MySQL优化中B树索引知识点总结
为什么要进行SQL优化呢?很显然,当我们去写sql语句时:
- 1会发现性能低
- 2.执行时间太长,
- 3.或等待时间太长
- 4.sql语句欠佳,以及我们索引失效
- 5.服务器参数设置不合理
SQL语句执行过程分析
1.编写过程:
编写过程就是我们平常写sql语句的过程,也可以理解为编写顺序,以下就是我们编写顺序:
select from join on where 条件 group by 分组 having过滤组 order by排序 limit限制查询个数
我们虽然是这样去写的,但是它mysql的引擎去解析时,并不是依照我们以上编写的这样的顺序;
它并不是先解析select 而是先解析from,也就说,我们的解析过程跟编写过程是不一致的,所以我们看下发的解析顺序
2.解析过程:
from on join where group by having select order by limit
以上就是mysql的解析过程,我们发现,跟我们编写的过程完全不一致!
索引
什么是索引(index)?简单的来讲就是书的目录;
比如说我现在要通过字典来查“王”这个字,如果你在没有目录的情况下去找“王”这个字,你就需要把这个字典从头到尾的翻一遍,如果有一千页,你就必须一页一页的去翻,直到找到为止;
索引就相当于目录,查这个“王”之前先去翻看目录,发现“W”在300页,因为王首字母是“W”,我们直接去在300页中找,这样找起来就非常快;
索引在数据库中是关键字insex,用官方的定义的意思来说,索引就是帮助MySQL快速高效的获取数据的数据结构;
索引是一个数据结构,它是一个为了高效查询数据的数据结构;
那它到底是什么数据结构呢?
其实它就是一个树,我们用的比较多的就是B树、Hash树,在MySQL里面,用的就是B树索引;
B树索引
首先我画一个图,假装这个是数据表,并且给age列加一个索引:
就把这个索引当成一个目录,也就是age为50的,就指向第一行,age为33的,指向第五行;
下面我会将B树索引画出来,看看到底是怎么索引了:
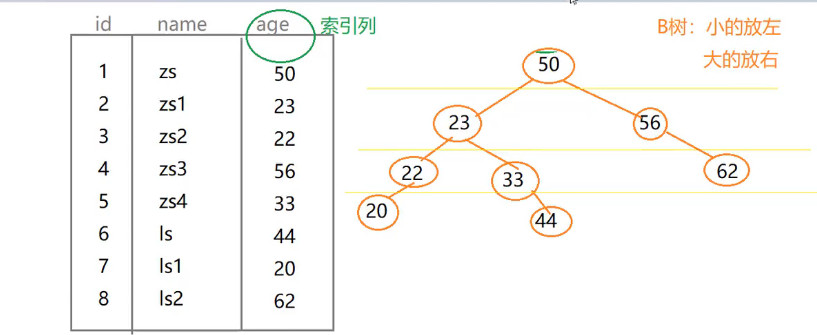
我们给age加了索引列后,它就会像树一样,把小的放到左边,把大的放到右边,第一列为50,比50小的在左边,23,比23小的继续向左排列,
33比23大,就向左排列20比22小就在22后面继续向左排列,以此类推!
比如我们现在需要查33:
select * From 表名 where age = 33;
不加索引的话,就会从50开始查,50不是 23,不是22不是....,不加索引就一个个去找;
如果加索引的话,找33,发现33比50小,第一次,再去找23,第二次,33比23大,第三次,仅需三次就查到了:

索引的弊端
1.索引本身很占空间,可以存放在内存/硬盘(通常)
2.索引不是所有情况均可适用比如:少量数据、频繁更新的字段(如果数据表中的某一列经常会发生改变,那么这一列就不适合做索引)
3.索引确实可以提高查询效率,但是同时会降低增删改的效率,比如:
我们没有索引,你改44,改成45,很好改,直接改就行了,如果你有索引,我不光要改表里面的44,我需要把B树里面的44也要改:

有些人就觉得不划算了,提升一个降低三个,这样就很不划算了,其实很划算的!
