Python之多线程爬虫抓取网页图片的示例代码
目标
嗯,我们知道搜索或浏览网站时会有很多精美、漂亮的图片。
我们下载的时候,得鼠标一个个下载,而且还翻页。
那么,有没有一种方法,可以使用非人工方式自动识别并下载图片。美美哒。
那么请使用python语言,构建一个抓取和下载网页图片的爬虫。
当然为了提高效率,我们同时采用多线程并行方式。
思路分析
Python有很多的第三方库,可以帮助我们实现各种各样的功能。问题在于,我们弄清楚我们需要什么:
1)http请求库,根据网站地址可以获取网页源代码。甚至可以下载图片写入磁盘。
2)解析网页源代码,识别图片连接地址。比如正则表达式,或者简易的第三方库。
3)支持构建多线程或线程池。
4)如果可能,需要伪造成浏览器,或绕过网站校验。(嗯,网站有可能会防着爬虫 ;-))
5)如果可能,也需要自动创建目录,随机数、日期时间等相关内容。
如此,我们开始搞事情。O(∩_∩)O~
环境配置
操作系统:windows 或 linux 皆可
Python版本:Python3.6 ( not Python 2.x 哦)
第三方库
urllib.request
threading 或者 concurrent.futures 多线程或线程池(python3.2+)
re 正则表达式内置模块
os 操作系统内置模块
编码过程
我们分解一下过程。完整源代码在博文最终提供。
伪装为浏览器
import urllib.request
# ------ 伪装为浏览器 ---
def makeOpener(head={
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
获取网页源代码
# ------ 获取网页源代码 ---
# url 网页链接地址
def getHtml(url):
print('url='+url)
oper = makeOpener()
if oper is not None:
page = oper.open(url)
#print ('-----oper----')
else:
req=urllib.request.Request(url)
# 爬虫伪装浏览器
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0')
page = urllib.request.urlopen(req)
html = page.read()
if collectHtmlEnabled: #是否采集html
with open('html.txt', 'wb') as f:
f.write(html) # 采集到本地文件,来分析
# ------ 修改html对象内的字符编码为UTF-8 ------
if chardetSupport:
cdt = chardet.detect(html)
charset = cdt['encoding'] #用chardet进行内容分析
else:
charset = 'utf8'
try:
result = html.decode(charset)
except:
result = html.decode('gbk')
return result
下载单个图片
# ------ 根据图片url下载图片 ------
# folderPath 定义图片存放的目录 imgUrl 一个图片的链接地址 index 索引,表示第几个图片
def downloadImg(folderPath, imgUrl, index):
# ------ 异常处理 ------
try:
imgContent = (urllib.request.urlopen(imgUrl)).read()
except urllib.error.URLError as e:
if printLogEnabled : print ('【错误】当前图片无法下载')
return False
except urllib.error.HTTPError as e:
if printLogEnabled : print ('【错误】当前图片下载异常')
return False
else:
imgeNameFromUrl = os.path.basename(imgUrl)
if printLogEnabled : print ('正在下载第'+str(index+1)+'张图片,图片地址:'+str(imgUrl))
# ------ IO处理 ------
isExists=os.path.exists(folderPath)
if not isExists: # 目录不存在,则创建
os.makedirs( folderPath )
#print ('创建目录')
# 图片名命名规则,随机字符串
imgName = imgeNameFromUrl
if len(imgeNameFromUrl) < 8:
imgName = random_str(4) + random_str(1,'123456789') + random_str(2,'0123456789')+"_" + imgeNameFromUrl
filename= folderPath + "\\"+str(imgName)+".jpg"
try:
with open(filename, 'wb') as f:
f.write(imgContent) # 写入本地磁盘
# if printLogEnabled : print ('下载完成第'+str(index+1)+'张图片')
except :
return False
return True
下载一批图片(多线程/线程池模式皆支持)
# ------ 批量下载图片 ------
# folderPath 定义图片存放的目录 imgList 多个图片的链接地址
def downloadImgList(folderPath, imgList):
index = 0
# print ('poolSupport='+str(poolSupport))
if not poolSupport:
#print ('多线程模式')
# ------ 多线程编程 ------
threads = []
for imgUrl in imgList:
# if printLogEnabled : print ('准备下载第'+str(index+1)+'张图片')
threads.append(threading.Thread(target=downloadImg,args=(folderPath,imgUrl,index,)))
index += 1
for t in threads:
t.setDaemon(True)
t.start()
t.join() #父线程,等待所有线程结束
if len(imgList) >0 : print ('下载结束,存放图片目录:' + str(folderPath))
else:
#print ('线程池模式')
# ------ 线程池编程 ------
futures = []
# 创建一个最大可容纳N个task的线程池 thePoolSize 为 全局变量
with concurrent.futures.ThreadPoolExecutor(max_workers=thePoolSize) as pool:
for imgUrl in imgList:
# if printLogEnabled : print ('准备下载第'+str(index+1)+'张图片')
futures.append(pool.submit(downloadImg, folderPath, imgUrl, index))
