python 递归深度优先搜索与广度优先搜索算法模拟实现

一、递归原理小案例分析
(1)# 概述
递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到!
(2)# 写递归的过程
1、写出临界条件
2、找出这一次和上一次关系
3、假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果
(3)案例分析:求1+2+3+...+n的数和
# 概述
'''
递归:即一个函数调用了自身,即实现了递归
凡是循环能做到的事,递归一般都能做到!
'''
# 写递归的过程
'''
1、写出临界条件
2、找出这一次和上一次关系
3、假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果
'''
# 问题:输入一个大于1 的数,求1+2+3+....
def sum(n):
if n==1:
return 1
else:
return n+sum(n-1)
n=input("请输入:")
print("输出的和是:",sum(int(n)))
'''
输出:
请输入:4
输出的和是: 10
'''

#__author:"吉*佳"
#date: 2018/10/21 0021
#function:
import os
def getAllDir(path):
fileList = os.listdir(path)
print(fileList)
for fileName in fileList:
fileAbsPath = os.path.join(path,fileName)
if os.path.isdir(fileAbsPath):
print("$$目录$$:",fileName)
getAllDir(fileAbsPath)
else:
print("**普通文件!**",fileName)
# print(fileList)
pass
getAllDir("G:\\")
输出结果如下:


二、深度遍历与广度遍历
(一)、深度优先搜索
说明:深度优先搜索借助栈结构来进行模拟
深度遍历示意图:
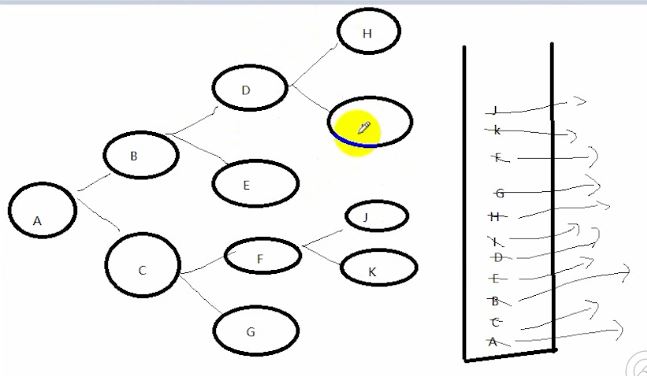
说明:
先把A压栈进去,在A出栈的同时把B C压栈进去,此时让B出栈的同时把DE压栈(C留着先不处理) 同理,在D出栈的时候,H I压栈,最后再从上往下
取出栈内还未出栈的元素,即达到深度优先遍历。
案例实践:利用栈来深度搜索打印出目录结构
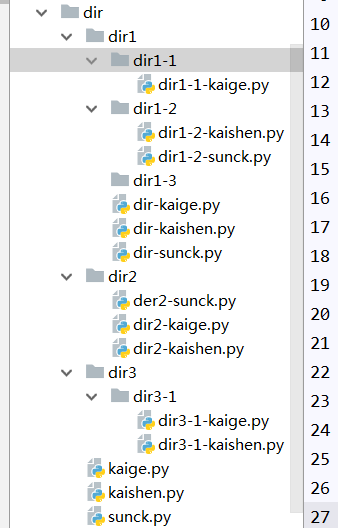
程序代码:
#__author:"吉**"
#date: 2018/10/21 0021
#function:
# 深度优先遍历目录层级结构
import os
def getAllDirDP(path):
stack = []
# 压栈操作,相当于图中的A压入
stack.append(path)
# 处理栈,当栈为空的时候结束循环
while len(stack) != 0:
#从栈里取数据,相当于取出A,取出A的同时把BC压入
dirPath = stack.pop()
firstList = os.listdir(dirPath)
#判断:是目录压栈,把该目录地址压栈,不是目录即是普通文件,打印
for filename in firstList:
