selenium获取当前页面的url、源码、title的方法
此篇博客学习的api如标题,分别是:
current_url 获取当前页面的url;
page_source 获取当前页面的源码;
title 获取当前页面的title;
将以上方法按顺序练习一遍,效果如GIF:
from selenium import webdriver
from time import sleep
sleep(2)
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 移动浏览器观看展示
driver.set_window_size(width=500, height=500, windowHandle="current")
driver.set_window_position(x=1000, y=100, windowHandle='current')
sleep(2)
# 获取当前页面title并断言
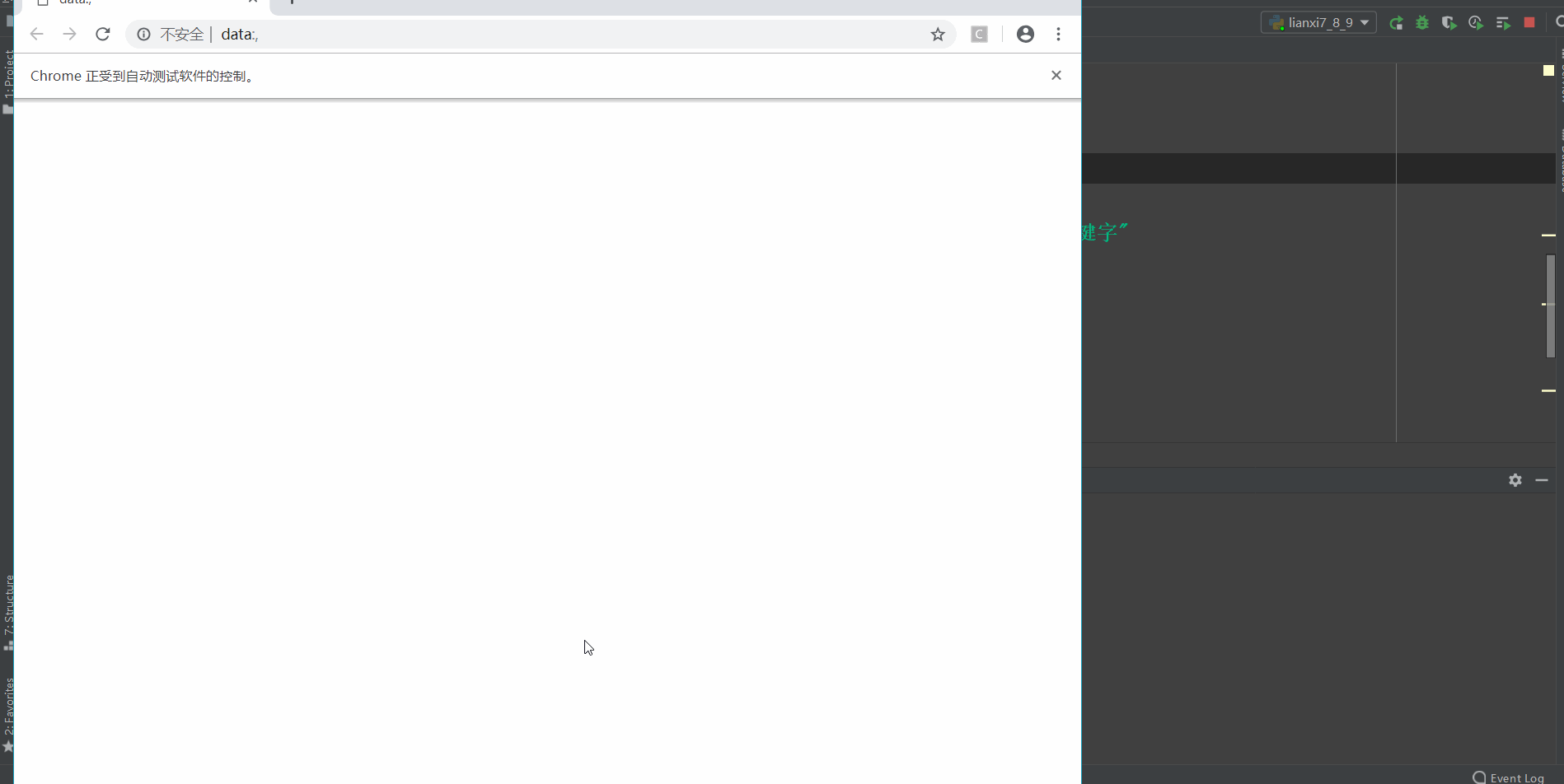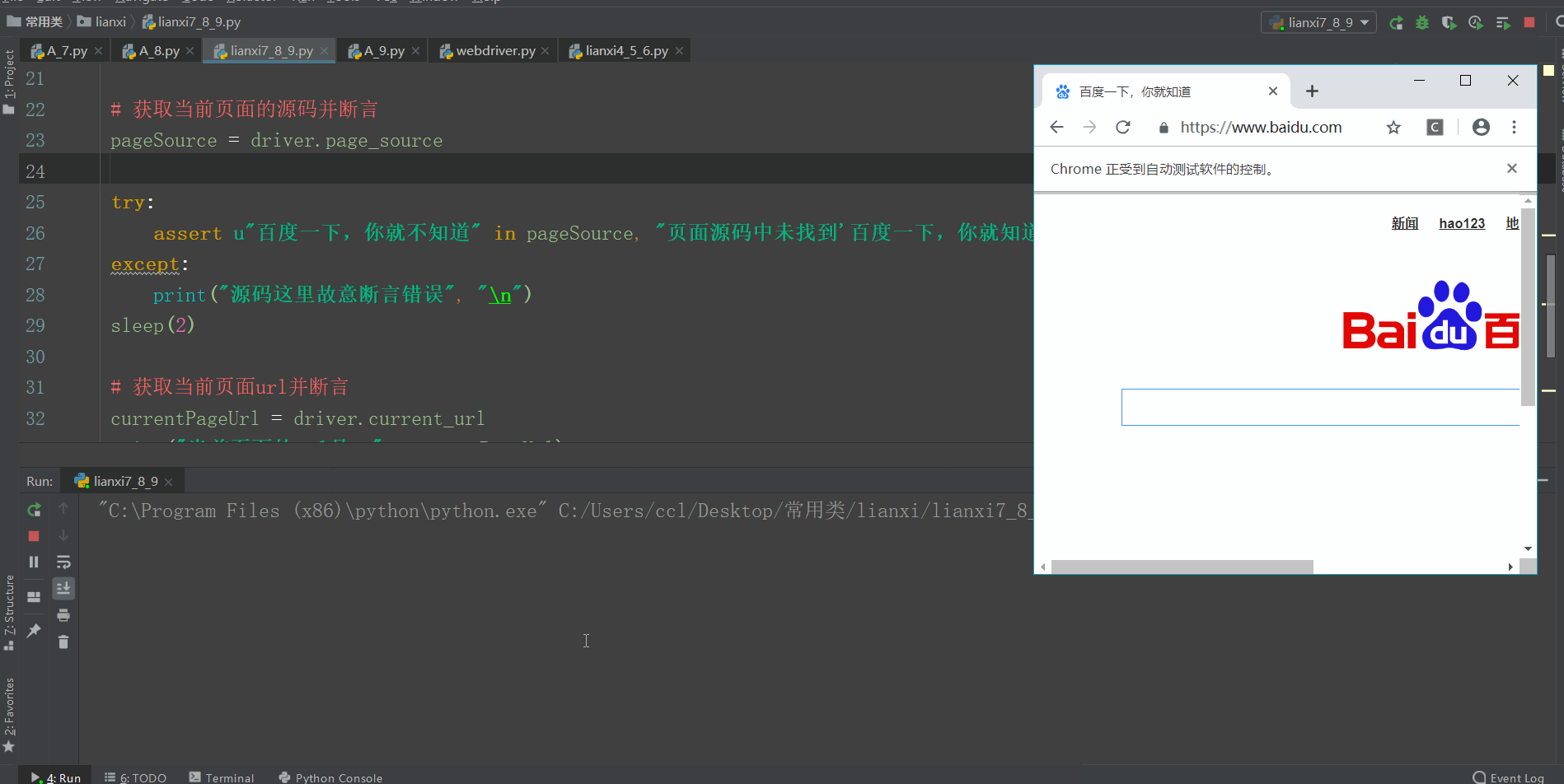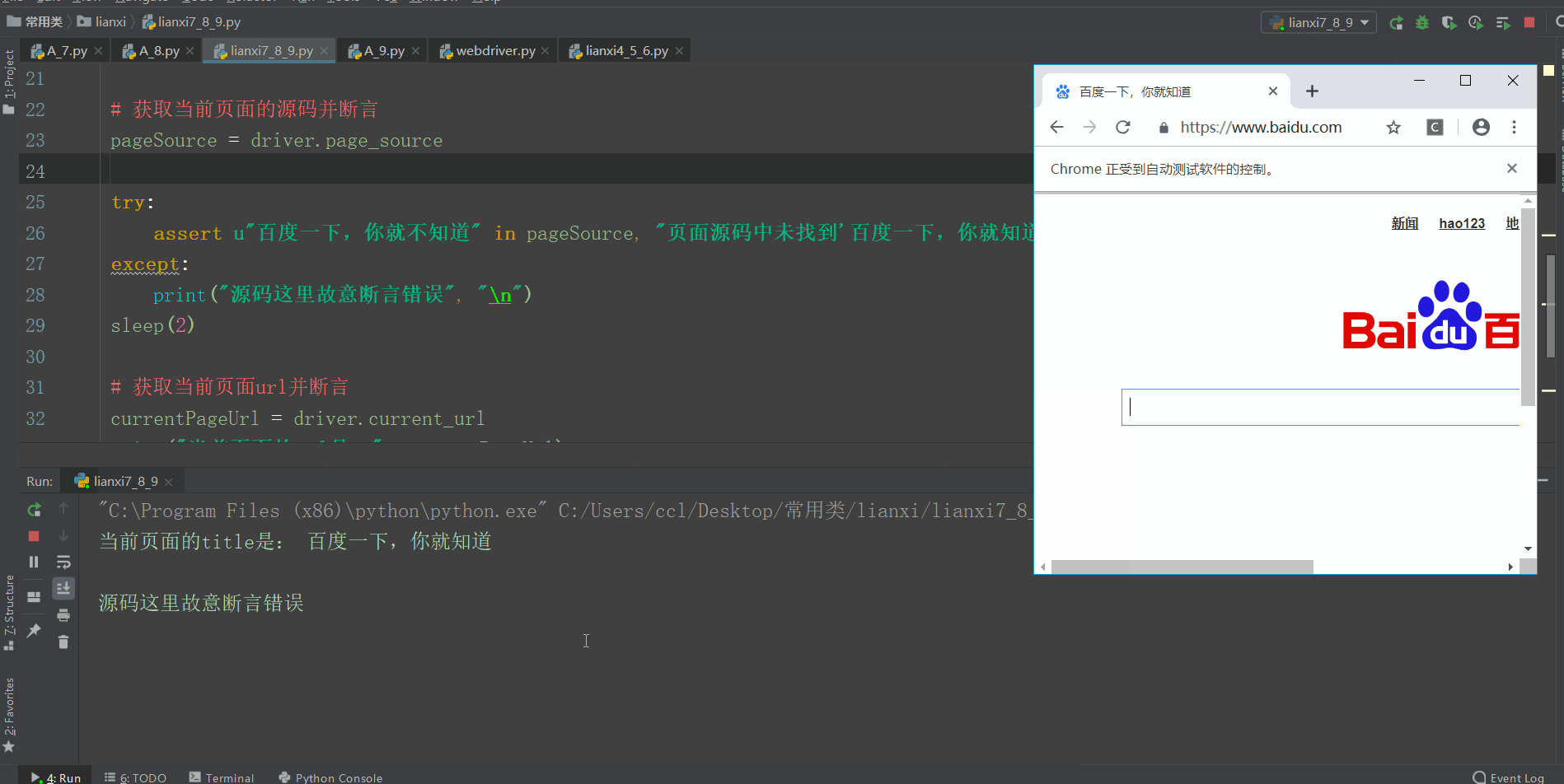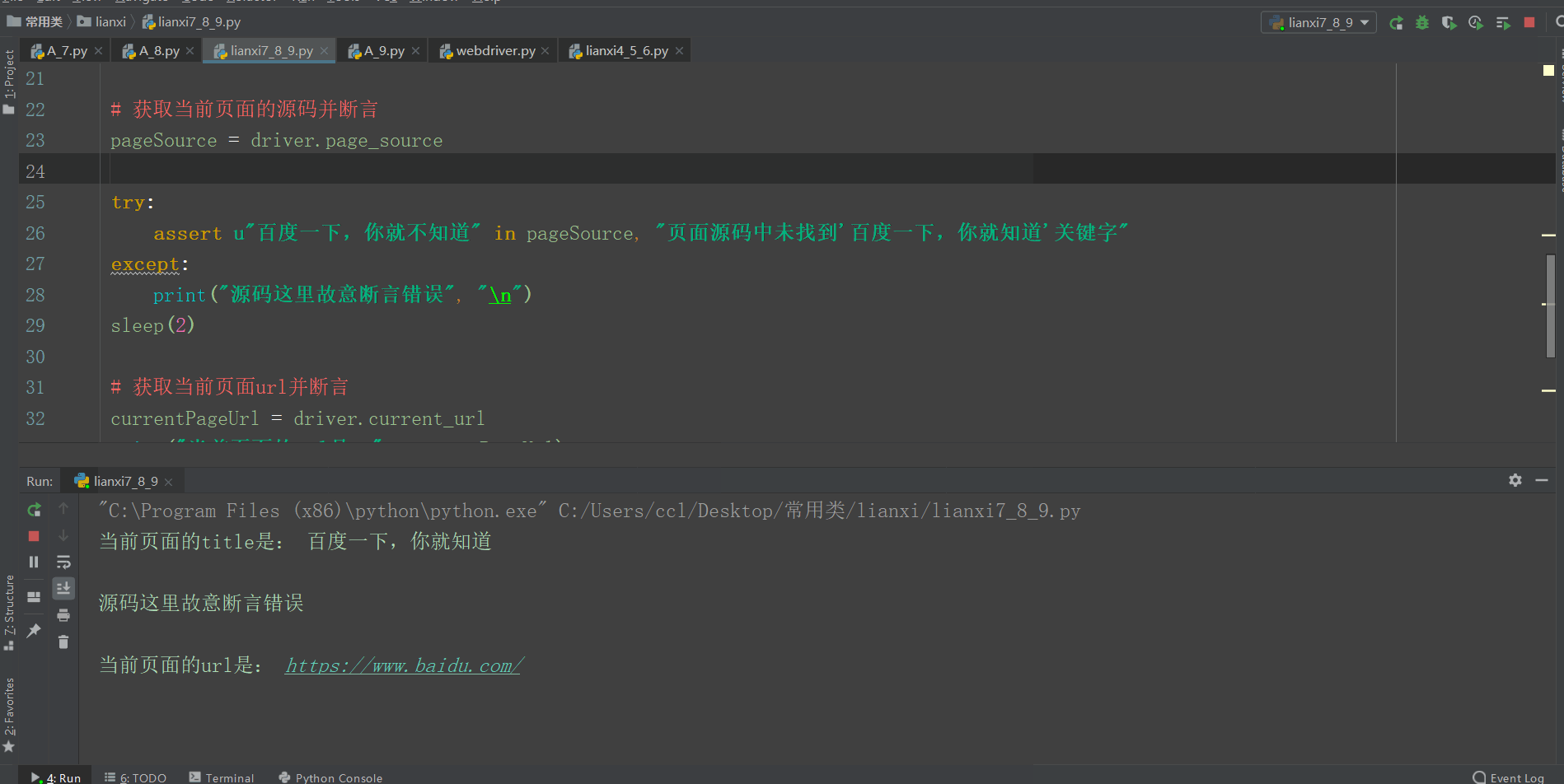
title = driver.title
print("当前页面的title是:", title, "\n")
assert title==u"百度一下,你就知道","页面title属性值错误!"
sleep(2)
# 获取当前页面的源码并断言
pageSource = driver.page_source
try:
assert u"百度一下,你就不知道" in pageSource, "页面源码中未找到'百度一下,你就知道'关键字"
except:
print("源码这里故意断言错误", "\n")
sleep(2)
# 获取当前页面url并断言
currentPageUrl = driver.current_url
print("当前页面的url是:", currentPageUrl)
assert currentPageUrl == "https://www.baidu.com/", "当前网页网址非预期!"
sleep(2)
driver.quit()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
基于selenium 获取新页面元素失败的解决方法
当我们使用selenium 实现模拟登陆时,获取到登陆按钮元素后,直接调用它的click()方法就能实现登陆跳转,并且此时的webDriver 也是指向 当前页面,这个是没问题的,不过需要注意的是因为页面加载速度一般小于程序运行速度,所以在获取登陆后页面的元素之前,可以用WebDriverWait的util方法解决,也可以直接通过Thread.sleep()让程序睡眠一会(不推荐). 但是博主要说的重点是如果我们是通过点击普通超链接进入到新页面,那么通过上面的方法是获取不到新页面元素的,因为此时
-
selenium获取当前页面的url、源码、title的方法
此篇博客学习的api如标题,分别是: current_url 获取当前页面的url: page_source 获取当前页面的源码: title 获取当前页面的title: 将以上方法按顺序练习一遍,效果如GIF: from selenium import webdriver from time import sleep sleep(2) driver = webdriver.Chrome() driver.get("https://www.baidu.com/") # 移动浏览器观看展
-
C#获取当前页面的URL示例代码
本实例的测试URL:http://www.mystudy.cn/web/index.aspx 1.通过C#获取当前页面的URL 复制代码 代码如下: string url = Request.Url.AbsoluteUri; //结果: http://www.mystudy.cn/web/index.aspx string host = Request.Url.Host; //结果:www.mystudy.cn string rawUrl = Request.RawUrl; //结果:/web/
-
在asp.net中获取当前页面的URL的方法(推荐)
获取Url的方法有两种,通过后台获得或通过前面js获得,如下: 1.通过C#获取当前页面的URL string url = Request.Url.AbsoluteUri; //结果: http://www.jb51.net/web/index.aspx string host = Request.Url.Host; //结果:www.jb51.net string rawUrl = Request.RawUrl; //结果:/web/index.aspx string localPath =
-
js获取当前页面的url网址信息
1.设置或获取整个 URL 为字符串: window.location.href 2.设置或获取与 URL 关联的端口号码: window.location.port 3.设置或获取 URL 的协议部分 window.location.protocol 4.设置或获取 href 属性中跟在问号后面的部分 window.location.search 5.获取变量的值(截取等号后面的部分) 复制代码 代码如下: var url = window.location.search; // alert(
-
python+selenium打印当前页面的titl和url方法
dr.title //获取页面title dr.current_url // 获取页面url 代码如下: from selenium import webdriver dr = webdriver.Firefox() url = 'http://www.baidu.com' dr.get(url) # 获取页面title title = dr.title # 获取页面url url = dr.current_url print title print url dr.quit() 以上这篇pyth
-
Android源码解析onResume方法中获取不到View宽高
目录 前言 问题1.为什么onCreate和onResume中获取不到view的宽高? 问题2.为什么View.post为什么可以获取View宽高? 结论 前言 有一个经典的问题,我们在Activity的onCreate中可以获取View的宽高吗?onResume中呢? 对于这类八股问题,只要看过都能很容易得出答案:不能. 紧跟着追问一个,那为什么View.post为什么可以获取View宽高? 今天来看看这些问题,到底为何? 今日份问题: 为什么onCreate和onResume中获取不到vie
-

js获取当前页的URL与window.location.href简单方法
利用JavaScript获取当前页的URL,这个问题起来好像很复杂,如果第一次去想这个问题,很多人估计又在琢磨到底又是哪个神一般的Javascript函数. 其实不是,Javascript获取当前页的URL的函数就是我们经常用来重定向的window.location.href. 比如如下函数: <script> var url=window.location.href; var loc = url.substring(url.lastIndexOf('/')+1, url.length); a
-
c# 从IE浏览器获取当前页面的内容
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPoi
-
多种语言下获取当前页完整URL及其参数
PHP如何获取当前页完整URL及其参数 <? echo 'http://'.$_SERVER['SERVER_NAME'].':'.$_SERVER["SERVER_PORT"].$_SERVER["REQUEST_URI"]."<br>"; echo $_SERVER['SERVER_NAME']."<br>";// cike.org echo $_SERVER["SERVER_PO
-
Android 用Time和Calendar获取系统当前时间源码分享(年月日时分秒周几)
概述 用Time和Calendar获取系统当前时间(年月日时分秒周几) 效果图 源码: import android.app.Activity; import android.os.Bundle; import android.text.format.Time; import android.view.View; import android.widget.RelativeLayout; import android.widget.TextView; import java.util.Calen