因为我们大部分情况下都是在查询,增删改很少,因为查询影响性能很大的,所以非常有必要使用它
索引的优势
1.提高了查询效率
客户端到服务端,链接服务端是通过IO,通过输入输出流,所以说,提高查询效率就是降低了IO的使用率
2.降低CPU使用率
比如说我sql里面有一个order by desc 根据年龄降序或升序,如果没有索引,你需要把age全部拿出来全部排个序,但是如果有了索引,你就不需要排序了,B树本身就是一个排好序的结构,最左边必然是最小的,最最右边必然是最大的:

只需要根据一定的规则遍历出来就行了。
以上就是相关的B数索引的相关知识点,感谢大家的阅读和对我们的支持。
相关推荐
-

完整B树算法Java实现代码
定义 在计算机科学中,B树(英语:B-tree)是一种自平衡的树,能够保持数据有序.这种数据结构能够让查找数据.顺序访问.插入数据及删除的动作,都在对数时间内完成. 为什么要引入B树? 首先,包括前面我们介绍的红黑树是将输入存入内存的一种内部查找树. 而B树是前面平衡树算法的扩展,它支持保存在磁盘或者网络上的符号表进行外部查找,这些文件可能比我们以前考虑的输入要大的多(难以存入内存). 既然内容保存在磁盘中,那么自然会因为树的深度过大而造成磁盘I/O读写过于频繁(磁盘读写速率是有限制的),进而导
-
c语言B树深入理解
B树是为磁盘或其他直接存储设备设计的一种平衡查找树.如下图所示.每一个结点箭头指向的我们称为入度,指出去的称为出度.树结构的结点入度都是1,不然就变成图了,所以我们一般说树的度就是指树结点的出度,也就是一个结点的子结点个数.有了度的概念我们就简单定义一下B树(假设一棵树的最小度数为M):1.每个结点至少有M-1个关键码,至多有2M-1个关键码:2.除根结点和叶子结点外,每个结点至少有M个子结点,至多有2M个子结点:3.根结点至少有2个子结点,唯一例外是只有根结点的情况,此时没有子结点:4.所有叶
-
数据结构-树(三):多路搜索树B树、B+树
多路搜索树 完全二叉树高度:O(log2N),其中2为对数 完全M路搜索树的高度:O(logmN),其中M为对数,树每层的节点数 M路搜索树主要用于解决数据量大无法全部加载到内存的数据存储.通过增加每层节点的个数和在每个节点存放更多的数据来在一层中存放更多的数据,从而降低树的高度,在数据查找时减少磁盘访问次数. 所以每层的节点数和每个节点包含的关键字越多,则树的高度越矮.但是在每个节点确定数据就越慢,但是B树关注的是磁盘性能瓶颈,所以在单个节点搜索数据的开销可以忽略. B树 B树是一种M路搜索
-
浅谈MySQL的B树索引与索引优化小结
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引结构,理解常见的MySQL索引优化思路? 为什么索引无法全部装入内存 索引结构的选择基于这样一个性质:大数据量时,索引无法全部装入内存. 为什么索引无法全部装入内存?假设使用树结构组织索引,简单估算一下: 假设单个索引节点12B,1000w个数据行,unique索引,则叶子节点共占约100MB,整棵树最多20
-
MySQL优化中B树索引知识点总结
为什么要进行SQL优化呢?很显然,当我们去写sql语句时: 1会发现性能低 2.执行时间太长, 3.或等待时间太长 4.sql语句欠佳,以及我们索引失效 5.服务器参数设置不合理 SQL语句执行过程分析 1.编写过程: 编写过程就是我们平常写sql语句的过程,也可以理解为编写顺序,以下就是我们编写顺序: select from join on where 条件 group by 分组 having过滤组 order by排序 limit限制查询个数 我们虽然是这样去写的,但是它mysql的引擎去
-
Mysql InnoDB中B+树索引使用注意事项
目录 一.根页面万年不动 二.内节点中目录项记录的唯一性 三.一个页面至少容纳 2 条记录 一.根页面万年不动 在之前的文章里,为了方便理解,都是先画存储用户记录的叶子节点,然后再画出存储目录项记录的内节点. 但实际上 B+ 树的行成过程是这样的: 每当为某个表创建一个 B+ 树索引,都会为这个索引创建一个根节点页面.最开始表里没数据,所以根节点中既没有用户记录,也没有目录项记录. 当往表里插入用户记录时,先把用户记录存储到这个根节点上. 当根节点页空间用完,继续插入记录,此时会将根节点中所有记
-
MySQL中B树索引和B+树索引的区别详解
