调节 xScale =
-
python GUI实例学习
在学习本篇之前,如果你对Python下进行GUI编程基础内容还有不明白,推荐一篇相关文章:简单介绍利用TK在Python下进行GUI编程的教程 写一个简单的界面很容易,即使是什么都不了解的情况下,这个文本转载了最简单的界面编写,下个文本介绍了TK的简单但具体的应用 在python中创建一个窗口,然后显示出来. from Tkinter import * root = Tk() root.mainloop() 就3行就能够把主窗口显示出来了.root是一个变量名称,其代表了这个主窗口.以后创建控件
-
python中文分词,使用结巴分词对python进行分词(实例讲解)
在采集美女站时,需要对关键词进行分词,最终采用的是python的结巴分词方法. 中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词. 其基本实现原理有三点: 1.基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 2.采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合 3.对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法 安装(Linux环境) 下载工具包,解压后进入目录下,运行:python set
-
Python 将RGB图像转换为Pytho灰度图像的实例
问题: 我正尝试使用matplotlib读取RGB图像并将其转换为灰度. 在matlab中,我使用这个: img = rgb2gray(imread('image.png')); 在matplotlib tutorial中他们没有覆盖它.他们只是在图像中阅读 import matplotlib.image as mpimg img = mpimg.imread('image.png') 然后他们切片数组,但是这不是从我所了解的将RGB转换为灰度. lum_img = img[:,:,0] 编辑:
-
python下10个简单实例代码
注意:我用的python2.7,大家如果用Python3.0以上的版本,请记得在print()函数哦!如果因为版本问题评论的,不做回复哦!!! 1.题目:有1.2.3.4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少? 程序分析:可填在百位.十位.个位的数字都是1.2.3.4.组成所有的排列后再去 掉不满足条件的排列. 程序源代码: # -*- coding: UTF-8 -*- for i in range(1,5): for j in range(1,5): for k in r
-
python密码错误三次锁定(实例讲解)
程序需求: 输入用户名,密码 认证成功显示欢迎信息 输入错误三次后锁定用户 流程图: 好像画的不咋地 查看代码: #!/usr/bin/env python # _*_ coding:utf-8 _*_ # File_type:一个登录接口 # Author:smelond import os username = "smelond"#用户名 password = "qweqwe"#密码 counter = 0#计数器 #读取黑名单 file = os.path.e
-
Python2与python3中 for 循环语句基础与实例分析
下面的代码中python2与python3的print使用区别,大家注意一下.python3需要加()才行. 语法: for循环的语法格式如下: for iterating_var in sequence: statements(s) 流程图: 实例: #!/usr/bin/python # -*- coding: UTF-8 -*- for letter in 'jb51.net': # 第一个实例 print '当前字母 :', letter fruits = ['banana', 'app
-
python利用有道翻译实现"语言翻译器"的功能实例
实例如下: import urllib.request import urllib.parse import json while True: content = input('请输入需要翻译的内容(退出输入Q):') if content == 'Q': break else: url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom
-
python利用有道翻译实现"语言翻译器"的功能实例
实例如下: import urllib.request import urllib.parse import json while True: content = input('请输入需要翻译的内容(退出输入Q):') if content == 'Q': break else: url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom
-
如何基于Python制作有道翻译小工具
这篇文章主要介绍了如何基于Python制作有道翻译小工具,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 该工具主要是利用了爬虫,爬取web有道翻译的内容. 然后利用简易GUI来可视化结果. 首先我们进入有道词典的首页,并点击翻译结果的审查元素 之后request响应网页,并分析网页,定位到翻译结果. 使用tkinter来制作一个建议的GUI 期间遇到的一个问题则是如何刷新翻译的结果,否则的话会在text里一直累加翻译结果. 于是,在mainlo
-
Python 调用有道翻译接口实现翻译
最近为了熟悉一下 js 用有道翻译练了一下手,写一篇博客记录一下,也希望能对大家有所启迪,不过这些网站更新太快,可能大家尝试的时候会有所不同. 首先来看一下网页 post 过去的数据 大家不难发现,我们翻译的内容是放在 post 的 data 中的,这些参数,除了 salt 和 sign 要么就是不会变化,要么就是一眼能看出来意义的:那么这个 salt 和 sign 是什么呢?salt 根据 ta 数据的特征,我们应该会想到,这应该是一个时间戳,而 sign 又是什么呢?我们一起来看一下 找到这
-
python 实现有道翻译功能
初期操作 打开有道翻译界面-F12-Network-在翻译框中输入'hello'-在Network下面发现名为'translate_o?smartresult......'返回翻译之后的数据 分析参数 把所有的Request Headers.params都写上尝试爬虫,可以得到结果. 然后Request Headers中Headers.Host.Origin.Referer三项留下,Cookie一项经尝试只有 OUTFOX_SEARCH_USER_ID=-1927650476@223.97.
-
Python调用百度AI实现图片上文字识别功能实例
目录 简介 步骤 安装百度AI库 注册百度AI开放平台 调用glob库 调用AipOcr库识别文字 可能会遇到的问题 批量操作 总结 简介 Python免费调用百度AI实现图片上面的文字识别 步骤 安装百度AI库 !pip install baidu-aip 注册百度AI开放平台 先注册百度AI,获得ID和密钥.注册方法可参考:注册方法 只需走到 "1.6 获取密钥" 即可.然后记录下自己的APP_ID.API_KEY.SECRET_KEY,就可以开始了. 调用glob库 glob库用
-
Python利用multiprocessing实现最简单的分布式作业调度系统实例
介绍 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上.一个服务进程可以作为调度者,将任务分布到其他多个机器的多个进程中,依靠网络通信.想到这,就在想是不是可以使用此模块来实现一个简单的作业调度系统.在这之前,我们先来详细了解下python中的多进程管理包multiprocessing. multiprocessing.Process multiprocessing包是Python中的多进程管理包.它与 threading.
-
python 简单的调用有道翻译
代码 import json import requests # 翻译函数,word 需要翻译的内容 def translate(word): # 有道词典 api url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null' # 传输的参数,其中 i 为需要翻译的内容 key = { 'type': "AUTO&qu
-
Python利用PySimpleGUI实现自制桌面翻译神器
目录 一.基本思路 二.PySimpleGUI是什么 三.代码分析 1.引入包 2.谷歌翻译网址 3.构建翻译函数 4.GUI构建 四.Github开源地址 一.基本思路 基于PySimpleGUI开发桌面GUI→获取键盘输入→接入谷歌翻译API→爬虫获取翻译结果[其中涉及到正则表达式匹配翻译结果输出翻译结果口翻译完成. 二.PySimpleGUI是什么 创建图形用户界面(GUI)可能很困难,有许多不同的PythonGUI工具包可供选择.最常提到的前三名是 Tkinter,wxPython和Py
-
Python通过调用有道翻译api实现翻译功能示例
本文实例讲述了Python通过调用有道翻译api实现翻译功能.分享给大家供大家参考,具体如下: 通过调用有道翻译的api,实现中译英.其他语言译中文 Python代码: # coding=utf-8 import urllib import urllib2 import json import time import hashlib class YouDaoFanyi: def __init__(self, appKey, appSecret): self.url = 'https://open