fileAbsPath=os.path.join(dirPath,filename)
if os.path.isdir(fileAbsPath):
#是目录就压栈
print("目录:",filename)
stack.append(fileAbsPath)
else:
#是普通文件就打印即可,不压栈
print("普通文件:",filename)
getAllDirDP(r'E:\[AAA](千)全栈学习python\18-10-21\day7\temp\dir')
结果:
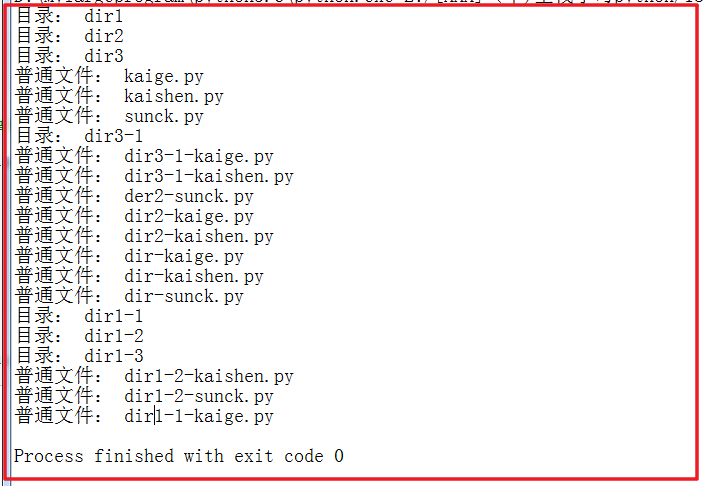
该过程示意图解释:(s-05-1部分)
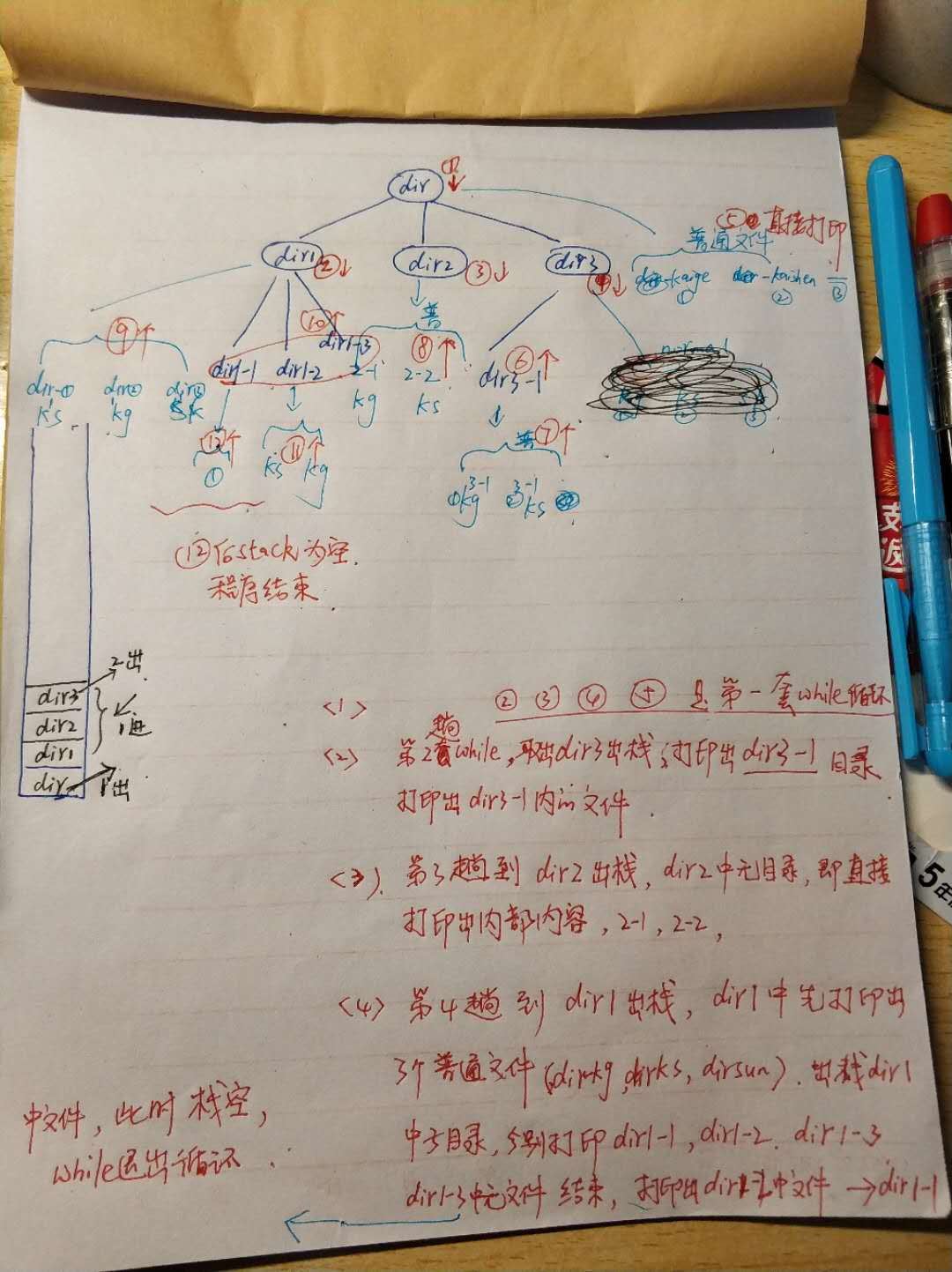

原理分析:
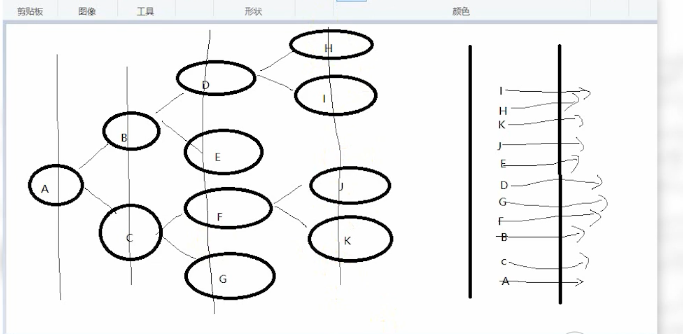
说明:
队列是 先进先出的模型。A先进队,在A出队的时候,C B入队,按图示,C出队,FG 入队,B出队,DE入队,
F出队,JK入队,G出队,无入队,D出队,H I入队,最后E J K H I出队,均无入队了,即每一层一层处理、
故:先进先出的队列结构实现了广度优先遍历。 先进后出的栈结构实现的是深度优先遍历。
代码实现:
其实深度优先和广度优先在代码书写上是差别不大的,基本相同,只是一个是使用栈结构(用列表进行模拟)
另一个(广度优先遍历)是使用了队列的数据结构来达到先进先出的目的。
#__author:"吉**"
#date: 2018/10/21 0021
#function:
# 广度优先搜索模拟
# 利用队列来模拟广度优先搜索
import os
import collections
def getAllDirIT(path):
queue=collections.deque()
#进队
queue.append(path)
#循环,当队列为空,停止循环
while len(queue) != 0:
#出队数据 这里相当于找到A元素的绝对路径
dirPath = queue.popleft()
# 找出跟目录下的所有的子目录信息,或者是跟目录下的文件信息
dirList = os.listdir(dirPath)
#遍历该文件夹下的其他信息
for filename in dirList:
#绝对路径
dirAbsPath = os.path.join(dirPath,filename)
# 判断:如果是目录dir入队操作,如果不是dir打印出即可
if os.path.isdir(dirAbsPath):
print("目录:"+filename)
queue.append(dirAbsPath)
else:
print("普通文件:"+filename)
# 函数的调用
getAllDirIT(r'E:\[AAA](千)全栈学习python\18-10-21\day7\temp\dir')
广度优先运行输出结构:

先图解:按照每一层从左到右遍历即可实现。
总结
以上所述是小编给大家介绍的python 递归深度优先搜索与广度优先搜索算法模拟实现 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

python实现树的深度优先遍历与广度优先遍历详解
本文实例讲述了python实现树的深度优先遍历与广度优先遍历.分享给大家供大家参考,具体如下: 广度优先(层次遍历) 从树的root开始,从上到下从左到右遍历整个树的节点 数和二叉树的区别就是,二叉树只有左右两个节点 广度优先 顺序:A - B - C - D - E - F - G - H - I 代码实现 def breadth_travel(self, root): """利用队列实现树的层次遍历""" if root == None: r
-
10分钟教你用python动画演示深度优先算法搜寻逃出迷宫的路径
深度优先算法(DFS 算法)是什么? 寻找起始节点与目标节点之间路径的算法,常用于搜索逃出迷宫的路径.主要思想是,从入口开始,依次搜寻周围可能的节点坐标,但不会重复经过同一个节点,且不能通过障碍节点.如果走到某个节点发现无路可走,那么就会回退到上一个节点,重新选择其他路径.直到找到出口,或者退到起点再也无路可走,游戏结束.当然,深度优先算法,只要查找到一条行得通的路径,就会停止搜索:也就是说只要有路可走,深度优先算法就不会回退到上一步. 如果你依然在编程的世界里迷茫,可以加入我们的Python学
-
python实现广度优先搜索过程解析
广度优先搜索 适用范围: 无权重的图,与深度优先搜索相比,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快 复杂度: 时间复杂度为O(V+E),V为顶点数,E为边数 思路 广度优先搜索是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索: 代码 from collections import deque #解决从你的人际关系网中找到芒果销售商的问题 #使用字典表示映射关系 graph = {} graph["you"] = ["alice&quo
-
python图的深度优先和广度优先算法实例分析
本文实例讲述了python图的深度优先和广度优先算法.分享给大家供大家参考,具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为"回溯点". 深度优先算法: (1)访问初始顶点v并标记顶点v已访问. (2)查找顶点v的第一个邻接顶点w. (3)若顶点v的邻接顶点w存在,则继续执行:否则回溯到v,
-
python广度优先搜索得到两点间最短路径
前言 之前一直写不出来,这周周日花了一下午终于弄懂了, 顺便放博客里,方便以后忘记了再看看. 要实现的是输入一张 图,起点,终点,输出起点和终点之间的最短路径. 广度优先搜索 适用范围: 无权重的图,与深度优先搜索相比,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快 复杂度: 时间复杂度为O(V+E),V为顶点数,E为边数 思路 广度优先搜索是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索: 比如下图: 从0结点开始搜索的话,一开始是0.将0加入队列中: 然后
-
python深度优先搜索和广度优先搜索
1. 深度优先搜索介绍 图的深度优先搜索(Depth First Search),和树的先序遍历比较类似. 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到. 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止. 显然,深度优先搜索是一个递归的过程. 2. 广度优先搜索介绍 广度优先搜索算法(Breadt
-
Python深度优先算法生成迷宫