目录 1.多路搜索树 2.B树-多路平衡搜索树 3.B树索引 4.B+树索引 总结 如果用树作为索引的数据结构,每查找一次数据就会从磁盘中读取树的一个节点,也就是一页,而二叉树的每个节点只存储一条数据,并不能填满一页的存储空间,那多余的存储空间岂不是要浪费了?为了解决二叉平衡搜索树的这个弊端,我们应该寻找一种单个节点可以存储更多数据的数据结构,也就是多路搜索树. 1. 多路搜索树 1.完全二叉树高度:O(log2N),其中2为对数,树每层的节点数: 2.完全M路搜索树的高度:O(logmN),其
-
mysql优化之路----hash索引优化
创建表 CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `msg` varchar(20) NOT NULL DEFAULT '', `crcmsg` int(15) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 //插入数据 insert into t1 (msg) values('w
-
探究MySQL优化器对索引和JOIN顺序的选择
本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分"测试环境".这里主要介绍MySQL优化器的主要执行流程,而不是介绍一个优化器的各个组件(这是另一个话题). 我们知道,MySQL优化器只有两个自由度:顺序选择:单表访问方式:这里将详细剖析下面的SQL,看看MySQL优化器如何做出每一步的选择. explain select * from employee as A,department as B where A.LastName = '
-
MySQL批量插入和唯一索引问题的解决方法
MySQL批量插入问题 在开发项目时,因为有一些旧系统的基础数据需要提前导入,所以我在导入时做了批量导入操作 ,但是因为MySQL中的一次可接受的SQL语句大小受限制所以我每次批量虽然只有500条,但依然无法插入,这个时候代码报错如下: nested exception is com.mysql.jdbc.PacketTooBigException: Packet for query is too large (5677854 > 1048576). You can change this va
-
mysql中关于覆盖索引的知识点总结
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为'覆盖索引'. 覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点: 1.索引项通常比记录要小,所以MySQL访问更少的数据. 2.索引都按值得大小存储,相对于随机访问记录,需要更少的I/O. 3.数据引擎能更好的缓存索引,比如MyISAM只缓存索引. 4.覆盖索引对InnoDB尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引包含查询所需的数据,就不再需要在聚集索引中查找了. 限制: 1.
-
Mysql数据库表中为什么有索引却没有提高查询速度
背景 时间过得太快了,春节假期感觉光速般就结束了,转眼间就要继续搬砖上班了.紧接着很快就要进入金三银四的求职面试高峰期,程序猿小枫还没有找到令自己感到满意的工作.就算是在过年放假期间也在拼命的准备技术面试,这不他又梳理了下之前面试过程中面试官经常问到的关于数据库方面的一道面试题,我们来一起帮小枫看看有没有遗漏的地方吧. 面试题目--问题 面试官:看你的简历中有提到过曾经进行过索引优化的工作,那我就问问你,假设数据库表中有索引,但是进行SQL数据查询还是很慢,这种情况下应该怎么分析查询慢的原因?
-
MySQL优化及索引解析
索引简单介绍 索引的本质: MySQL索引或者说其他关系型数据库的索引的本质就只有一句话,以空间换时间. 索引的作用: 索引关系型数据库为了加速对表中行数据检索的(磁盘存储的)数据结构 索引的分类 数据结构上面的分类: HASH 索引 等值匹配效率高 不支持范围查找 树形索引 二叉树,递归二分查找法,左小右大 平衡二叉树,二叉树到平衡二叉树,主要原因是左旋右旋 缺点1,IO次数过多 缺点2,IO利用率不高,IO饱和度 多路平衡查找树(B-Tree) 特点,大大的减少了树的高度 B+树 特点,采用