index += 1
result = concurrent.futures.wait(futures, timeout=None, return_when='ALL_COMPLETED')
suc = 0
for f in result.done:
if f.result(): suc +=1
print('下载结束,总数:'+str(len(imgList))+',成功数:'+str(suc)+',存放图片目录:' + str(folderPath))
调用例子
如百度贴吧为例
# ------ 下载百度帖子内所有图片 ------
# folderPath 定义图片存放的目录 url 百度贴吧链接
def downloadImgFromBaidutieba(folderPath='tieba', url='https://tieba.baidu.com/p/5256331871'):
html = getHtml(url)
# ------ 利用正则表达式匹配网页内容找到图片地址 ------
#reg = r'src="(.*?\.jpg)"'
reg = r'src="(.*?/sign=.*?\.jpg)"'
imgre = re.compile(reg);
imgList = re.findall(imgre, html)
print ('找到图片个数:' + str(len(imgList)))
# 下载图片
if len(imgList) >0 : downloadImgList(folderPath, imgList)
# 程序入口
if __name__ == '__main__':
now = datetime.datetime.now().strftime('%Y-%m-%d %H-%M-%S')
# 下载百度帖子内所有图片
downloadImgFromBaidutieba('tieba\\'+now, 'https://tieba.baidu.com/p/5256331871')
效果


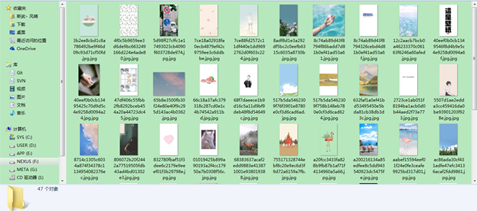
完整源码请见
我的github:https://github.com/SvenAugustus/PicDownloader-example
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

使用Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. 先来简单介绍一下,网络爬虫的基本实现原理吧.一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新的URL插入到队列中作为下一次爬取的起点.这样不断地循环,一直到获得你想得到的所有的信息爬虫的任务
-
python实现爬虫统计学校BBS男女比例之多线程爬虫(二)
接着第一篇继续学习. 一.数据分类 正确数据:id.性别.活动时间三者都有 放在这个文件里file1 = 'ruisi\\correct%s-%s.txt' % (startNum, endNum) 数据格式为293001 男 2015-5-1 19:17 没有时间:有id.有性别,无活动时间 放这个文件里file2 = 'ruisi\\errTime%s-%s.txt' % (startNum, endNum) 数据格式为2566 女 notime 用户不存在:该id没有对应的用户 放这个文件
-
php与python实现的线程池多线程爬虫功能示例
本文实例讲述了php与python实现的线程池多线程爬虫功能.分享给大家供大家参考,具体如下: 多线程爬虫可以用于抓取内容了这个可以提升性能了,这里我们来看php与python 线程池多线程爬虫的例子,代码如下: php例子 <?php class Connect extends Worker //worker模式 { public function __construct() { } public function getConnection() { if (!self::$ch) { sel
-
Python 爬虫学习笔记之多线程爬虫
XPath 的安装以及使用 1 . XPath 的介绍 刚学过正则表达式,用的正顺手,现在就把正则表达式替换掉,使用 XPath,有人表示这太坑爹了,早知道刚上来就学习 XPath 多省事 啊.其实我个人认为学习一下正则表达式是大有益处的,之所以换成 XPath ,我个人认为是因为它定位更准确,使用更加便捷.可能有的人对 XPath 和正则表达式的区别不太清楚,举个例子来说吧,用正则表达式提取我们的内容,就好比说一个人想去天安门,地址的描述是左边有一个圆形建筑,右边是一个方形建筑,你去找吧,而使
-
Python多线程爬虫简单示例
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
Python3多线程爬虫实例讲解代码
多线程概述 多线程使得程序内部可以分出多个线程来做多件事情,充分利用CPU空闲时间,提升处理效率.python提供了两个模块来实现多线程thread 和threading ,thread 有一些缺点,在threading 得到了弥补.并且在Python3中废弃了thread模块,保留了更强大的threading模块. 使用场景 在python的原始解释器CPython中存在着GIL(Global Interpreter Lock,全局解释器锁),因此在解释执行python代码时,会产生互斥锁来限
-
Python多线程爬虫实战_爬取糗事百科段子的实例
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike.com/8hr/page/页码/ 多线程爬虫也就和JAVA的多线程差不多,直接上代码 ''' #此处代码为普通爬虫 import urllib.request import urllib.error import re headers = ("User-Agent","Mozilla/5.0
-
基python实现多线程网页爬虫
一般来说,使用线程有两种模式, 一种是创建线程要执行的函数, 把这个函数传递进Thread对象里,让它来执行. 另一种是直接从Thread继承,创建一个新的class,把线程执行的代码放到这个新的class里. 实现多线程网页爬虫,采用了多线程和锁机制,实现了广度优先算法的网页爬虫. 先给大家简单介绍下我的实现思路: 对于一个网络爬虫,如果要按广度遍历的方式下载,它是这样的: 1.从给定的入口网址把第一个网页下载下来 2.从第一个网页中提取出所有新的网页地址,放入下载列表中 3.按下载列表中的地
-
Python多线程、异步+多进程爬虫实现代码
安装Tornado 省事点可以直接用grequests库,下面用的是tornado的异步client. 异步用到了tornado,根据官方文档的例子修改得到一个简单的异步爬虫类.可以参考下最新的文档学习下. pip install tornado 异步爬虫 #!/usr/bin/env python # -*- coding:utf-8 -*- import time from datetime import timedelta from tornado import httpclient, g
-
Python 爬虫多线程详解及实例代码
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread