深入理解happens-before和as-if-serial语义
概述
本文大部分整理自《Java并发编程的艺术》,温故而知新,加深对基础的理解程度。
指令序列的重排序
我们在编写代码的时候,通常自上而下编写,那么希望执行的顺序,理论上也是逐步串行执行,但是为了提高性能,编译器和处理器常常会对指令做重排序。
1) 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2) 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3) 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序:

happens-before语义
从JDK 5开始,Java使用新的内存模型,使用happens-before的概念来阐述操作之间的内存可见性。那到底什么是happens-before呢?
在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系,这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
happens-before规则如下:
程序顺序规则: 对于单个线程中的每个操作,前继操作happens-before于该线程中的任意后续操作。
监视器锁规则: 对一个锁的解锁,happens-before于随后对这个锁的加锁。
volatile变量规则: 对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
传递性: 如果A happens-before B,且B happens-before C,那么A happens-before C。
注意:
两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行,happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。
happens-before与JMM的关系如图所示:

如图所示,一个happens-before规则对应于一个或多个编译器和处理器重排序规则。
重排序
重排序指的是:编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分为下列3种类型:
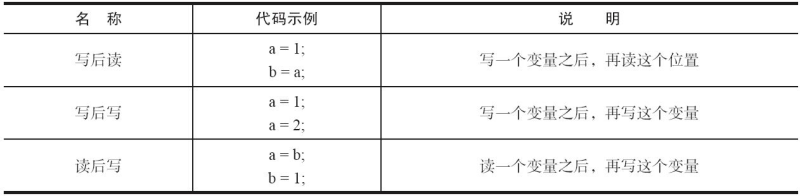
上面情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。而编译器和处理器可能会对操作做重排序,但是编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意:
这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial语义
as-if-serial语义的意思是:不管怎么重排序,单线程程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。所以编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
下面还是以书中的实例(计算圆的面积)进行说明:
double pi = 3.14; // Adouble r = 1.0; // Bdouble area = pi * r * r; // C
上面3个操作的数据依赖关系如图所示:

A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(因为C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
该程序的两种可能执行顺序:

as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。
程序顺序规则
根据happens-before的程序顺序规则,上面计算圆的面积的示例代码存在3个happens-before关系。
1) A happens-before B。
2) B happens-before C。
3) A happens-before C。
而这里的第3个happens-before关系,是根据happens-before的传递性推导出来的。
注意:
这里A happens-before B,但实际执行时B却可以排在A之前执行,JMM并不要求A一定要在B之前执行。JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见,而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens-before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法,JMM允许这种重排序。
重排序对多线程的影响
重排序是否会改变多线程程序的执行结果?还是借用书中的一个例子:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
flag变量是个标记,用来标识变量a是否已被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入呢?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
当操作1和操作2重排序时,可能会产生什么效果?(虚箭线标识错误的读操作,用实箭线标识正确的读操作。)

如图所示,操作1和操作2做了重排序。程序执行时,线程A首先写标记变量flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时,变量a还没有被线程A写入,在这里多线程程序的语义被重排序破坏了!
当操作3和操作4重排序时会产生什么效果。下面是操作3和操作4重排序后,程序执行的时序图:

在程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲的硬件缓存中。当操作3的条件判断为真时,就把该计算结果写入变量i中。猜测执行实质上对操作3和4做了重排序,在这里重排序破坏了多线程程序的语义!
注意:
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果。
在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
参考
《Java并发编程的艺术》
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
volatile与happens-before的关系与内存一致性错误
volatile变量 volatile是Java的关键词,我们可以用它来修饰变量或者方法. 为什么要使用volatile volatile的典型用法是,当多个线程共享变量,且我们要避免由于内存缓冲变量导致的内存一致性(Memory Consistency Errors)错误时. 考虑以下的生产者消费者例子,在一个时刻我们生产或消费一个单位. public class ProducerConsumer { private String value = ""; private boolea
-