本文实例为大家分享了Python深度优先算法生成迷宫,供大家参考,具体内容如下 import random #warning: x and y confusing sx = 10 sy = 10 dfs = [[0 for col in range(sx)] for row in range(sy)] maze = [[' ' for col in range(2*sx+1)] for row in range(2*sy+1)] #1:up 2:down 3:left 4:right opera
-
Python数据结构与算法之图的广度优先与深度优先搜索算法示例
本文实例讲述了Python数据结构与算法之图的广度优先与深度优先搜索算法.分享给大家供大家参考,具体如下: 根据维基百科的伪代码实现: 广度优先BFS: 使用队列,集合 标记初始结点已被发现,放入队列 每次循环从队列弹出一个结点 将该节点的所有相连结点放入队列,并标记已被发现 通过队列,将迷宫路口所有的门打开,从一个门进去继续打开里面的门,然后返回前一个门处 """ procedure BFS(G,v) is let Q be a queue Q.enqueue(v) lab
-
python数据结构之图深度优先和广度优先实例详解
本文实例讲述了python数据结构之图深度优先和广度优先用法.分享给大家供大家参考.具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为"回溯点". 深度优先算法: (1)访问初始顶点v并标记顶点v已访问. (2)查找顶点v的第一个邻接顶点w. (3)若顶点v的邻接顶点w存在,则继续执行:否则回
-
python 递归深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件 2.找出这一次和上一次关系 3.假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果 (3)案例分析:求1+2+3+...+n的数和 # 概述 ''' 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! ''' # 写递归的过程 ''' 1.写出临界条件 2.找出这一次和上一次关系 3.假设
-
Java编程实现基于图的深度优先搜索和广度优先搜索完整代码
为了解15puzzle问题,了解了一下深度优先搜索和广度优先搜索.先来讨论一下深度优先搜索(DFS),深度优先的目的就是优先搜索距离起始顶点最远的那些路径,而广度优先搜索则是先搜索距离起始顶点最近的那些路径.我想着深度优先搜索和回溯有什么区别呢?百度一下,说回溯是深搜的一种,区别在于回溯不保留搜索树.那么广度优先搜索(BFS)呢?它有哪些应用呢?答:最短路径,分酒问题,八数码问题等.言归正传,这里笔者用java简单实现了一下广搜和深搜.其中深搜是用图+栈实现的,广搜使用图+队列实现的,代码如下:
-
python实现全排列代码(回溯、深度优先搜索)
从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列.当m=n时所有的排列情况叫全排列. 公式:全排列数f(n)=n!(定义0!=1) 1 递归实现全排列(回溯思想) 1.1 思想 举个例子,比如你要对a,b,c三个字符进行全排列,那么它的全排列有abc,acb,bac,bca,cba,cab这六种可能就是当指针指向第一个元素a时,它可以是其本身a(即和自己进行交换),还可以和b,c进行交换,故有3种可能,当第一个元素a确定以后,指针移向第二