深入浅出了解happens-before原则
看Java内存模型(JMM, Java Memory Model)时,总有一个困惑.关于线程.主存(main memory).工作内存(working memory),我都能找到实际映射的硬件:线程可能对应着一个内核线程,主存对应着内存,而工作内存则涵盖了写缓冲区.缓存(cache).寄存器等一系列为了提高数据存取效率的暂存区域.但是,一提到happens-before原则,就让人有点"丈二和尚摸不着头脑".这个涵盖了整个JMM中可见性原则的规则,究竟如何理解,把我个人一些理解记录下来
-
简单易懂讲解happens-before原则
在接下来的叙述里我首先会说明happens-before规则是干什么用的,然后用一个简单的小程序说明happens-before规则 一.happens-before规则 我们编写的程序都要经过优化后(编译器和处理器会对我们的程序进行优化以提高运行效率)才会被运行,优化分为很多种,其中有一种优化叫做重排序,重排序需要遵守happens-before规则,不能说你想怎么排就怎么排,如果那样岂不是乱了套. happens-before部分规则如下: 1.程序顺序规则:一个线程中的每个操作happen
-
Java内存之happens-before和重排序
happens-before原则规则: 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作: 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作: volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作: 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C: 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作: 线程中断规则:对线程interrup
-
浅谈Java内存模型之happens-before
happens-before原则非常重要,它是判断数据是否存在竞争.线程是否安全的主要依据,依靠这个原则,我们解决在并发环境下两操作之间是否可能存在冲突的所有问题.下面我们就一个简单的例子稍微了解下happens-before : i = 1; //线程A执行 j = i ; //线程B执行 j 是否等于1呢?假定线程A的操作(i = 1)happens-before线程B的操作(j = i),那么可以确定线程B执行后j = 1 一定成立,如果他们不存在happens-be
-
深度理解Java中volatile的内存语义
volatile可见性实验 举个栗子 我这里开了两个线程,后面的线程去修改volatile变量,前面的线程不断获取volatile变量, 结果是会一致卡在死循环,控制台没有任何输出 假如将flag让volatile来进行修饰 结果是:三秒后,就不会不断打印出信息出来 注意,Thread.sleep是会刷新线程内存的,所以不要使用Thread.sleep来分别让一个线程获取两次volatile变量 volatile的特性 volatile其实相当于对变量的单词读或写操作加了锁.做了同步 由于是加了
-
C++11的右值引用的具体使用
C++11 引入了 std::move 语义.右值引用.移动构造和完美转发这些特性.由于这部分篇幅比较长,分为3篇来进行阐述. 在了解这些特性之前,我们先来引入一些问题. 一.问题导入 函数返回值是传值的时候发生几次对象构造.几次拷贝? 函数的形参是值传递的时候发生几次对象构造? 让我们先来看一段代码, // main.cpp #include <iostream> using namespace std; class A{ public: A(){ cout<<"cla
-
深入理解Java注解类型(@Annotation)
Java注解是在JDK5时引入的新特性,鉴于目前大部分框架(如spring)都使用了注解简化代码并提高编码的效率,因此掌握并深入理解注解对于一个Java工程师是来说是很有必要的事.本篇我们将通过以下几个角度来分析注解的相关知识点 理解Java注解 实际上Java注解与普通修饰符(public.static.void等)的使用方式并没有多大区别,下面的例子是常见的注解: public class AnnotationDemo { //@Test注解修饰方法A @Test public static
-
深入理解JVM之Java对象的创建、内存布局、访问定位详解
本文实例讲述了深入理解JVM之Java对象的创建.内存布局.访问定位.分享给大家供大家参考,具体如下: 对象的创建 一个简单的创建对象语句Clazz instance = new Clazz();包含的主要过程包括了类加载检查.对象分配内存.并发处理.内存空间初始化.对象设置.执行ini方法等. 主要流程如下: 1. 类加载检查 JVM遇到一条new指令时,首先检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载.解析和初始化过.如果没有,那必须先执
-
深入理解JVM垃圾回收算法
目录 一.垃圾标记阶段 1.1.引用计数法 (java没有采用) 1.2.可达性分析算法 二.对象的finalization机制 2.1.对象是否"死亡" 三.使用(MAT与JProfiler)工具分析GCRoots 3.1.获取dump文件 3.2.GC Roots分析 四.垃圾清除阶段 4.1.标记-清除算法 4.2.复制算法 4.3.标记-压缩(整理,Mark-Compact)算法 4.4.以上三种垃圾回收算法对比 4.5.分代收集算法 4.6.增量收集算法 4.7.分区算法G1
-
深入理解JVM自动内存管理
目录 一.前言 1.1 计算机==>操作系统==>JVM 1.1.1 虚拟与实体(对上图的结构层次分析) 1.1.2 Java程序执行(对上图的箭头流程分析) 二.JVM内存空间与参数设置 2.1 运行时数据区 2.2 关于StackOverflowError和OutOfMemoryError 2.2.1 StackOverflowError 2.2.2 OutOfMemoryError 2.3 JVM堆内存和非堆内存 2.3.1 堆内存和非堆内存 2.3.2 JVM堆内部构型(新生代和老年代
-
深入理解Java虚拟机之经典垃圾收集器
目录 1. 综述 1. 总述: 2. 图示总述 3. 应用中应如何做出选择? 2. Serial收集器 1. 简介 2. 图解工作过程 3.使用的垃圾收集算法 4. 优点 5. 缺点 6. 主要应用场景 3. ParNew收集器 1. 简介 2. 图解工作过程 3. 使用的垃圾收集算法 4. 补充概念 5. 主要应用场景 4. Parallel Scavenge收集器 1. 简介 2. 补充概念 3. 图解工作过程 4. 使用的垃圾收集算法 5. 相关的参数 5. Serial Old收集器 1
-
Git的简单理解及基础操作命令详解
git和svn有什么区别呢? git采用分布式版本库管理,而svn采用集中式版本库管理. 集中式版本库管理需要有一台存放版本库的服务器,开发人员在开发的时候分别从服务器拉取过来最新版本,然后创建/进入分支进行开发,开发完成之后将分支提交或者合并到主分支. 分布式版本库管理允许开发者们将版本库搬到自己的电脑上,在开发过程中,开发者们可以根据不同的目的创建分支和修改代码,开发完成后进行各项合并,这样做提高了开发的敏捷性和速度,并且减少了公共服务器的压力,且任意两个开发者之间的冲突更容易得到解决. g
-
angular2 ng2 @input和@output理解及示例
angular2 @input和@output理解 先做个比方,然后奉上代码 比如: <talk-cmp [talk]="someExp" (rate)="eventHandler($event.rating)"> input, [talk]="someExp" 这个标签可以理解为一个专门的监听器,监听父组件传递过来的someExp参数,并存入自身组件的talk变:好像是开了个后门,允许且只允许父组件的someExp进入,一旦进入立刻
-
javascript深入理解js闭包
一.变量的作用域 要理解闭包,首先必须理解Javascript特殊的变量作用域. 变量的作用域无非就是两种:全局变量和局部变量. Javascript语言的特殊之处,就在于函数内部可以直接读取全局变量. Js代码 var n=999; function f1(){ alert(n); } f1(); // 999 另一方面,在函数外部自然无法读取函数内的局部变量. Js代码 function f1(){ var n=999; } alert(n); // error 这里有一个地方需要注意,函数