-
C++深度优先搜索的实现方法
本文实例讲述了图的遍历中深度优先搜索的C++实现方法,是一种非常重要的算法,具体实现方法如下: 首先,图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次且仅访问一次.注意到树是一种特殊的图,所以树的遍历实际上也可以看作是一种特殊的图的遍历.图的遍历主要有两种算法:广度优先搜索(Breadth-First-Search)和深度优先搜索(Depth-First-Search). 一.深度优先搜索(DFS)的算法思想 深度优先搜索算法所遵循的搜索策略是尽可能"深&
-
最短时间学会基于C++实现DFS深度优先搜索
目录 前言 1.迷宫找出口,区分dfs,bfs: 一.DFS经典放牌可能组合 二.leetcode 员工的重要性 三.leetcode 图像渲染 四.leetcode 被围绕的区域 五.岛屿数量 六. 小练习:岛屿的最大面积 总结 前言 同学们肯定或多或少的听到过别人提起过DFS,BFS,却一直都不太了解是什么,其实两个各为搜索算法,常见使用 深度优先搜索(DFS) 以及 广度优先搜索(BFS) ,今天我们就来讲讲什么是深度优先搜索,深度优先就是撞到了南墙才知道回头,才会往上一层返回. 1.迷宫
-
C语言使用广度优先搜索算法解决迷宫问题(队列)
本文实例讲述了C语言使用广度优先搜索算法解决迷宫问题.分享给大家供大家参考,具体如下: 变量 head 和 tail 是队头和队尾指针, head 总是指向队头, tail 总是指向队尾的下一个元素.每个点的 predecessor 成员也是一个指针,指向它的前趋在 queue 数组中的位置.如下图所示: 广度优先是一种步步为营的策略,每次都从各个方向探索一步,将前线推进一步,图中的虚线就表示这个前线,队列中的元素总是由前线的点组成的,可见正是队列先进先出的性质使这个算法具有了广度优先的特点.广
-
python数据结构之搜索讲解
目录 1. 普通搜索 2. 顺序搜索 1.1 无序下的顺序查找 1.2 有序下的顺序查找 2.二分查找 3.散列查找 3.1 几种散列函数 3.2 处理散列表冲突 3.3 散列表的实现(加1重复) 4.参考资料 往期学习: python数据类型: python数据结构:数据类型. python的输入输出: python数据结构之输入输出及控制和异常. python面向对象: python数据结构面向对象. python算法分析: python数据结构之算法分析. python栈.队列和双端队列:
-
PHP实现广度优先搜索算法(BFS,Broad First Search)详解
本文实例讲述了PHP实现广度优先搜索算法.分享给大家供大家参考,具体如下: 广度优先搜索的算法思想 Breadth-FirstTraversal 广度优先遍历是连通图的一种遍历策略.因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较广的区域,故得名. 广度优先搜索遍历类似于树的按层次遍历.对于无向连通图,广度优先搜索是从图的某个顶点v0出发,在访问v0之后,依次搜索访问v0的各个未被访问过的邻接点w1,w2,-.然后顺序搜索访问w1的各未被访问过的邻接点,w2的各未被访问过的邻接点,-.